
TL;DR: There have been several emerging trends in LLM applications over the past few months: RAG, chat interfaces, agents. Our newest functionality - conversational retrieval agents - combines them all. This isn't just a case of combining a lot of buzzwords - it provides real benefits and superior user experience.
Key Links:
As LLM applications are starting to make their way into more and more production use cases, a few common trends are starting emerge:
Retrieval Augmented Generation
LLMs only know what they are trained on. To combat this, a style of generation known as "retrieval augmented generation" has emerged. In this technique, documents are retrieved and then inserted into the prompt, and the language model is instructed to only respond based on those documents. This helps both in giving the language model additional context as well as in keeping it grounded.
Chat Interfaces
With the explosion of ChatGPT, chat interfaces have emerged as the dominant way with which to interact with language models. The ability to ask follow up questions about a previous response - especially as context windows grow longer and longer - proves invaluable.
Agents
The term agents may be overloaded by now. By "agents" we mean a system where the sequence of steps is NOT known ahead of time, but is rather determined by a language model. This can allow the system greater flexibility in dealing with edge cases. However, if unbounded it can become quite unreliable.
At LangChain, we have had components for these trends from the very beginning. One of our first applications built was a RetrievalQA system over a Notion database. We've experimented and pushed the boundary with many different forms of memory, enabling chatbots of all kinds. And - of course - we've got many types of agents, from the "old" ones that use ReAct style prompting, to newer ones powered by OpenAI Functions.
We've also combined these ideas before. ConversationalRetrievalQA - a chatbot that does a retrieval step to start - is one of our most popular chains. From almost the beginning we've added support for memory in agents.
Yet we've never really put all three of these concepts together. Until now. With our conversational retrieval agents we capture all three aspects. Let's dive into what exactly this consists of, and why this is the superior retrieval system.
The basic outline of this system involves:
- An OpenAI Functions agent
- Tools that are themselves
retrievers- they take in a string, and return a list of documents - A new type of memory that not only remembers
human <-> aiinteractions, but alsoai <-> toolinteractions
The agent can then decide when to call the retrieval system if at all. If it does, the retrieved documents are returned and it can use them to reason about what to do next, whether it be respond directly or do a different retrieval step. Note that this relies upon a few things:
