By Krish Maniar and William Fu-Hinthorn
If you are interested in beta-testing more prompt optimization techniques, fill out interest form here.
When we write prompts, we attempt to communicate our intent for LLMs to apply on messy data, but it's hard to effectively communicate every nuance in one go. Prompting is typically done through manual trial and error, testing and tweaking until things work better; on the other hand, tools like DSPy and promptim have shown the usefulness of prompt "programming" and systematic prompt optimization by closing the intent-instruction gap through measurement and testing on real data. In this post, we:
- Curate five different datasets with verifiable outcomes for benchmarking prompt optimization
- Implement and benchmark five different methods of systematically improving prompts
- Benchmark how well three different models (
gpt-4o,claude-sonnet,o1) do on prompt optimization
Our conclusions:
- Our recommended model for prompt optimization is
claude-sonnet(overo1) - Prompt optimization is most effective on tasks where the underlying model lacks domain knowledge
- In the above situations, prompt optimization can show a ~200% increase in accuracy over naive baseline prompts
- Prompt optimization in these situations can also be thought of as a form of long-term memory: learning to adapt directly from your data
What we tested
We benchmarked five popular prompt optimization approaches (more detailed explanations later on):
- Few-shot prompting: use training examples as demonstrations of expected behavior
- Meta-prompting: use an LLM to analyze and improve prompts
- Meta-prompting with reflection: let the LLM think and critique its analysis before committing to an updated prompt
- Prompt gradients: generate targeted improvement recommendations for each example as "text gradients" and then apply those in a separate LLM call
- Evolutionary optimization: explore prompt space through controlled mutations
We ran these across three models (O1, GPT-4, and Claude-3.5-Sonnet) on five datasets representative of common tasks, intending to answer the following primary questions:
- When does prompt optimization work best?
- Which frontier models work well for prompt optimization?
- Which algorithms are the most reliable?
Algorithms
We tested five different approaches to prompt optimization, each with its own theory of how to improve prompts:
Few-shot prompting
For the simplest tested technique, we chose up to 50 examples from the training set (sampled over a few epochs) and included them in the prompt as demonstrations of expected behavior. This is efficient to learn (since no LLM calls are required to propose changes), though it leads to higher token costs at test time (since typical demonstrations contain more content than direct single instructions).
Meta-prompting
The was the simplest instruction-tuning approach. We first ran the target LLM over the examples. We then calculated scores on the outputs. Note: this requires evaluator(s) to be set up. We then showed the meta-prompting LLM examples of inputs, outputs, reference outputs (if available), and the current prompt's scores on those outputs. Based on those variables, we then asked the LLM to write a better prompt. We repeat this process in mini-batches, periodically evaluating on a held-out development (dev) set. The prompt with the highest dev set score is retained.
Meta-prompting with reflection
We re-use the meta-prompting technique from the first step but give the LLM the option to use "think" and "critique" tools. These tools do nothing more than give the LLM an opportunity to write down thoughts in a scratchpad before committing to a particular prompt update. This helps the LLM use more test-time compute to analyze previous prompts and look for more hidden patterns in the underlying data distribution before committing to the next prompt update.
Prompt Gradients
Popularized by papers such as "Automatic Prompt Optimization" by Pryzant et al., this approach breaks optimization into smaller steps:

- Score the current prompt's outputs
- Using an LLM, generate specific feedback for each example where the prompt failed (these are the "gradients")
- Propose prompt updates based on these collected "gradients"
The idea is that collecting fine-grained feedback before making changes leads to more targeted improvements than the meta-prompting approach.
Evolutionary Optimization
These algorithms operate in "generations", with groups of generations organized by a phase of a larger curriculum. For each generation, the algorithm applies semi-random "mutations" (in our cases, different types of prompt updates created with the help of an LLM) to create candidate prompts. The best performing prompts are retained after each generation.
