
By Lance Martin
Context
LLM ops platforms, such as LangChain, make it easy to assemble LLM components (e.g., models, document retrievers, data loaders) into chains. Question-Answering is one of the most popular applications of these chains. But it is often not always obvious to determine what parameters (e.g., chunk size) or components (e.g., model choice, VectorDB) yield the best QA performance.
Here, we introduce a simple tool for evaluating QA chains (see the code here) called auto-evaluator
- Ask the user to input a set of documents of interest
- Use an LLM (
GPT-3.5-turbo) to auto-generatequestion-answerpairs from these docs - Generate a question-answering chain with a specified set of UI-chosen configurations
- Use the chain to generate a response to each
question - Use an LLM (
GPT-3.5-turbo) to score the response relative to theanswer - Explore scoring across various chain configurations
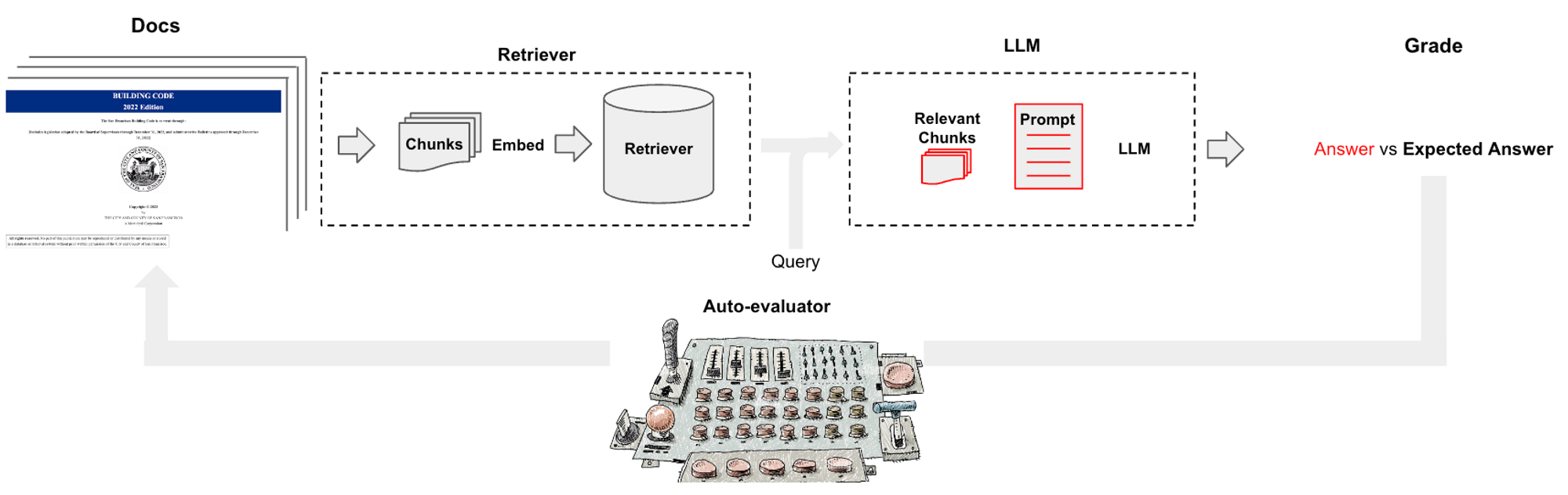
