
In taking your LLM from prototype into production, many have turned to fine-tuning models to get more consistent and high-quality behavior in their applications. Services like OpenAI and HuggingFace make it easy to fine-tune a model on your application-specific data. All it takes is a JSON file!
The tricky part is deciding what to include in that data. Once your LLM is deployed, it could be prompted given any input - how do you make sure it will respond appropriately for the user or machine it is meant to interact with?
For this, there is no real substitute for high-quality data taken from your unique application context. This is where LangSmith and Lilac can help out.
LangSmith + Lilac
To understand and improve any language model application, it’s important to be able to quickly explore and organize the data the model is seeing. To achieve this, LangSmith and Lilac provide complementary capabilities:
- LangSmith: Efficiently collects, connects, and manages datasets generated by your LLM applications at scale. Use this to capture quality examples (and failure cases) and user feedback you can use for fine-tuning.
- Lilac: Offers advanced analytics to structure, filter, and refine datasets, making it easy to continuously improve your data pipeline.
We wanted to share how to connect these two powerful tools to kickstart your fine-tuning workflows.
Fine-tuning a Q&A Chatbot
In the following sections, we will use LangSmith and Lilac to curate a dataset to fine-tune an LLM powering a chatbot that uses retrieval-augmented generation (RAG) to answer questions about your documentation. For our example, we will use a dataset sampled from a Q&A app for LangChain’s docs. The overall process is outlined in the image below:
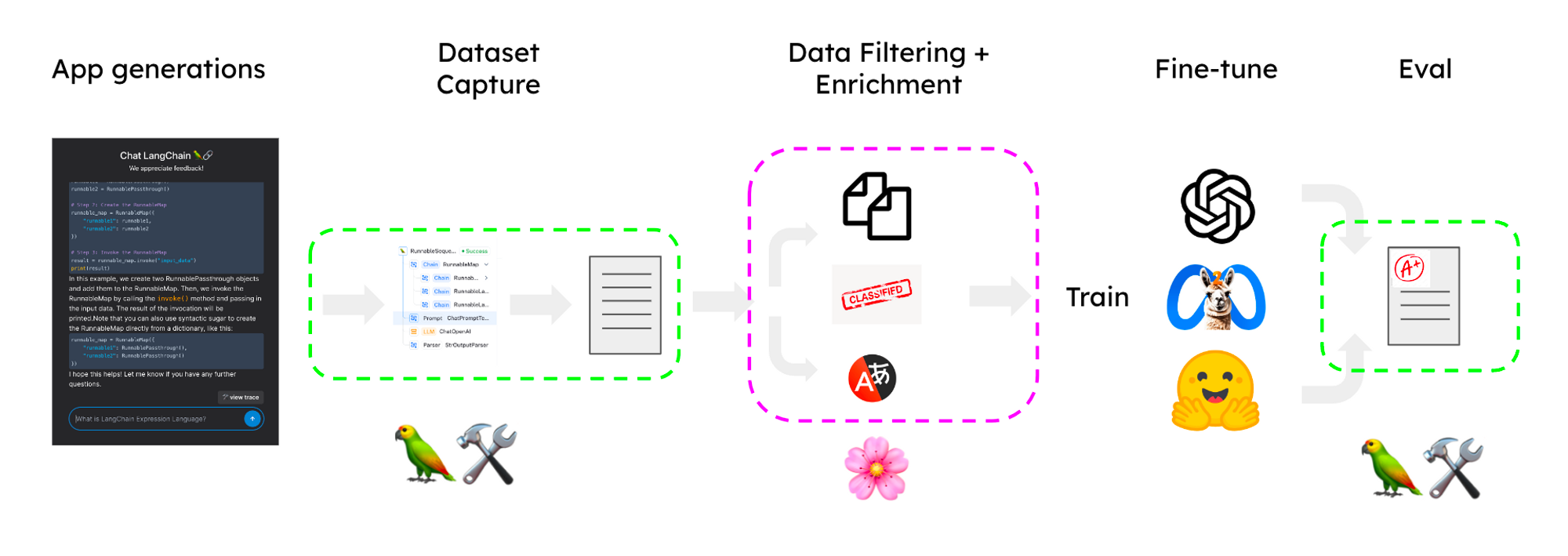
The main steps are:
- Capture traces from the prototype and convert to a candidate dataset
- Import into Lilac to label, filter, and enrich.