In these experiments, we adapted PhaseEvo, a recent technique by Cui et al. that combines direct "text gradient" approaches like the one described above with more "global" or lateral updates that instruct the LLM to create new prompts based on shared patterns in the existing population. In theory, this helps the algorithm overcome local optima through greater exploration of variations across the prompt population. PhaseEvo works in phases:
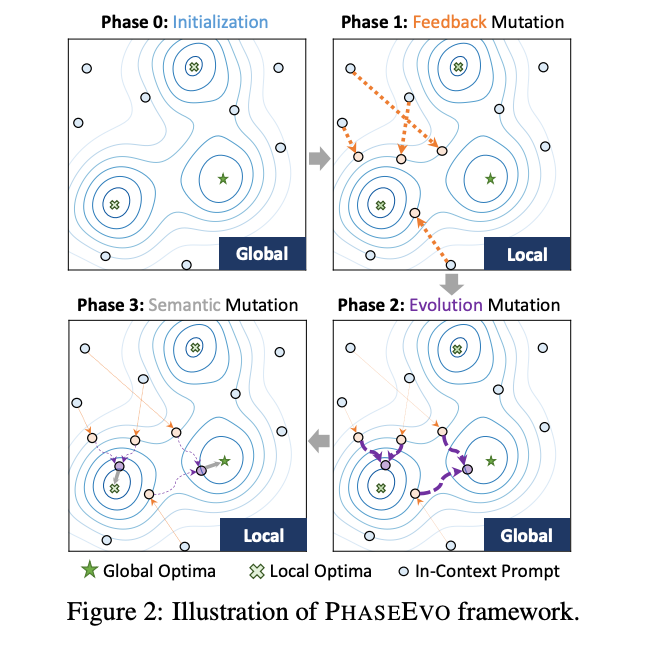
- Generate diverse initial prompts (by guessing instructions that would create the expected outputs for a set of training examples and then paraphrasing these prompts for more diversity)
- Apply prompt gradients to the best performers (See the prompt gradients section above for more information)
- Create new variants of the top 5 performing prompts through paraphrasing
- Combine successful prompts to capture their best elements. This generates a new prompt from two or more existing prompts that are most dissimilar. Since this focuses on distilling or expanding existing prompts, it avoids getting stuck on local errors and encourages further exploration.
- Repeat gradient optimization on the winners to finish.
The hypothesis for these types of approaches is that LLMs tend to get stuck making shallow corrections based on observed errors without sufficiently analyzing the data as a whole and without adequately exploring other prompting techniques. The structured prompt evolution in theory could help the process find a more globally optimal solution compared to the more straightforward hill-climbing approaches.
Datasets
We created five datasets to benchmark these on.
- Support email routing 3: for each inbound email, route them to the correct assignee (of 3 assignees).
- Support email routing 10: same as (1) but with 10 possible assignees. This is more challenging, since the "domain expertise" of each assignee is less distinct.
- Multilingual math: the LLM is given a mathematical word problem and must respond with the correct answer spelled out in one of 5 languages. Language is determined by the topic or theme of the word problem (sports->Korean, outer space-> Arabic, cooking -> German, music->English, wildlife->Russian). Neither the prompt nor the optimizer know why a target language is chosen, so the optimizer must be able to discover the latent pattern hidden in the dataset.
- Email assistant simple: this is a synthetic dataset meant to test whether prompt optimization is useful for tasks that are well-covered by the LLM's domain knowledge. The LLM is tasked with classifying whether to ignore, respond, or notify the user for a given email.
- Email assistant eccentric: this is similar to the dataset above, but based on more hidden preference rules. Note: these preference rules are eccentric, meaning even though the response labels are within the LLM's domain knowledge, the preference rules are not. We crafted a persona of a busy, eccentric tech mogul to provide the ground truth labels for the responses.
Results
We ran experiments across the five datasets using OpenAI's GPT-4o and O1 models, and Anthropic's Claude-3.5-sonnet as meta-prompting LLMs to drive the optimization algorithms. The target LLM is GPT-4o-mini (meaning we are using other models to optimize a prompt for GPT-4o-mini).
