
Editor's Note: This post was written in collaboration with the Epsilla team. As more apps rely on Retrieval Augmented Generation (RAG) for building personalized applications on top of proprietary data, vector databases are becoming even more important. We're really excited about what Epsilla is doing here to help builders quickly and accurately fetch the most relevant documents and data points.
By leveraging the strengths of both LLMs and vector databases, this integration promises richer, more accurate, and context-aware answers.
The landscape of artificial intelligence is ever-evolving. As developers and businesses seek more effective ways to utilize Large Language Models (LLMs), integration tools like LangChain are paving the way. In this post, we'll explore Epsilla's recent integration with LangChain and how it revolutionizes the question-answering domain.
Retrieval Augmented Generation (RAG) in LLM-Powered Question-Answering Pipelines
Since October 2022, there has been a huge surge in the adoption and utilization of ChatGPT and other Large Language Models (LLMs). These advanced models have emerged as frontrunners in the realm of artificial intelligence, offering unprecedented capabilities in generating human-like text and understanding nuanced queries. However, despite their prowess, ChatGPT and similar models possess inherent limitations. One of the most significant challenges is their inability to incorporate updated knowledge post their last training cut-off, rendering them unaware of events or developments that have transpired since then. Moreover, while they possess vast general knowledge, they can't access proprietary or private company data, which is often crucial for businesses looking for tailored insights or decision-making. This is where Retrieval Augmented Generation (RAG) steps in as a game-changer. RAG bridges the knowledge gap by dynamically retrieving relevant information from external sources, ensuring that the generated responses are not only factual but also up-to-date. Vector databases play an integral role in the RAG mechanism by enabling efficient and semantic retrieval of information. These databases store information as vectors, allowing RAG to quickly and accurately fetch the most relevant documents or data points based on the semantic similarity of the input query, enhancing the precision and relevance of the LLM's generated responses.
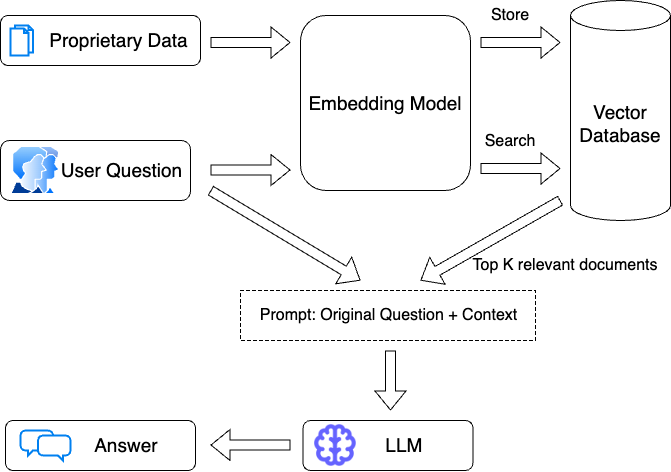
Implementing Question Answering Pipeline with LangChain and Epsilla
LangChain offers a unified interface and abstraction layer on top of LLM ecosystem components, simplifying the process of building generative AI applications. With LangChain, developers can avoid boilerplate code and focus on delivering value.
With the Epsilla integration with LangChain, now the AI application developers can easily leverage the superior performance provided by Epsilla (benchmark) while building the knowledge retrieval component in the AI applications.
Here is a step by step guide on implementing a question answering pipeline with LangChain and Epsilla.
Step 1. Install LangChain and Epsilla
pip install langchain
pip install openai
pip install tiktoken
pip install pyepsilladocker pull epsilla/vectordb
docker run --pull=always -d -p 8888:8888 epsilla/vectordbStep 2. Provide your OpenAI key
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Step 3. Prepare for knowledge and embedding model
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import WebBaseLoader
from langchain.text_splitter import CharacterTextSplitter
loader = WebBaseLoader("https://raw.githubusercontent.com/hwchase17/chat-your-data/master/state_of_the_union.txt")
documents = loader.load()
documents = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0).split_documents(documents)
embeddings = OpenAIEmbeddings()
Step 4. Vectorize the knowledge documents
from langchain.vectorstores import Epsilla
from pyepsilla import vectordb
client = vectordb.Client()
vector_store = Epsilla.from_documents(
documents,
embeddings,
client,
db_path="/tmp/mypath",
db_name="MyDB",
collection_name="MyCollection"
)Step 5. Create a RetrievalQA chain for question answering on the uploaded knowledge
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=vector_store.as_retriever())
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
Here is the response:
Conclusion
Epsilla's integration with LangChain signifies a leap forward in the domain of question-answering systems. By leveraging the strengths of both LLMs and vector databases, this integration promises richer, more accurate, and context-aware answers. As AI continues to reshape our world, tools like LangChain, coupled with powerful vector databases like Epsilla, will be at the forefront of this transformation.
For those eager to dive deeper, LangChain's source code and implementation details with Epsilla are available on Google Colab.