- Fine-tune a model on the enriched dataset.
- Use the fine-tuned model in an improved application.
Capture traces
LangChain make it easy to design a prototype using prompt chaining. At first, the application may not be fully optimized or may run into errors when the prompt engineering is incomplete, but we can quickly create an alpha version of a feature to kickstart the dataset curation process. When building with LangChain, we can easily trace all the execution steps to LangSmith by setting a couple of environment variables.
Then in LangSmith, we can select runs to add to a candidate dataset in the UI or programmatically (see the notebook).
Import to Lilac
Lilac provides a native integration with LangSmith datasets. After installing Lilac locally, set the LANGCHAIN_API_KEY in the environment and you should see a list of LangSmith datasets auto-populated in the Lilac UI. Select the one you’ve earmarked for fine-tuning, and Lilac will handle the rest.
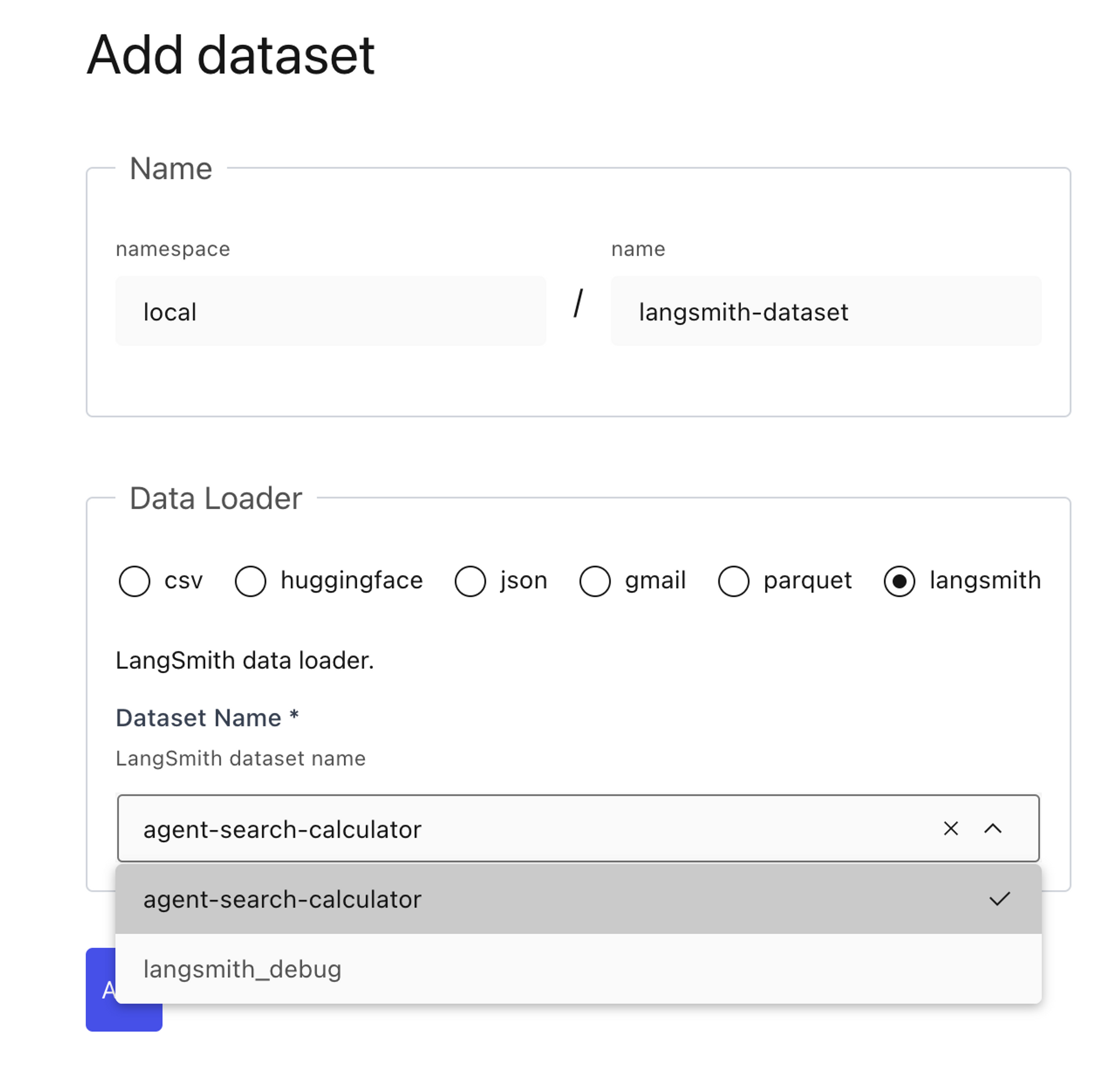
Curate your dataset
Now that we have our dataset in Lilac, we can run Lilac’s signals, concepts and labels to help organize and filter the dataset. Our goal is to select distinct examples demonstrating good language model generations for a variety of input types. Let’s see how Lilac can help us structure our dataset.