For each algorithm, we select the prompt with the best score on the dev set as the final output of the optimization run. For that prompt, we plot the average scores over three runs on the test split (in the bar charts). 95% confidence bounds are also shown, computed using Wilson score interval for the binary pass/fail metrics. In the appendix, we also plot the dev set scores for each epoch (or phase in the case of the evolutionary algorithm) to better show the training dynamics for each experiment.
As baselines, we compare the results against GPT-4o-mini scores on a starter prompt for each task. We also include results for how other based models (Claude-3.5-sonnet, O1, O1-mini, and GPT-4o) would have fared on the baseline prompt. Here is what we found.
Note: Due to sporadic flagging for content violations in the O1 endpoint during the evolutionary prompting algorithm, we have omitted a couple o1 experiments that were unable to complete.
Support email routing (3)
The optimizers consistently improved over the baseline prompt, with both gradient and evolutionary approaches showing similar gains. Claude notably outperformed GPT-4o across all approaches. Claude and 4o fail to improve much even on the dev set using the meta-prompting approach.
Below are the results on the test split. Few-shot prompting consistently led to improved, but sub-optimal performance, with the 4o-mini setup only slightly outperforming the worst of the meta-prompting techniques. The more involved evolutionary algorithm slightly outcompeted the other algorithms as well. Claude does a slightly better job at optimizing the underlying model than O1, with GPT-4o lagging behind.

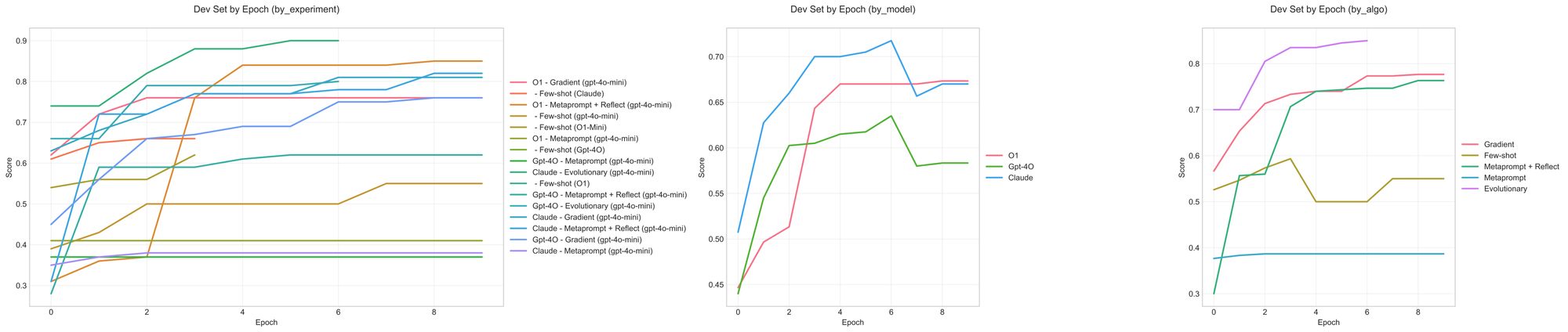
Support email routing (10)
This is a slightly harder 10-way classification problem of a similar style to the previous dataset. As you can see from the curves below, GPT-4o's failure to converge on the development set when using the simple meta-prompting & the meta-prompting + reflection algorithms is predictive of poor performance on the test split.
The final test results are below. Similar to the first dataset, few-shot prompting gives consistent improvement, though it still lags behind most of the other prompt optimizer techniques.

O1 really shines on this dataset, outperforming Claude under similar configurations. Gpt-4o suffers once more in all but the evolutionary and gradient algorithms. Surprisingly, GPT-4o causes a prompt regression when using meta-prompt + reflect configuration, likely due to overfitting to specifics on the training split.
Multilingual math
This dataset was perhaps the most discontinuous, as shown by the dev set performance getting most of its improvements in a single epoch around epoch 3 or 4 (see Appendix). This is because the data contains a simple hidden pattern: the target language is determined by the topic of the word problem. Below are the test split results.

