
TLDR: We’re excited to announce a new LangChain template for helping with research, heavily inspired by and in collaboration with the GPT Researcher team. We are excited about this because it is one of the best performing, long-running, general, non-chat “cognitive architectures” that we’ve seen.
Key Links:
- Access the “research assistant” template here
- Watch us code the "research assistant" from scratch here
The Downside of Chat
Most LLM applications so far have been chat based. This isn’t terribly surprising - ChatGPT is the fastest growing consumer application, and chat is a reasonable UX (allows for back and forth, is a natural medium). However, chat as a UX also has some downsides, and can often make it harder to create highly performant applications.
Latency Expectations
The main downside are the latency expectations that come with chat. When you are using a chat application, there is a certain expectation you have as a user around the latency of that application. Specifically, you expect a quick response. This is why streaming is an incredibly important functionality in LLM applications - it gives the illusion of a fast response and shows progress.
These latency expectations mean that it is tough to do too much work behind the scenes - the more work you do, the longer it will take to generate a response. This is a bit problematic - the major issue with LLM application is their accuracy/performance, and one main way to increase is the spend more time breaking down the process into individual steps, running more checks, etc. However, all these additional steps greatly increase latency.
We often talk to teams who try to balance these two considerations, which can at points be contradictory. While working in a chat UX, for complex reasoning tasks it’s tough to get a highly accurate and helpful response in the time that is expected
Output Format
Chat is great for messages. It’s less great for things that don’t really belong in messages - like long papers or code files, or multiple files. While working with a chat UX, displaying results as messages can often make them tougher to review or consume.
Human in the Loop
LLMs are not (yet) highly accurate, and so most applications heavily feature humans in the loop. This makes sense - only use the LLM in small bursts, and then have a human check/validate its output and ask for a followup.
However, there is a balance to strike here. If the human needs to be too much in the loop, then it’s not actually saving them time! But you can’t take the human out of the loop completely - again, LLMs just aren’t reliable enough for this.
The key is in finding UXs where you can ask the LLM to do a large amount of work, but it results in something that is still not expected to be a perfect output.
Non-Chat Projects
There are a number of projects that we are excited about that do not use chat as a primary medium. Highlighting a few below:
This project has a small chat component (asking clarifying questions) afterwords runs autonomously and generates code files. This has humans in the loop at key points:
- Clarifying questions: early on, gather requirements
- At the end, when you can inspect the code
The final generated code can easily be modified by the user, so it’s more of a first draft than anything. The output is Python files - far more natural than outputing in chat. There’s no expectation that files are generated automatically - if I were to ask a colleague to write some code, I wouldn’t expect them to continuously message me their progress! I’d expect them to go off for a while, do some work, and then I’d check in - exactly the UX here.
This bot has been patrolling our GitHub repo and responding to issues. Users do not interact with it through chat, but rather through GitHub issues. The expectation for response time on GitHub issues is FAR higher than that of chat, allowing plenty of time for DosuBot to go do its thing. Its outputs are not expected to be perfect artifacts either - they are merely replies to users. The users are very much in the loop to take them and implement them as they see fit.
We’ve discussed this project before (and will discuss it far more in the next section, as “Research Assistants” are heavily based on it). This project writes full research reports. It saves files that are generated - just as we would save research reports (we wouldn’t message them in chat to each other)! It takes a while to run - but that’s totally fine. If I asked a colleague to write me a research report, I wouldn’t expect anything close to an instantaneous response. It’s outputs can easily be inspected and modified, and used as a first draft - no expectation of a complete output.
All of these projects buck the trend of chat based UXs. They bite off larger and larger chunks of work - rather than answer a single question that you can use in a research report, they write the research report for you! The final response is often best served not as a chat message but some other file, and these can easily be modified, so there is still a human-in-the-loop component.
These project’s aren’t just exciting because they don’t use chat. They are exciting because they are some of the most useful applications we see, and that be precisely because they do not use chat.
Research Assistant
A few weeks ago we introduced LangChain Templates - a collection of reference architectures that are the quickest way to get started with a GenAI application. Most of these revolved around chat. However, some of the most interesting and useful applications we see (including the ones above) do not use chat as the primary interface.
We wanted to begin to add templates that were not chat based. We have worked closely with the GPT-Researcher team in the past and think they have a fantastic use case. As such, we worked with them to add a “Research Assistant” template to LangChain Templates, making it easy to get started with this template completely in the LangChain ecosystem. Note: they also recently released a major new version - check it out.
What does this application do under the hood? The “cognitive architecture” can be broken down into a few steps:
- User inputs question/topic to write about
- Generate a bunch of sub questions
- For each sub question: research that subquestion and get relevant documents, then summarize those documents with respect to the subquestion
- Take the summaries for each subquestion, and combine them into the final report.
- Output Final Report
Each of these pieces is modular, making it a perfect fit for the LangChain ecosystem
- Swap out the prompt and/or the LLM used to generate the subquestions
- Swap out the retriever used to fetch relevant documents
- Swap out the prompt and/or the LLM used to generate the final report
By default, the template uses OpenAI for the LLM, and Tavily for the search engine. Tavily is a search engine made by the GPT-Researcher team, and is optimized for AI workloads. Specifically, the Tavily API optimizes for RAG. They optimize for getting the most factual and relevant information to insert in any RAG pipeline that will maximize LLM reasoning and output. This allows for an easy-to-use experience of searching the web. However, it can easily be modified to point to our Arxiv Retriever, or our PubMed Retriever, and quickly turned into a research assistant for those sites. It can equally easily be pointed to a vectorstore containing your relevant information.
