
Retrieval Architectures
LLM question answering (Q+A) typically involves retrieval of documents relevant to the question followed by synthesis of the retrieved chunks into an answer by an LLM. In practice, the retrieval step is necessary because the LLM context window is limited relative to the size of most text corpus of interest (e.g., LLM context windows range from ~2k-4k tokens for many models and up 8k-32k for GPT4). Anthropic recently released a Claude model with a 100k token context window. With the advent of models with larger context windows, it is reasonable to wonder whether the document retrieval stage is necessary for many Q+A or chat use-cases.
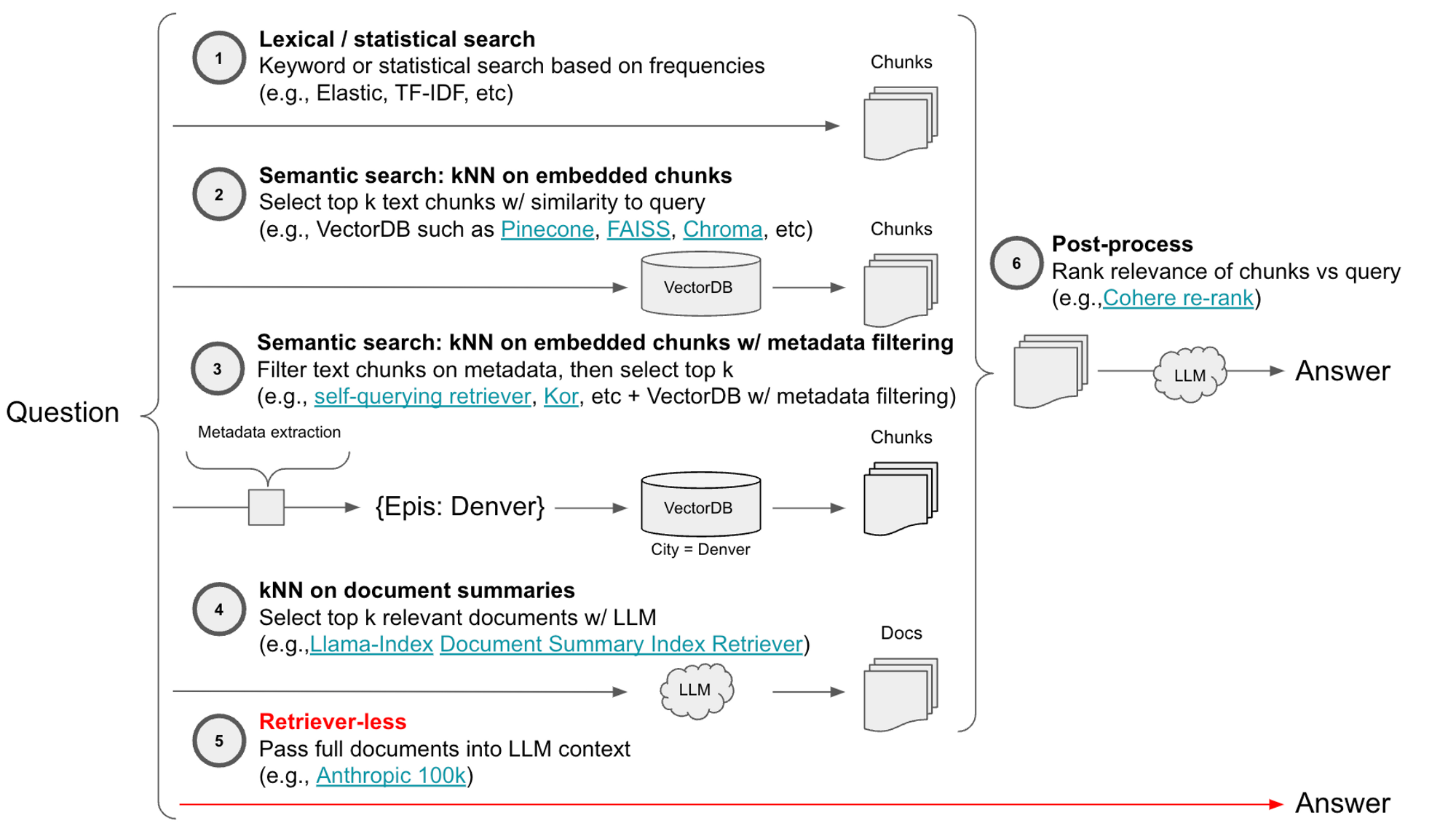
Here’s a taxonomy of retriever architectures with this retriever-less option highlighted:
- Lexical / Statistical: TF-IDF, Elastic, etc
- Semantic: Pinecone, Chroma, etc
- Semantic with metadata filtering: Pinecone, etc with filtering tools (self-querying, kor, etc)
- kNN on document summaries: Llama-Index, etc
- Post-processing: Cohere re-rank, etc
- Retriever-less: Anthropic 100k context window, etc
Evaluation strategy
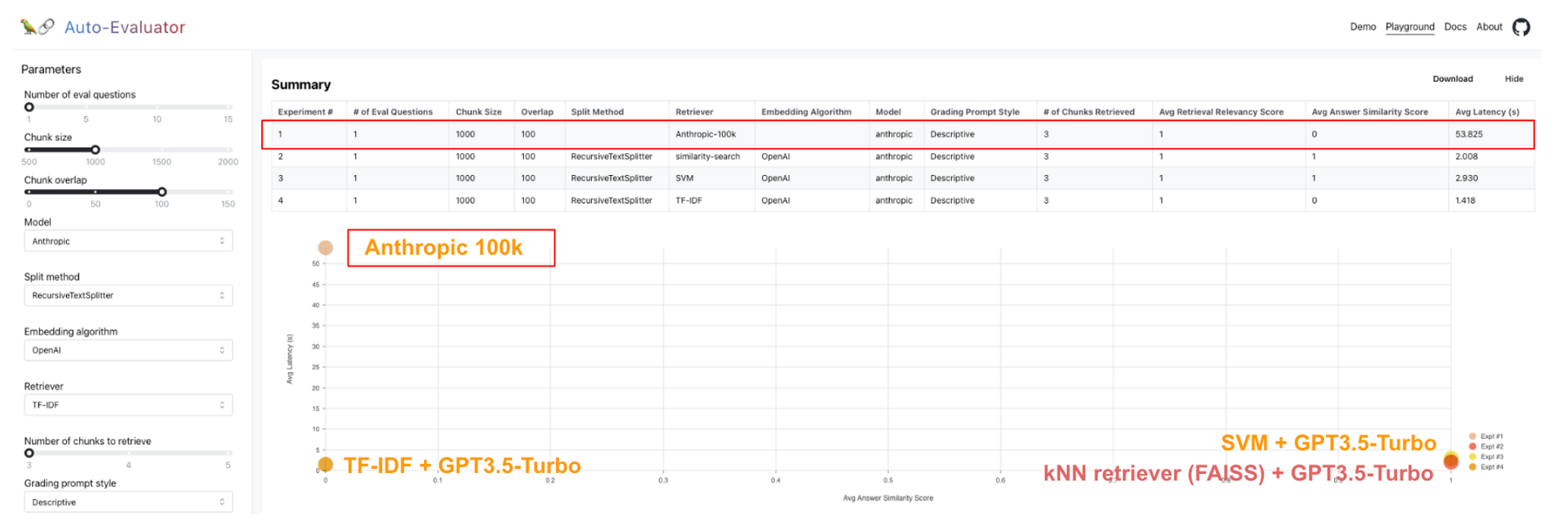
We previously introduced auto-evaluator, a hosted app and open-source repo for grading LLM question-answer chains. This provides an good testing ground for comparing Anthropic 100k for Q+A against other retrieval methods, such as kNN on a VectorDB, SVMs, etc.
Results
On a test set of 5 questions for the 75 page GPT3 paper (here), we see that the Anthropic 100k model performs as well as kNN (FAISS) + GPT3.5-Turbo. Of course, this is impressive because the full pdf doc is simply passed to Anthropic 100k directly in the prompt. But, we can also see that this comes at the cost of latency (e.g., ~50s for Anthropic 100k vs < ~10s for others).

We also tested on a 51 page PDF of building codes for San Francisco and asked a specific permitting question that has been used in prior evals. Here we see Anthropic 100k fall short of SVM and kNN retrievers; see the detailed results here. Anthropic 100k produces a more verbose and close-to-correct answer (stating that a permit is required for a backyard shed > 120 sqft whereas the correct answer is > 100 sqft). One drawback of retriever-less architectures is that we cannot inspect the retrieved chunks to debug why model yielded the incorrect answer.