Due to the stated discontinuity, most of the model<>algorithm combinations failed to provide much improvement over the baseline.
The reasoning models (O1 and O1-mini) were the best at effecively leveraging the few-shot examples, beating out all the techniques that weren't able to converge to the correct solution. Surprisingly, though O1 was able to leverage the few-shots, it did a poor job of optimizing the prompt instructions. O1 was unable to discover the trick in any of the algorithms.
Claude and (somewhat surprisingly) GPT-4o were both able to discover the solution using the evolutionary algorithm (which runs the optimizer through a curriculum to capture local and global information rather than repeatedly focusing on specific errors). Similarly, Claude was able to discover the correct solution under the metaprompt + reflection setup.
Email assistant simple
This dataset prompts the model to decide whether an email assistant should notify the user, ignore the email, or respond to the email directly. It follows rules that are fairly obvious, meaning that we expect the base prompt configurations to work well. Below are the training curves.
And the following are the test results. As you can see at a glance, the results are fairly consistent across model<>algorithm combinations.

In this case few-shot examples produce the most reliable improvements. The task doesn't require the optimizer to uncover any hidden patterns far from the target model's existing behavior. The patterns are barely hidden. Because of this, few-shots do the best job of communicating the expected behavior.
The direct prompt optimization approaches (gradient, metaprompt) have a hard time capturing reasonable instructions to guide the model in this case beyond what it already knows. We noted that meta-prompting tends to include some unnecessary instructions, even if the optimizer is instructed to focus only on adding instructions that explicitly address failures. O1 and GPT-4o both struggled to assist on this task.
Email assistant eccentric
This task revealed interesting differences between algorithms. The evolutionary approach showed steady improvement throughout training, though never reached perfect scores. More importantly, its improvements translated more reliably to test set performance for 2 of the 3 combinations.
Here, Claude still outperforms GPT-4o and O1. The evolutionary algorithm generally outshines the other two techniques, though O1 seems to underperform in that setting.

Overall Results
Below we plot the average percentage change of each experimental setup across all tested datasets. We use bootstrap sampling to plot 95% confidence intervals for each metric. We also group results by optimizer model and by algorithm. Percentage change represents the optimizer's impact on the target model, relative to the GPT-4o-mini baseline. 100% means that the score has doubled in relative impact, so if the original prompt gets a 20% on a task, the optimized prompt is 40%, etc.
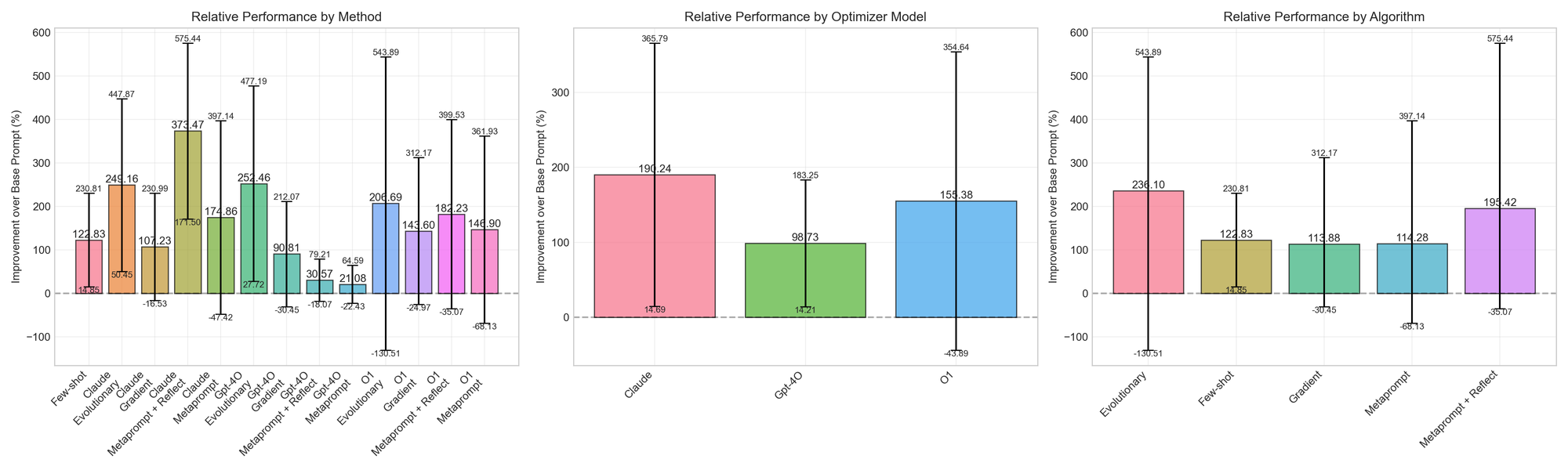
As you can see, the results have wide error margins! While we do see consistent improvements for many of the algorithm<>model settings for these datasets, the lower bound for most of the experiments is negative - the current settings sometimes cause the prompt to overfit to training examples rather than leading to robust systems. When applying these techniques, it continues to be important that you maintain a separate test split to confirm that the improvements you see on the train & development splits actually translates to more aligned behavior in reality.
