
Editor's Note: This post was written by Jimmy Whitaker, Data Scientist in Residence at HumanSignal. Label Studio is an open-source data labeling platform that provides LangChain with flexibility when it comes to labeling data for fine-tuning large language models (LLMs). It also enables the preparation of custom training data and the collection and evaluation of responses through human feedback, a critical part of ongoing evaluation and maintenance of expert systems.
Introduction
Quality is a critical issue when applying large language models (LLMs) to the real world. LLMs, particularly foundation models, are trained on vast corpuses of data, giving them a general "understanding" of the world that is nothing less than jaw-dropping. But, along with this wide coverage, LLMs also inherit an internet-level bias that is near impossible to fully understand, let alone control. This ubiquitous bias poses a challenge because it doesn't always align with the expectations and requirements of our unique application domains. Therefore, a one-size-fits-all LLM often falls short of the expectation of providing quality responses for specific applications.
This is not to say that focusing on the quantity of data has not been instrumental in achieving phenomenal results for general chatbots. But as much as these LLMs are data-rich, their application in the real world leaves room for improvement. Quality, not quantity, becomes the key issue. For business applications, contextual awareness, data privacy, and the ability to control these applications are vital requirements. LLMs and applications built on top of them need continuous fine-tuning to suit specific domains and align the model with our precise needs. The ability to do this consistently and reliably is becoming integral for vertical-specific LLM applications.
Additionally, we must continuously tune and improve our models and applications. This ongoing tuning ensures that our language models perform optimally within our domains and do not propagate biases we'd rather leave behind.
These challenges require organizing and evaluating data for application-specific tuning and evaluating model quality. These needs bring us to the star of the day - Label Studio.
Label Studio: Your LLM Tuner
Label Studio plays an indispensable role in the ongoing process of improving large language models and the applications surrounding them. It is a platform to capture and annotate user interactions with our applications. This ability is vital for understanding our models' performance and pinpointing areas where adjustments are necessary.
In this blog post, we'll explore how Label Studio can be employed as a tool for continuous improvement, specifically in building a Question-Answering (QA) system trained to answer questions about Label Studio itself, using the domain-specific knowledge from Label Studio’s GitHub documentation.
However, it’s important to note that our conversation about QA is just a starting point. Label Studio's functionality extends well beyond simple QA scenarios. It can classify sentiments in responses, rate the answers provided by LLMs, extract specific entities, and even work with audio and visual data. While our focus here is on a QA system to demonstrate a comprehensive approach to tuning an LLM application, the potential applications are boundless.
Let’s think about the QA process: as users interact with the chatbot, we can capture what questions were asked, and the answers returned. This data is then sent to Label Studio, where it can be inspected and annotated to assess whether or not the response was appropriate. Through this process of answering questions and applying annotations, we can effectively gauge the quality of our system, and we should be able to use this data to continuously enhance our QA system as well.
Before we proceed further, it's worth emphasizing two critical points:
- Contextual Understanding: Foundation Models, especially in their initial stages, might not completely grasp the full context of, say, a GitHub repository. It means there's always a potential risk of the QA bot churning out irrelevant or nonsensical responses. This underlines the importance of continuously reviewing and verifying the bot's answers.
- Dynamic Data Sources: Just when you think you've achieved a good quality level, remember that data sources (like GitHub repos) are living entities. They evolve, change, and occasionally, this could lead the bot to err. Hence, the need for regular oversight always remains.
Ultimately, our aim for the QA system serves as a blueprint for continuous enhancement across LLM applications. We want a system that allows us to strategically navigate the continuous cycle of feedback and adaptation, all while allowing us to incorporate human understanding. This continuous feedback loop is how we create valuable AI solutions.
Putting It Into Action
To demonstrate this, let’s build a simple LLM-powered QA system to answer questions about Label Studio. You can check out the full example on GitHub for more details.
Step 1: Building a Simple QA System
For this example we'll use LangChain, ChromaDB, and OpenAI to construct our QA system. Though we opted to use OpenAI in this example due to its simplified integration, replacing it with other LLMs is feasible based on your preference.
You can read more about our integration with LangChain here.
Here’s a brief overview of our approach.