Testing for yourself
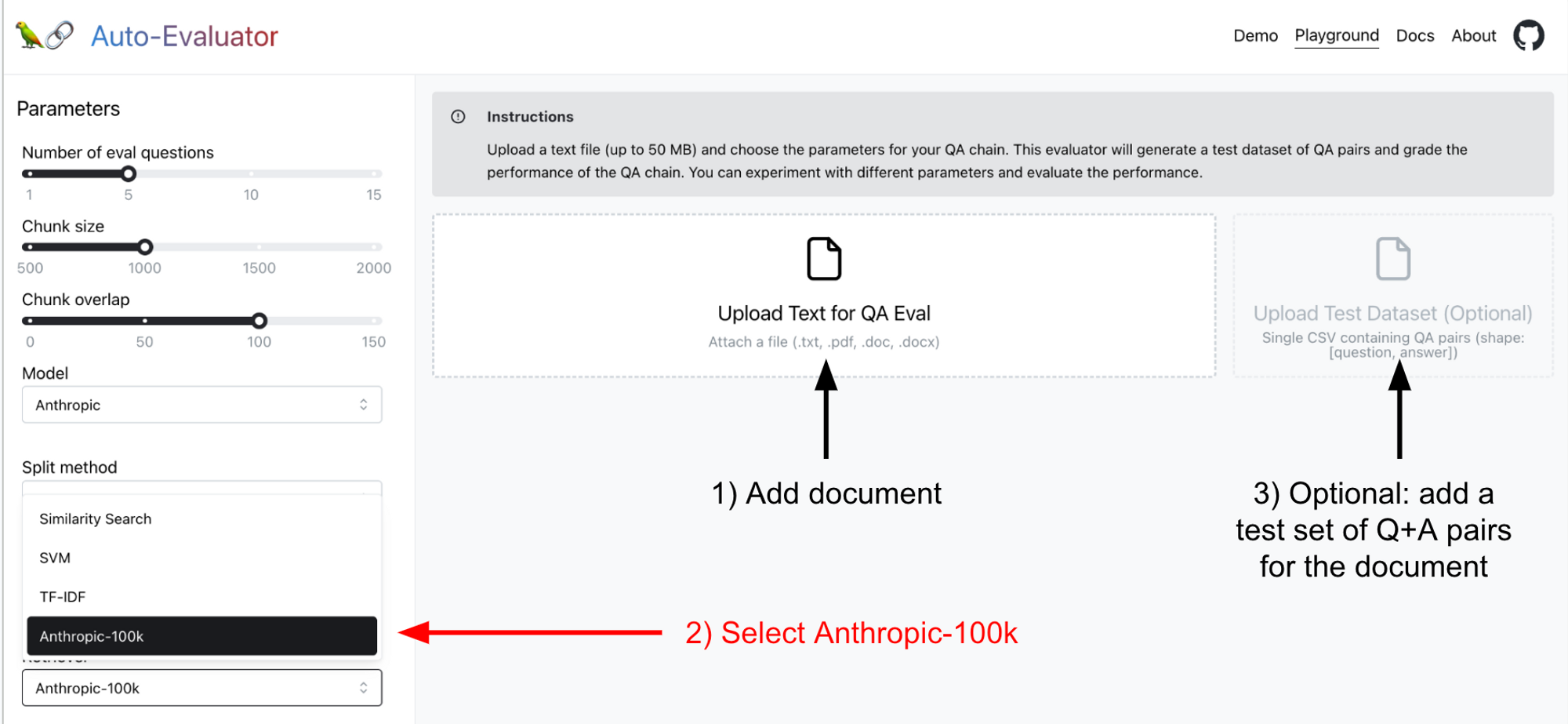
We have deployed Anthropic 100k in our hosted app, so you can try it for yourself and benchmark it relative to other approaches. See our README for more details, but in short:
- Add a document of interest
- Select
Anthropic-100kretriever - Optionally, add your own test set (the app will auto-generate one if you do not supply it)
Conclusion
The retriever-less architecture is compelling due to its simplicity and promising performance on a few challenges that we have tried. Of course, there are a few caveats: 1) it has higher latency than retriever-based approaches and 2) many (e.g., production) applications will have a corpus that is still far larger than the 100k token context window. For applications where latency is not critical and corpus is reasonably small (Q+A over a small set of docs), retriever-less approaches have appeal, especially as the context window of LLMs grows and the models get faster.