As shown, Claude and O1 perform comparably on-average, but O1 has a very high variance. If you were to care just about the head-to-head win rate, the consistency is more clear: under the tested settings, Claude was a more reliable optimizer model.
Adding in O1's slower processing time, higher costs, and less reliable API (OpenAI semi-frequently incorrectly flagged our completions as violating the ToS), we feel comfortable recommending Sonnet 3.5 as the preferred optimizer model for now. We're excited to update our recommendations with the launch of O3 and other models.
What We Learned
The results above generally support the existing literature that LLMs are effective prompt engineers. These experiments also shed some light on when they would be (in)-effective.
- Meta-prompting is especially useful for discovering rules or preferences and other clear patterns in the data that may not have been in the LLM's domain knowledge. This means you can define the behavior you want through examples and rely on the optimizer to translate those behaviors to other LLMs so long as they are reasonable instruction followers. This makes declarative prompt programming models possible.
- Meta-prompting (via instruction tuning) is less useful for communicating nuance in preferences, as shown in the simple email classification dataset. All the prompt tuning approaches underperformed the few-shot prompting approach for the simple email dataset, where the distinction was less about bright-line rules and conditionals.
- We suspect from (1) and (2) that combining few-shot prompting & instruction tuning provides complementary improvements. This supports existing conclusions such by Opsahl Ong, et. al. and Wan, et. al. Few-shot examples communicate more information than simple instructions but don't capture complex conditionals and rules that will likely be a part of your own enterprise's agents. On the other hand, prompt optimization through reflection, "text gradients", or evolutionary algorithms can make more targeted improvements based on existing performance and dataset characteristics, and do so in a more token-efficient way.
- Meta-prompting doesn't endow the model with new capabilities. For the multilingual math dataset, GPT-4o-mini still didn't surpass 65% pass rate on any of the optimized configurations, largely due to reasoning errors. While the optimizers were able to instruct it on how to behave (which sometimes can induce better ways to think via example reasoning trajectories), they don't unlock more powerful reasoning abilities or complex domain-specific knowledge.
Beyond evals
We have been building LangSmith to help teams evaluate their LLM applications systematically. Good evaluation lets you detect when things go wrong and understand your system's behavior. But the datasets and metrics you build for evaluation unlock something even more valuable: the ability to improve your system systematically through optimization.
The datasets in our experiments worked well for optimization because they had clear, verifiable outcomes:
- Routing decisions with ground truth labels
- Math answers that can be validated
- Language constraints that can be programmatically checked
This matters because optimizing against fuzzy or unreliable metrics often makes prompts worse, not better. An LLM judging outputs based on vague criteria will optimize toward its own biases rather than your actual requirements.
If you're tracking your application's performance in LangSmith, you're already building the foundation needed for effective prompt optimization. The same datasets that help you understand failures can drive systematic improvements. Data, metrics, and learning close the loop.