- Longer context windows: if context windows are short, then you can't just return all the documents into the agent's working memory
- Better language models: if language models aren't good enough to reason about when they should retrieve documents, then this won't work
Luckily, language models are getting better and getting longer context windows!
Here's a LangSmith trace showing how it looks in action:
https://smith.langchain.com/public/1e2b1887-ca44-4210-913b-a69c1b8a8e7e/r
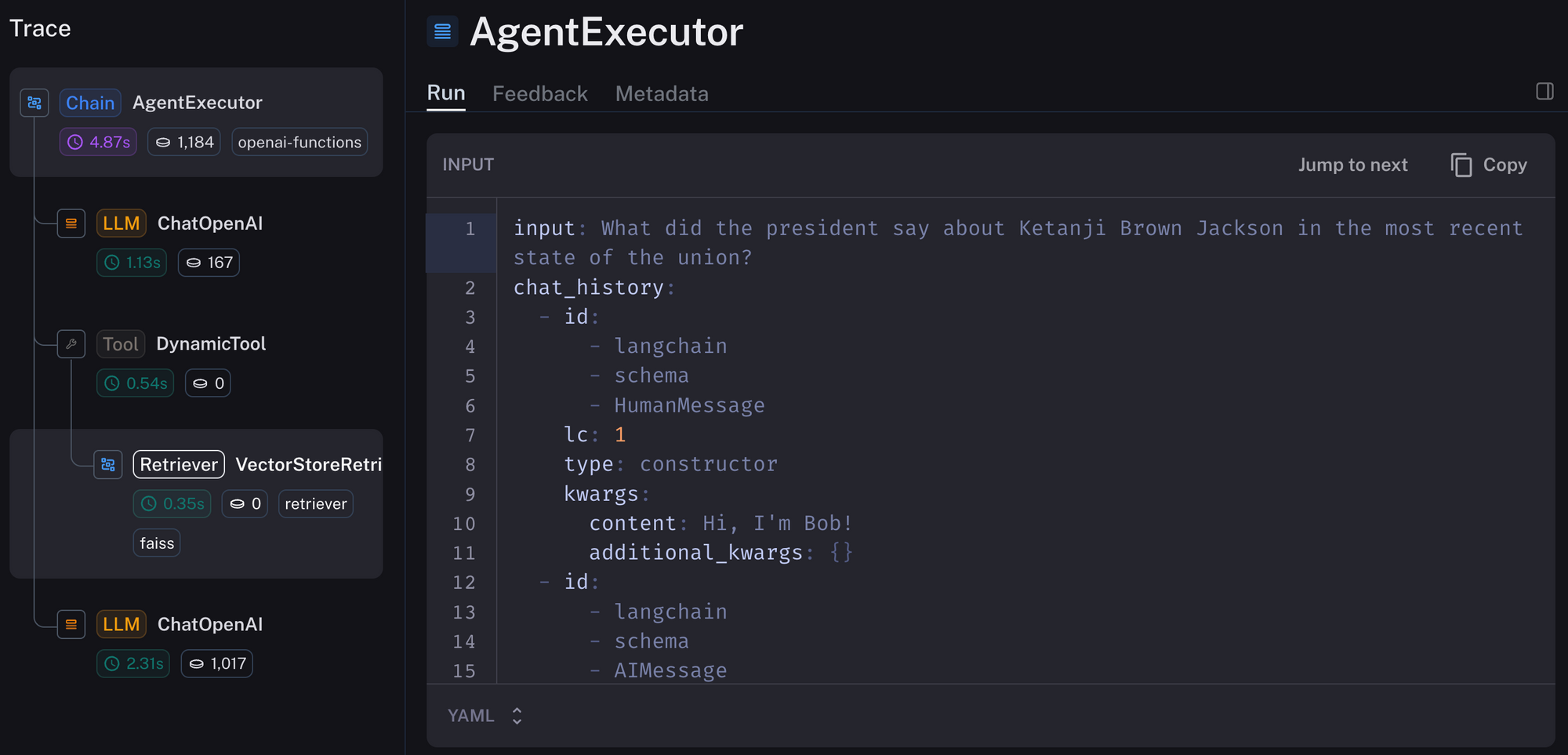
Let's compare this to the ConversationalRetrievalQA chain that most people use. The benefits that a conversational retrieval agent has are:
- Doesn't always look up documents in the retrieval system. Sometimes, this isn't needed! If the user is just saying "hi", you shouldn't have to look things up
- Can do multiple retrieval steps. In
ConversationalRetrievalQA, one retrieval step is done ahead of time. If that retrieval step returns bad results, then you're out of luck! But with an agent you can try a different search query to see if that yields better results - With this new type of memory, you can maybe avoid retrieval steps! This is because it remembers
ai <-> toolinteractions, and therefore remembers previous retrieval results. If a follow-up question the user asks can be answered by those, there's no need to do another retrieval step! - Better support for meta-questions about the conversation - "how many questions have I asked?", etc. Because the old chain dereferences questions to be "standalone" and independent of the conversation history in order to query the vector store effectively, it struggles with this type of question.
Note, that there are some downsides/dangers:
- With agents, they can occasionally spiral out of control. That's why we've added controls to our AgentExecutor to cap them at a certain max amount of steps. It's also worth noting that this is a VERY focused agent, in that it's only given one tool (and a pretty simple tool at that). In general, the fewer (and simpler) tools an agent is given, the more likely it is to be reliable.
- By remembering
ai <-> toolinteractions, that can hog the context window occasionally. That's why we've included a flag to disable that type of memory, and more generally have made memory pretty plug-and-play.
This new agent is in both Python and JS - you can use these guides to get started:
LLM applications are rapidly evolving. Our NotionQA demo was one of the first we did - and although it was only ~9 months ago the best practices have shifted dramatically since then. This currently represents our best guess at what a GenAI question-answering system should look like, combining the grounded-ness of RAG with the UX of chat and the flexibility of agents.
We've got a few more ideas on how this can be further improved - we'll be rolling those out over the next few weeks. As always, we'd love to hear from you with any suggestions or ideas.