Signals
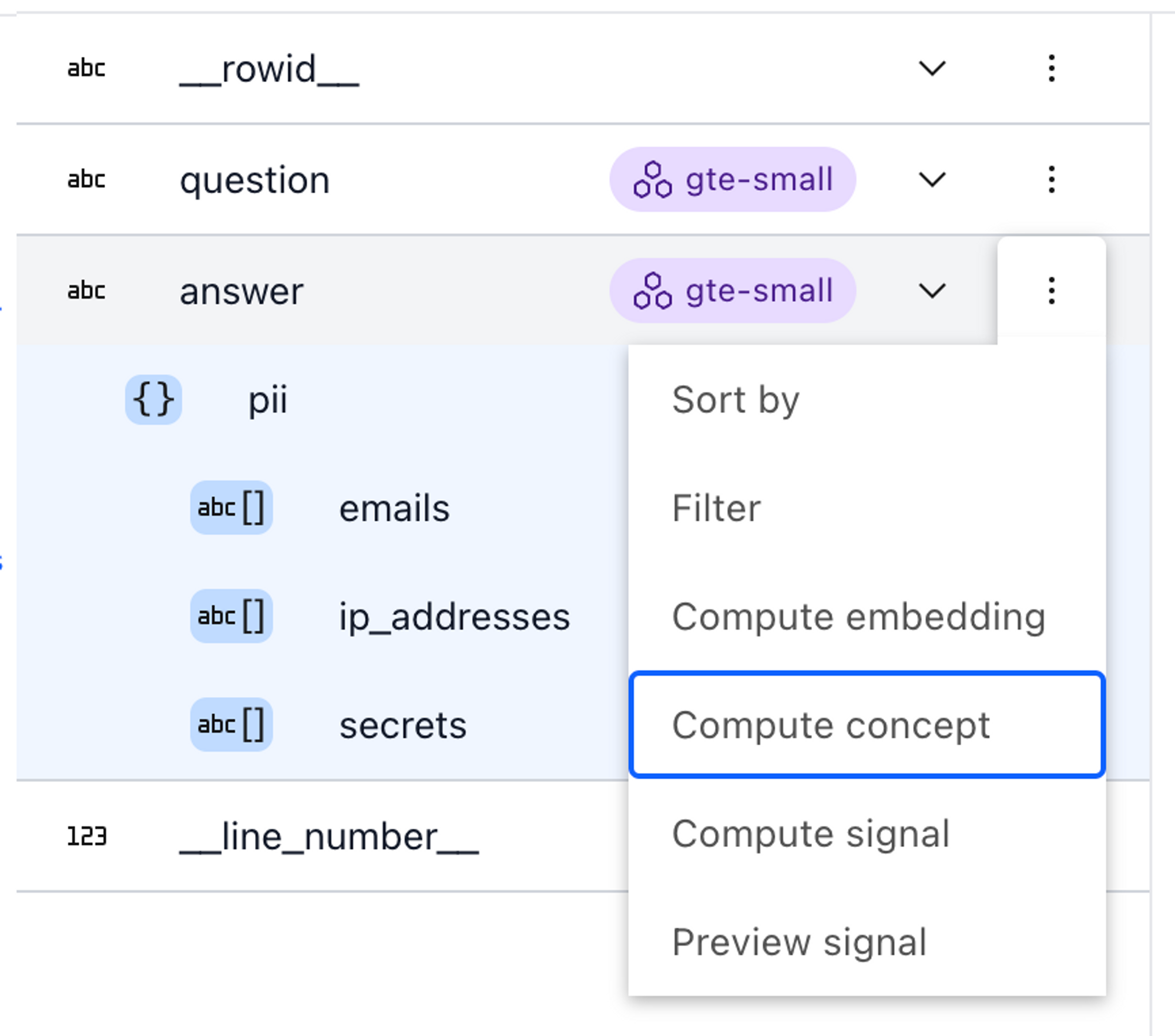
Right off the bat, Lilac provides two useful signals you can apply to your dataset: Near-duplicates and PII detection. Filtering near-duplicates for inputs is important to make sure the model gets diverse information and reduce changes of memorization. To compute a signal from the UI, expand the schema in the top left corner, and select “Compute Signal” from the context menu of the field you want to enrich.