User Inputs
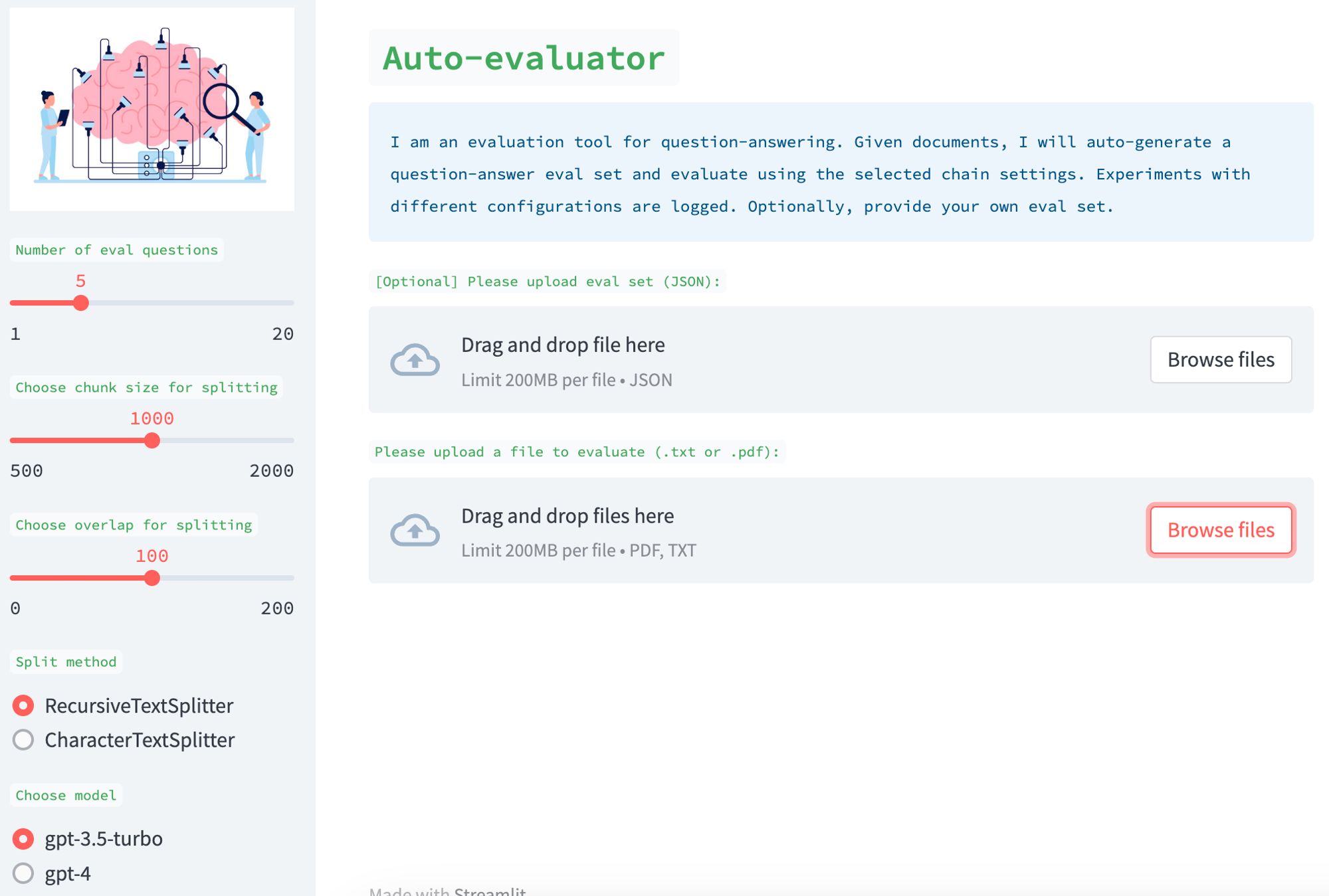
This is implemented as a Streamlit app where a user can supply a set of documents. Optionally, the user can also supply a corresponding set of question-answer pairs (see example here). If the user does not supply this, the app with auto-generate an eval set using QAGenerationChain. You can see the prompt used for this here, which selects question-answer pairs from random chunks for the input.
Chain
The UI has various knobs that can be used to create a QA chain. For example, you can pick from newer document retrievers (e.g., an SVM) or you can use similarity search on a vectorstore. You can select various document split methods, split sizes, and split overlap. You can also select the LLM used for final summarization of the answer to the question from the retrieved docs. These different pieces can be quickly and easily assembled using Langchain into a chain for evaluation.