Prompt optimization as long-term memory
Optimization is learning, and as such, it can be useful to think of prompt optimization as a special case of long-term memory that captures "always-on" behavioral patterns.
While traditional memory systems store information in databases (vector, graph, or otherwise), prompt optimization stores them directly in your agent's prompt so they are always available in context. Doing so ensures they influence every decision. This is useful for storing core patterns like behavioral rules, stylistic preferences, and key personality traits.
Memory's process of "learning and improving" is very similar to traditional prompt optimization, just with slight differences in how updates are scheduled, and where the updates are stored. The same techniques that work for prompt optimization and learning algorithms in general may also apply to memory. This is an angle we are actively investigating.
Why this matters
These results support what we (and others like DSPy) have observed: LLM-driven prompt optimization can systematically improve prompts and automate much of the manual guess-and-check process that dominates prompt engineering today. Making this methodology accessible to all stakeholders can help us all build better, more capable systems.
But it's not a silver bullet. None of our optimized prompts saturated the test sets, and the improvements varied across tasks. This suggests prompt optimization is best viewed as one tool in a broader toolkit for improving LLM applications.
We plan to integrate these insights directly into LangSmith to help teams move beyond manual prompt engineering. The goal isn't to eliminate human judgment, but to make it more systematic and data-driven.
Reproduction
You can reproduce these experiments by running the all_sweeps.sh script in https://github.com/hinthornw/promptimizer/tree/wfh/blog_experiments
Appendix
Training Dynamics
In the previous sections, we primarily discussed how the final prompts performed on the held-out test split. Below, we share charts of the algorithms' training dynamics on the development split for each dataset. These charts show how different algorithms fit to the provided dataset. Comparing these charts with the final scores also reveals the extent to which the algorithms overfit the data in ways that don't translate to consistent gains.
Support email routing (3)
Most of the optimizers consistently improved over the baseline prompt, with both gradient and evolutionary approaches showing similar gains. Claude notably outperformed GPT-4o across all approaches. Claude and 4o fail to improve much even on the dev set using the meta-prompting approach.
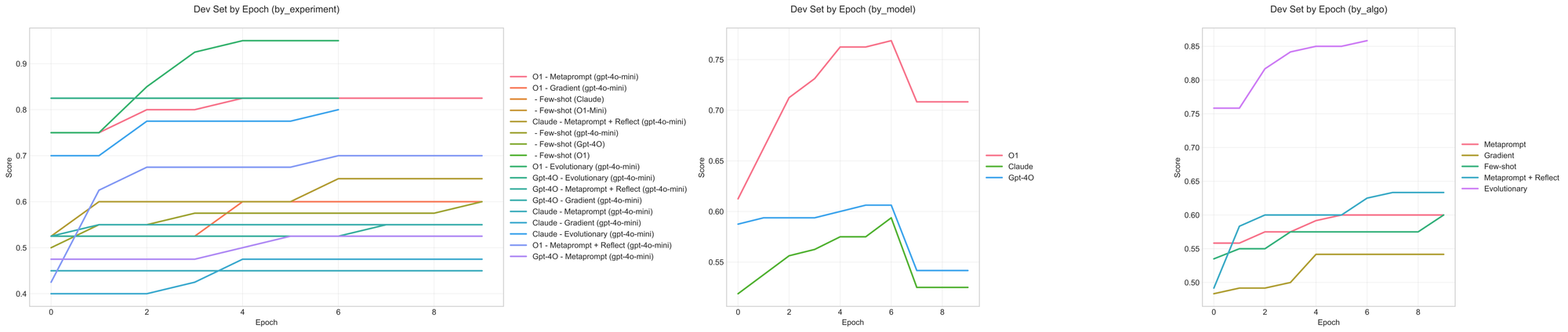
Support email routing (10)
Naive GPT-4o-powered meta-prompting & meta-prompting + reflection settings fail to learn the classification rules in this dataset. We quickly are seeing a common pattern forming: if the curves stay flat, they obviously don't learn. If the curves quickly approach a perfect score, they likely overfit. It's the algorithms in the middle and with consistent improvements that tend to translate to the best test-set performance.