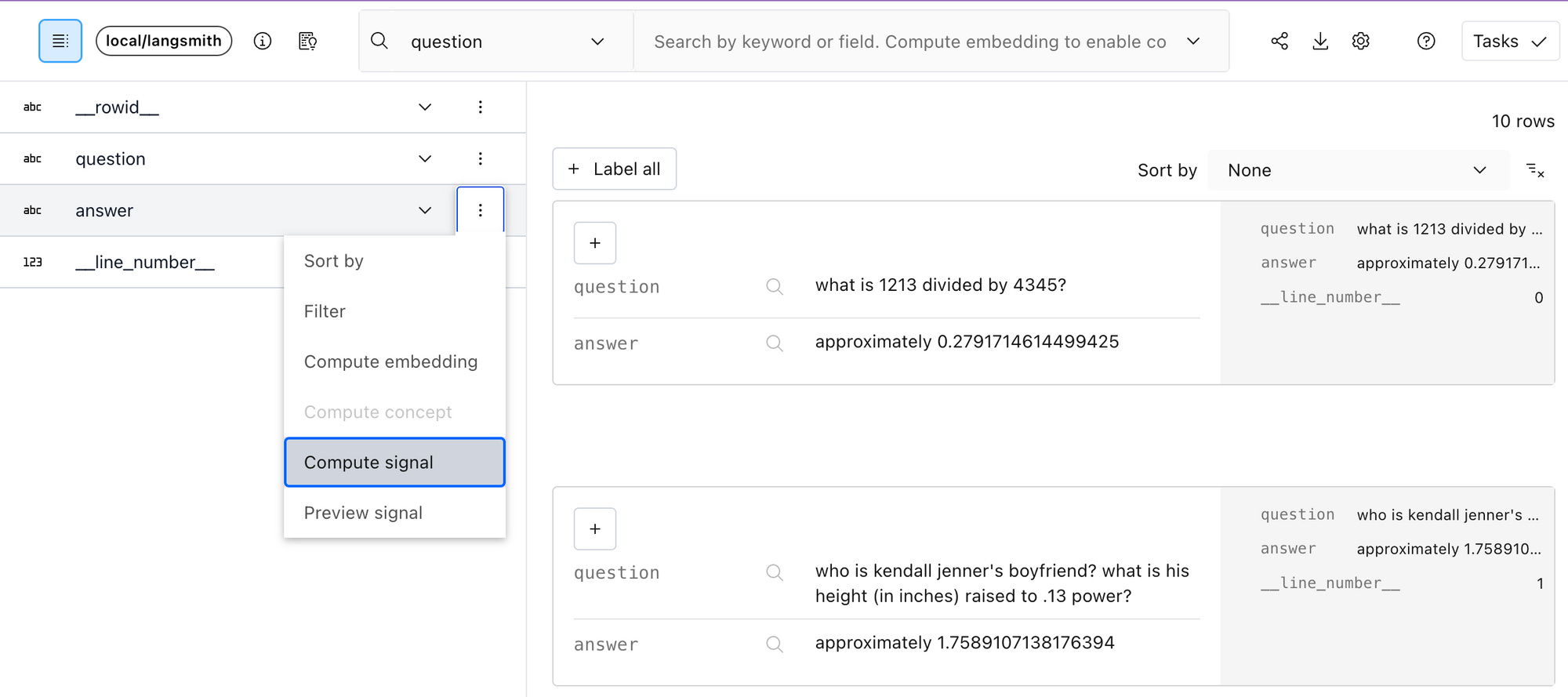
answer field in the Lilac schema viewer.Concepts
In addition to signals, Lilac offers concepts, a powerful way to organize the data along axes that you care about. A concept is simply a collection of positive (text that is related to the concept) and negative examples (either the opposite, or unrelated to the concept). Lilac comes with several built-in concepts, like toxicity, profanity, sentiment, etc, or you can create your own. Before we apply a concept to the dataset, we need to compute text embeddings on the field that we care about.