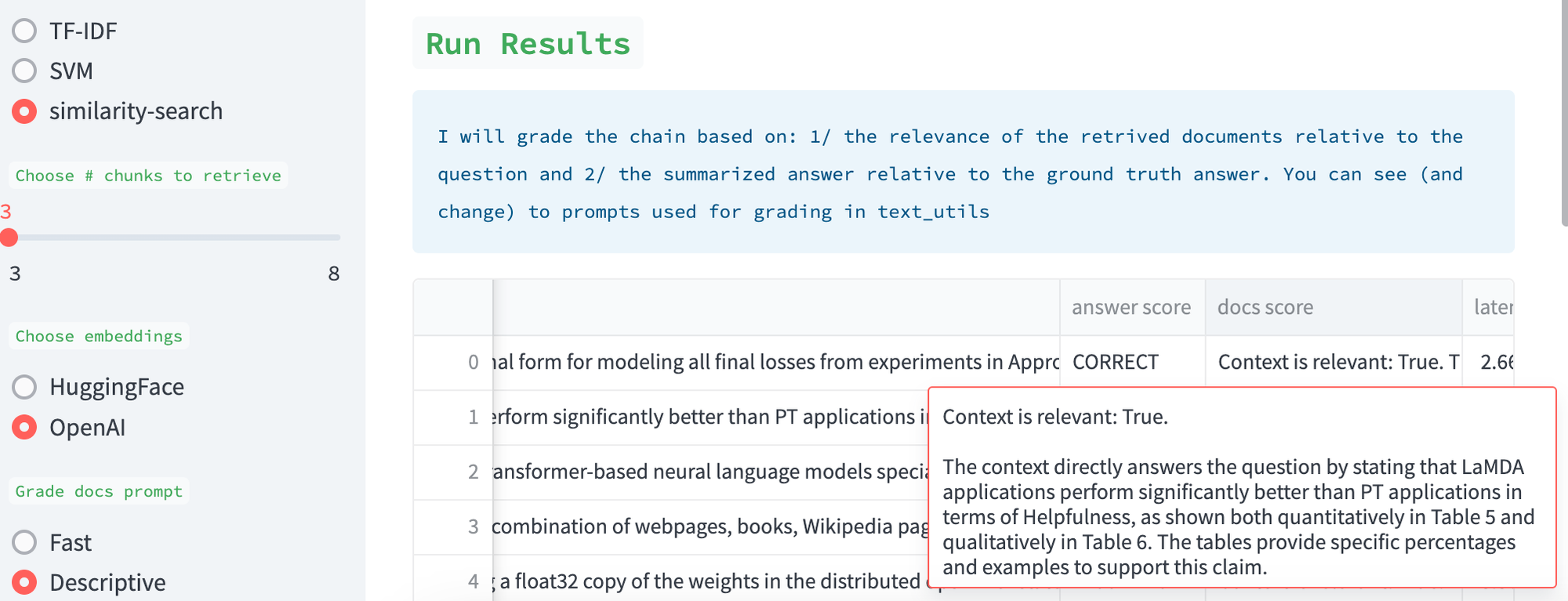
Scoring
We use an LLM (GPT-3.5-turbo) to score the quality of the retrieved docs, which is an idea inspired by discussion with Jerry Liu at LLama-Index (here). We also use an LLM to score the quality of the answers relative to the evaluation set. In both cases, we expose the prompts. Users can easily engineer them. We also expose the results for human inspection; the Descriptive prompt can be used to ask the LLM grader for a detailed explanation of its assessment.