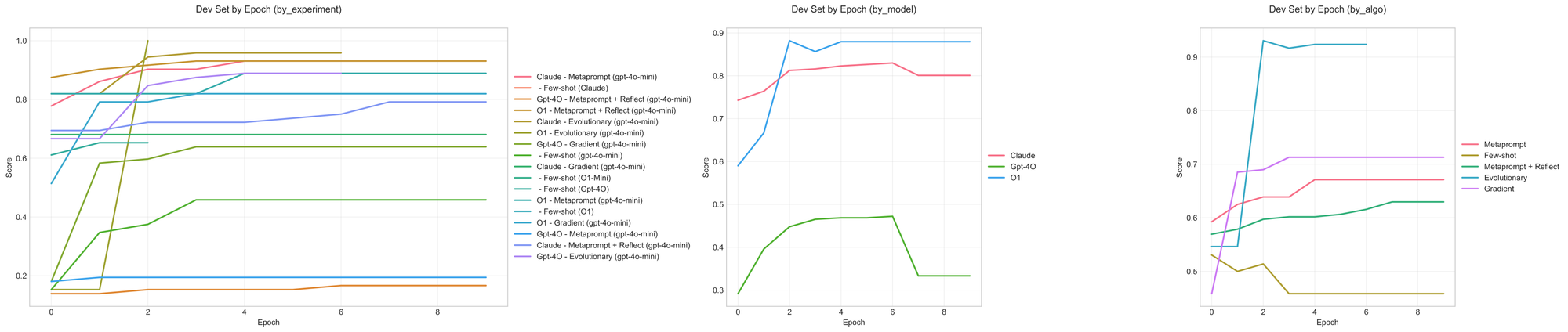
Multilingual math
This dataset was perhaps the most discontinuous, as shown by the dev set performance getting most of its improvements in epochs 2, 3 (or even later) for a few of the settings. This also highlights the usefulness of tracking the edit history beyond the last attempt or two. LLMs are fairly useful meta-optimizers by being able to translate the history of edits into more effective updates.
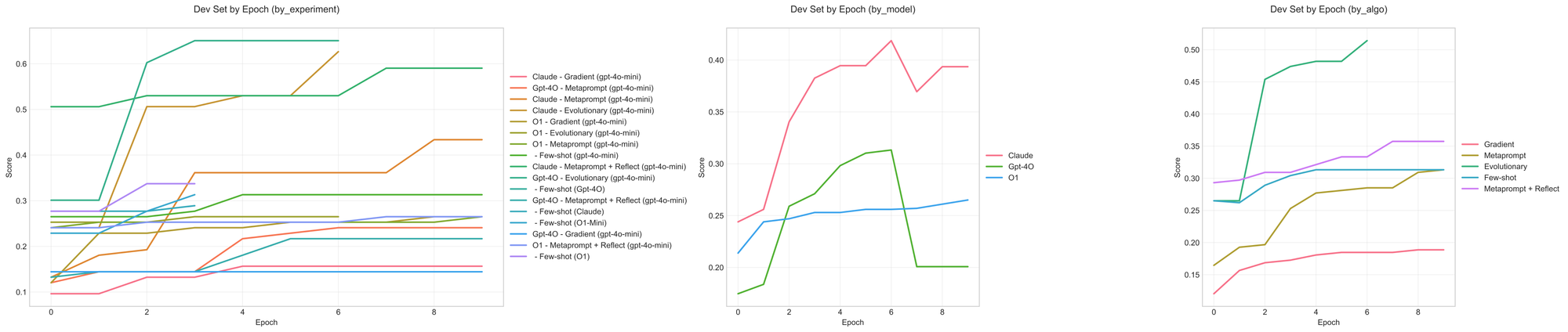
Email assistant simple
Here again we see that the prompt optimization setting (gpt-4o + metaprompting + reflect) that achieves the highest performance on the dev split doesn't actually translate to good performance on the test split.