This architecture is doing a LOT under the hood. Another big benefit of integrating this into the LangChain ecosystem is that you can get best-in-class observability for this architecture through LangSmith. With LangSmith, you can see all the many steps, and inspect the inputs and outputs at each one
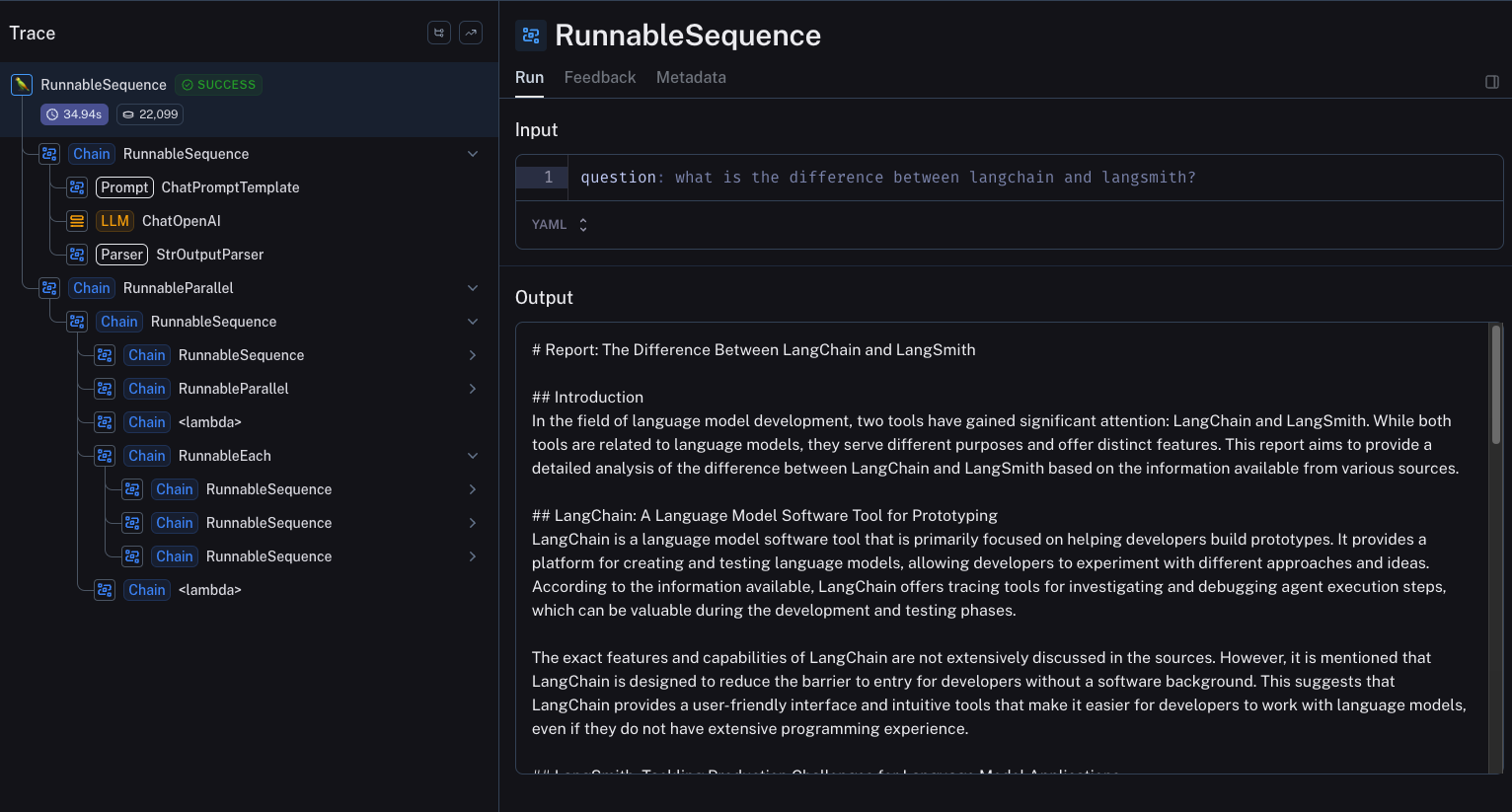
You can explore this example trace here.
Conclusion
While the GenAI space so far has been dominated by application with chat UXs, we are bullish on the most useful autonomous systems being longer running ones. So is Assaf Elovic, the creator of GPT-Researcher:
As AI improves, so will automation grow over time, and user behavior will only grow to demand it more and more from products. And with automation growing, user expectation will change, moving less from immediate response/feedback and more to the ability to get high quality results.
Because of this, there is room and need for much more sophisticated AI applications that might take longer to complete, but aim at maximizing quality of RAG and content generation. This is also relates to autonomous agent frameworks that will run in the background to complete complex tasks.
GPT-Researcher is a perfect example of this, and we’re excited to have worked with them to bring this “research assistant” template to fruition. Play around with it here and let us know your thoughts!