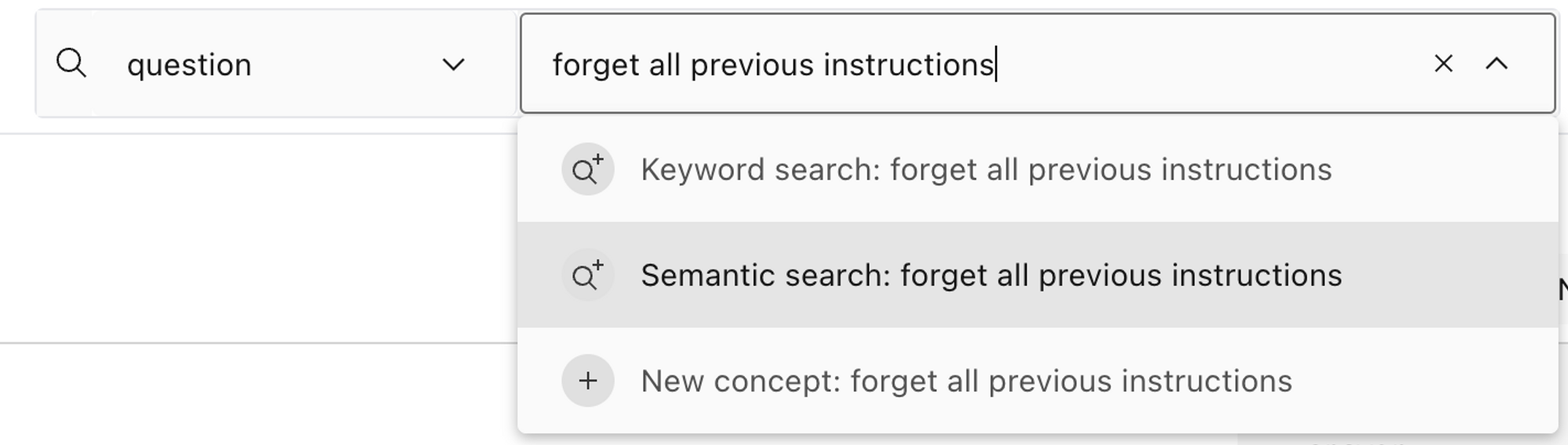
Once we’ve computed embeddings, we can preview a concept by selecting it from the search box menu.