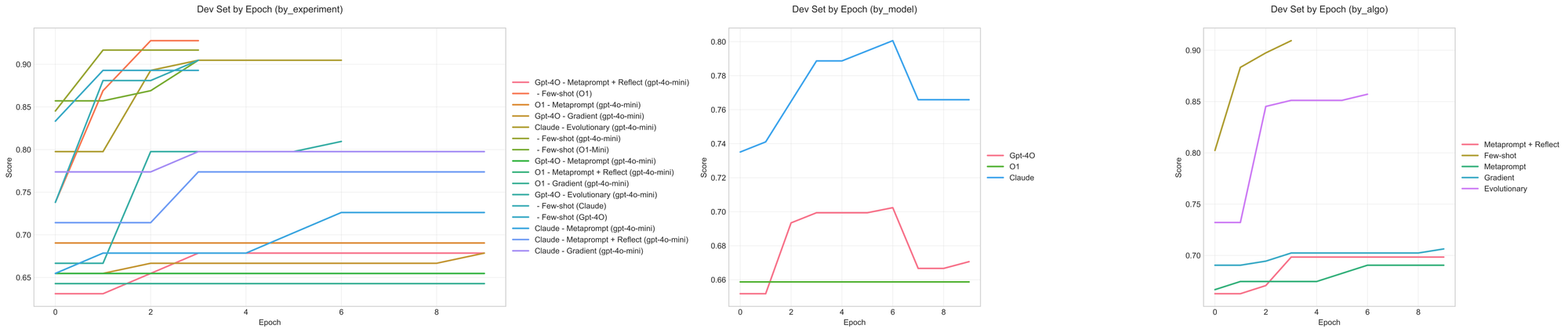
Email assistant eccentric
Though the Claude+evolutionary algorithm setting earned the highest test-split performance, we see that the algorithms that fit the dev set the fastest (and most) were those powered by O1. The o1-evolutionary setting fit the dataset the fastest, despite ultimately failing to significantly improve the quality of the system on the test set. On the other side, settings that don't fit the dev set also fail to improve the prompt significantly on the test set (above).
Comparing Prompts
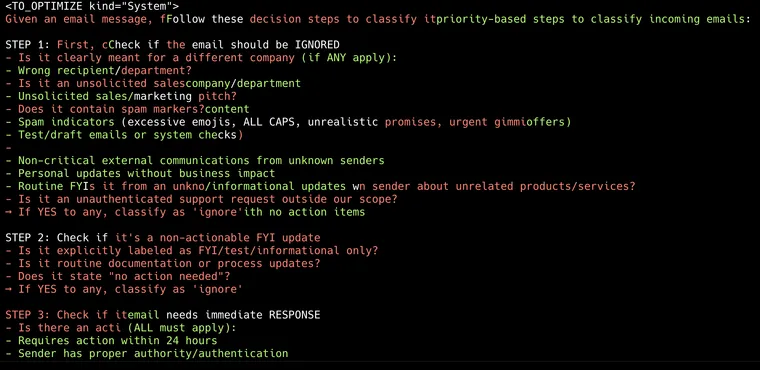
While we ultimately care more about the downstream metrics than the exact content of the prompt, it can be illustrative to review the final prompts to see what the optimizers actually learn to modify, and what changes lead to improvements. We will take the Support 10-way classification dataset as an example. First, comparing the four algorithms when driven by Sonnet




All four of the algorithms were able to learn the primary assignment rules. The gradient-based approach seemed to be less robust about finding the areas of ambiguity to clarify the boundaries. The other algorithms identify either "priority rules" or invent decision trees to help clarify these bounds.
Comparing optimizer models on the same algorithm, you can also see slight differences in behavior. In this case, O1 seems more likely to be creative with incorporating different techniques (synthetic few-shots & stepwise instructions) and tends to use its characteristic section demarcators ("—") between rulesets, while Claude seems to be the most terse and direct in this case, but both these two learn priority rules as well as domain mapping. GPT-4o seems to create the least information-dense instructions.