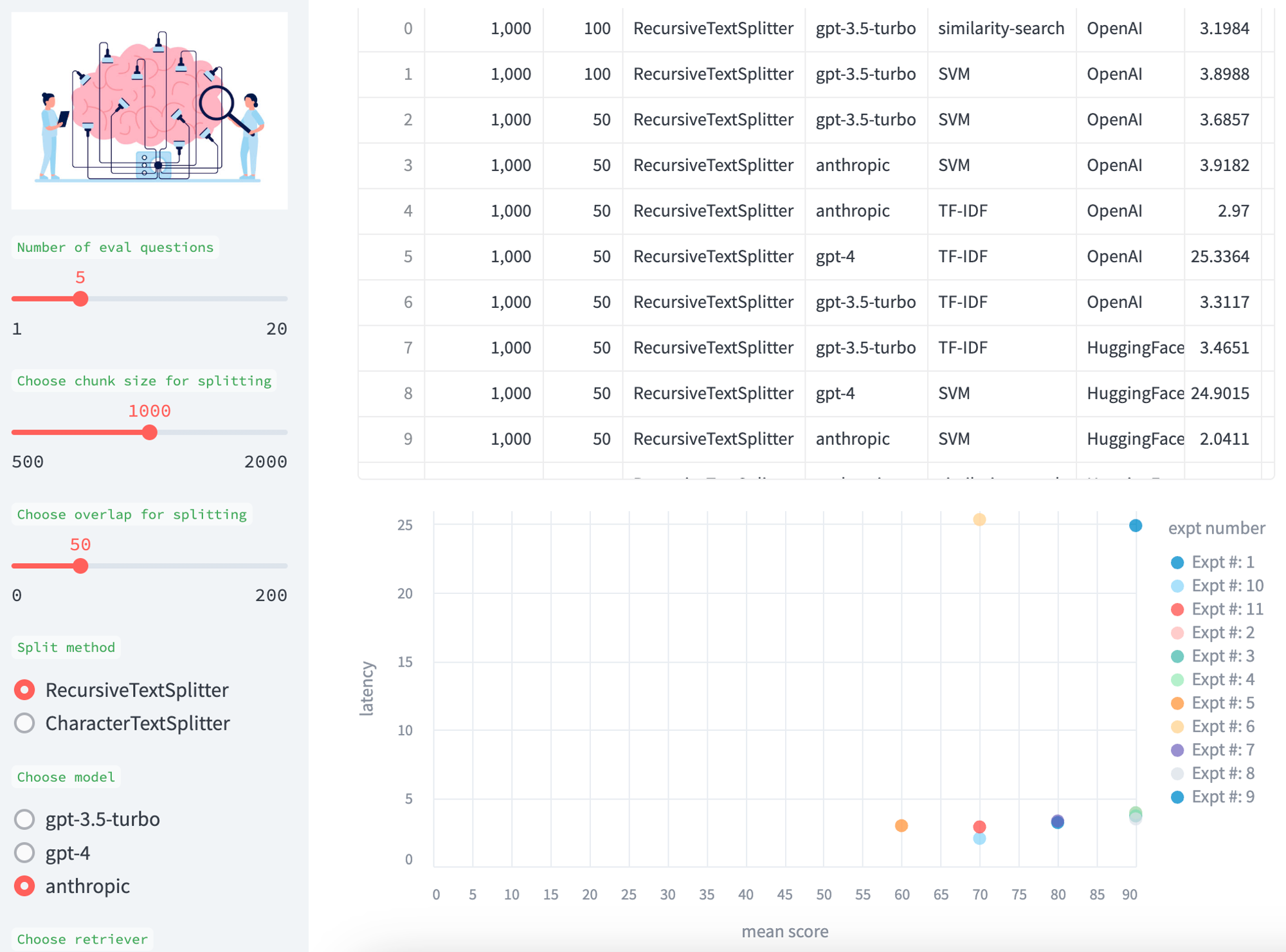
Comparison
We accumulate experimental results for easy comparison across the various tests, with a table and a scatter plot of the mean score (answer and retrieval) versus the model latency (in sec).
Future directions
Feedback and contributions are welcome; for example, we would like to include other retrievers (such as LLama-Index) and other models (e.g., various HuggingFace models). We’d like to improve the performance (e.g., in particular, the latency) of various stages in the eval process and offer this as a free hosted tool (since some users will not have access to GPT-4 or Claude today). Finally, we’d like to extend this to other tasks (e.g., chat) and automate the process of best chain assembly (e.g., using agents) given a user-specified objective (e.g., chat or QA goals).