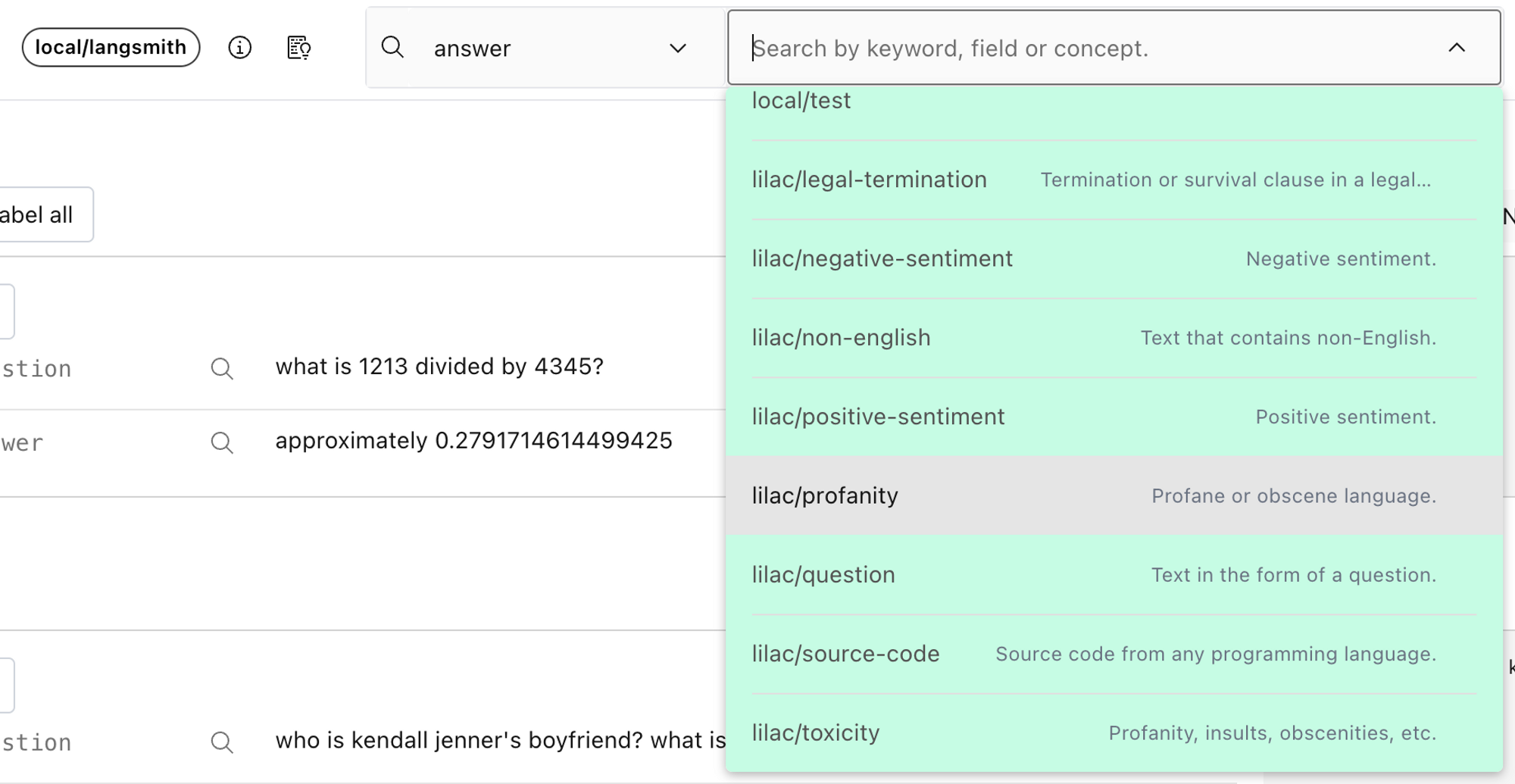
To compute a concept for the entire dataset, choose “Compute concept” from the context menu in the schema viewer.
In addition to concepts, embeddings enable two other useful functionalities for exploring the data: semantic search and finding similar examples.

Labels
In addition to automated labeling with signals and concepts, Lilac allows you to tag individual rows with custom labels that can be later used to prune your dataset.

When you add a new label, just like signals and concepts, it creates a new top-level column in your dataset. These can then be used to power additional analytics.
Export the dataset
Once we’ve computed the information needed for filtering, you can export the enriched dataset via python, as shown in the notebook or via Lilac’s UI, which will create a browser download of a json file. We recommend the python API for downloading large amounts of data, or if you need a better control over the selection of data.
