In traditional ML and data science, perhaps the first thing you do is think about data. You need to build data sets (i.e. training/validation/test sets) before even thinking about training and evaluating a model. Only after these steps do you integrate the model into your application to see how it performs.
With generative AI, you can easily get started with general purpose LLMs, allowing you to quickly develop a prototype and plug it into your application. But, this doesn’t mean you can skip the initial steps of data collection and validation.
When building LLM apps, a common building pattern is:
- First get a prototype up and running and plug it into your application
- Then build a dataset for evaluation purposes to track your progress and make sure you don’t introduce any regressions
- Then use that dataset to improve the underlying model (either by few-shot prompting or fine-tuning)
So data is still incredibly important - but the way you think about data is different for LLM apps. Here are some changes we have noticed when building LLM apps:
- Initial versions of datasets are often much smaller - sometimes only 5-10 datapoints
- Datasets rapidly evolve - both in the number of rows they have as well as their schema
- Individual datapoints are more frequently added to datasets, usually from seeing a bad performing point in production
These changes mean that the best developer experience for managing datasets for LLM applications has different feature points and considerations. To address this, we’ve added the concept of dataset schemas to LangSmith - which interacts with other LangSmith features to streamline data curation and management.
Iterate quickly with flexible dataset schemas
In LangSmith, you can now define a schema for your dataset, and all new datapoints added will then be validated against this schema. Although this seems basic, this is subtly useful for a few reasons.
First, having your data follow a defined schema makes it easier to use and consume. You often want to use all datapoints within a dataset in the same way (whether for evaluation or as few shot examples). If they have a different schema, then your code for processing or formatting the data could break.
Defining a schema is also crucial when building datasets iteratively. While you might remember the schema when curating a dataset all at once, it can be easy to forget the details when adding new data points later. This makes schema consistency extra important in iterative dataset building.
At the same time, flexibility in schema support is also necessary, especially in LLM applications where the ideal schema may not be clear at the start of development. You may not know any part of the schema. You might only know the schema for a subset of inputs, or have no schema at all. LangSmith dataset schemas support all of this, allowing you to define datasets without any schema or with partial schemas.
It’s important to be able to modify dataset schemas, as the ideal schema may evolve over time (again, due to the iterative nature of dataset curation). LangSmith lets you easily update schemas, presenting a queue of datapoints that no longer fit the desired schema, which can be fixed in the UI. This keeps your dataset consistent and up-to-date.
For a deeper technical dive into how to use dataset schemas, view the developer documentation here.
Enhance datasets with schema validation, versioning, and annotation
Dataset schemas enhance existing LangSmith features that help you manage your datasets for LLM applications.
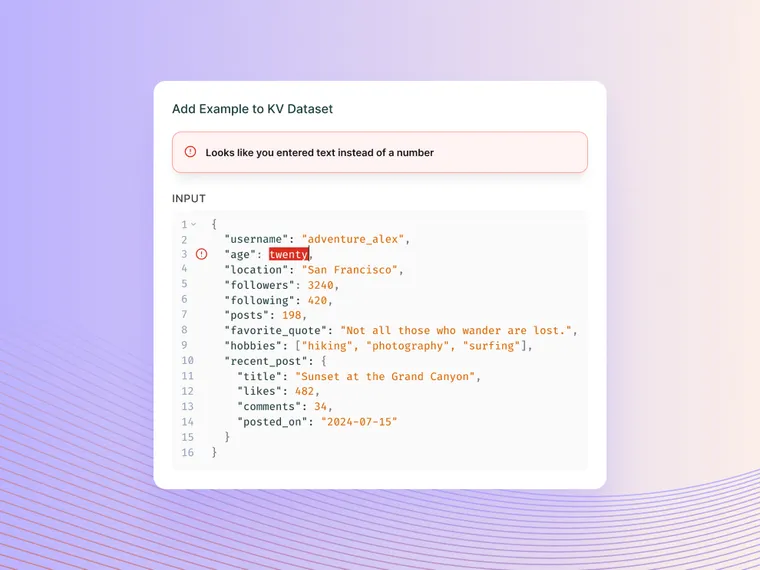
When adding data from production logs to datasets, the schema will now get validated upon your attempt and LangSmith raises a helpful error message if it does not comply. Production logs often contain extra info or different keys, which can cause datasets to become messy - so this auto-validation helps keep your dataset clean.
If you update your schema, you’ll want to have versioning to preserve historical context. LangSmith supports versioning natively for datasets; see the docs for how new versions of a dataset can be created.
Oftentimes, there are dedicated subject-matter experts (either technical and non-technical) responsible for reviewing data. It should be as easy as possible for these users to view data and add it to an existing dataset. We’ve added annotation queues to LangSmith which provide a streamlined process for users to review runs and attach feedback.
Future updates will build on these features in LangSmith, continuing to improve the experience of develop datasets for your LLM applications. For example, if a schema is known, it’s easier to generate additional synthetic examples and improve use cases for datasets - not only with testing, but finetuning and few-shot prompting to improve your LLM app performance.
Conclusion
Curating datasets is incredibly important for building both traditional ML and LLM applications. Yet, for LLM applications, the way dataset curation is done and how data is used is different. LangSmith offers a comprehensive suite of tools for managing your LLM datasets. The ability to define dataset schemas ensures consistency, so that you can flexibly utilize data and iterate faster as new examples are added to your dataset.
To dive deeper, check out our documentation on dataset schemas. You can try out LangSmith today for robust experimentation and evaluation, with support for prompt versioning, debugging, and human annotations — so you can gain production observability as you build your LLM apps.