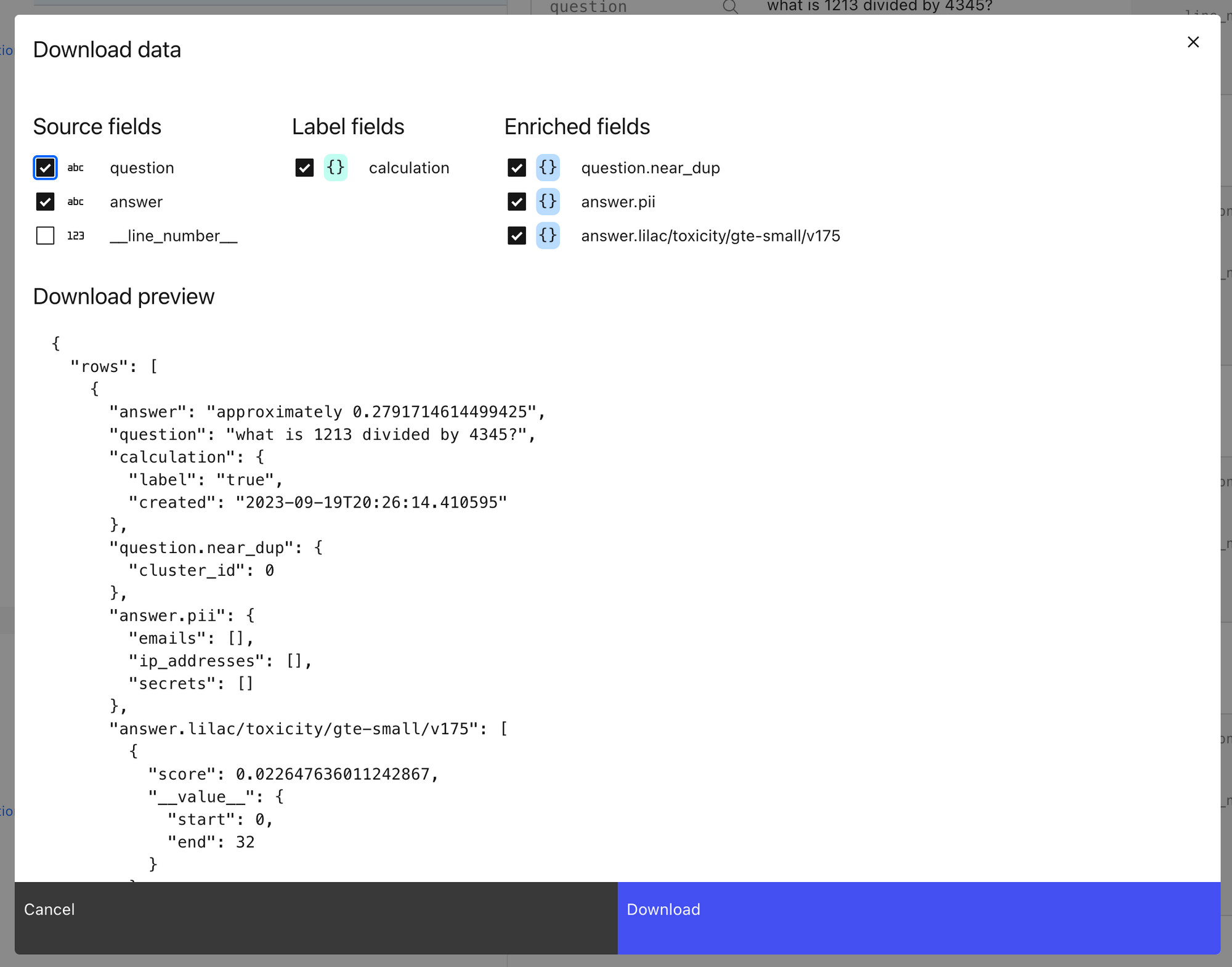
Once we exported the enriched dataset, we can easily filter out the examples in python using the enriched fields.
Fine-tune
With the dataset in hand, it’s time to fine-tune! It’s easy to convert from LangChain’s message format to the formats expected by OpenAI, HuggingFace or other training frameworks. You can check out the linked notebook for more info!
Use in your Chain
Once we have the fine-tuned LLM, we can switch to it with a update to the “model” argument in our LLM.
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="ft:gpt-3.5-turbo-0613:{openaiOrg}::{modelId}")
Assuming we’ve structured the data appropriately, this model will have more awareness for the structure and style you wish to use in generating responses.
Conclusion
This is a simple overview of the process for going from traces to fine-tuned model by integrating Lilac and LangSmith. With the data process in place, you can continuously improve each components in your contextual reasoning application LangSmith makes it easy to collect user and model-assisted feedback to save time when capturing data, and Lilac helps you analyze, label, and organize all the text data so you can refine your model appropriately.