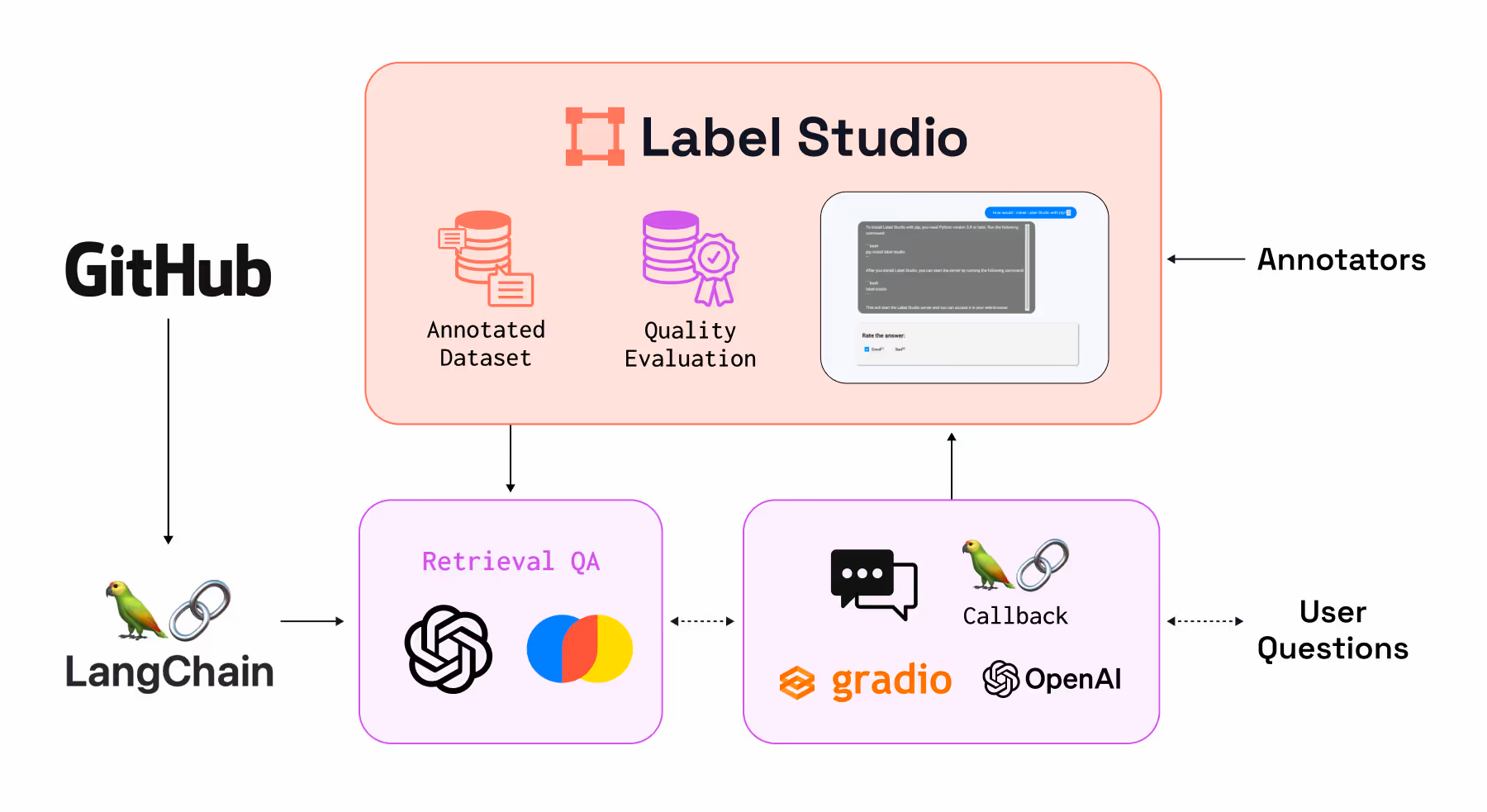
Github as our dataset: First, we need a dataset to build our document database for our QA system. Since we’re building a QA system for answering questions about Label Studio, we can use our documentation markdown files in the Label Studio Github repo as our source. LangChain makes this easy, taking just a few lines of code.
from langchain.document_loaders.git import GitLoader
from git import Repo
repo_path = "./data/label-studio-repo"
repo = Repo.clone_from("https://github.com/HumanSignal/label-studio",
to_path=repo_path)
branch = repo.head.reference
loader = GitLoader(repo_path=repo_path,
branch=branch,
file_filter=lambda f: f.endswith('.md'))
data = loader.load()LLM Embeddings for Documents: Each document is represented by an embedding, a high-dimensional vector that captures the document's content retrieved from our LLM. These embeddings allow us to discern which documents are similar to one another. When a user submits a question, we can generate an embedding for it and retrieve relevant documents.
Vector Database Storage: We utilize a vector database, ChromaDB in this case, to hold our document embeddings. This allows for efficient document comparison with our embeddings and the ability to scale our system if needed.
The following Python shows how we combine the feature extraction and vector database to create our QA system.
from langchain.text_splitter import MarkdownTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
text_splitter = MarkdownTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
vectorstore = Chroma.from_documents(documents=all_splits,
embedding=OpenAIEmbeddings())
Now that we have our embedding method and vector store with our documents imported, we’re ready to start answering questions. Our system prompt instructs the model to only rely on the documents it has received to answer the question, reducing the likelihood of hallucinated responses.
Step 2: Capture User Interactions
Chat interfaces are incredibly useful for understanding and learning about topics. We created a simple Gradio application to make interacting with the QA system easier.
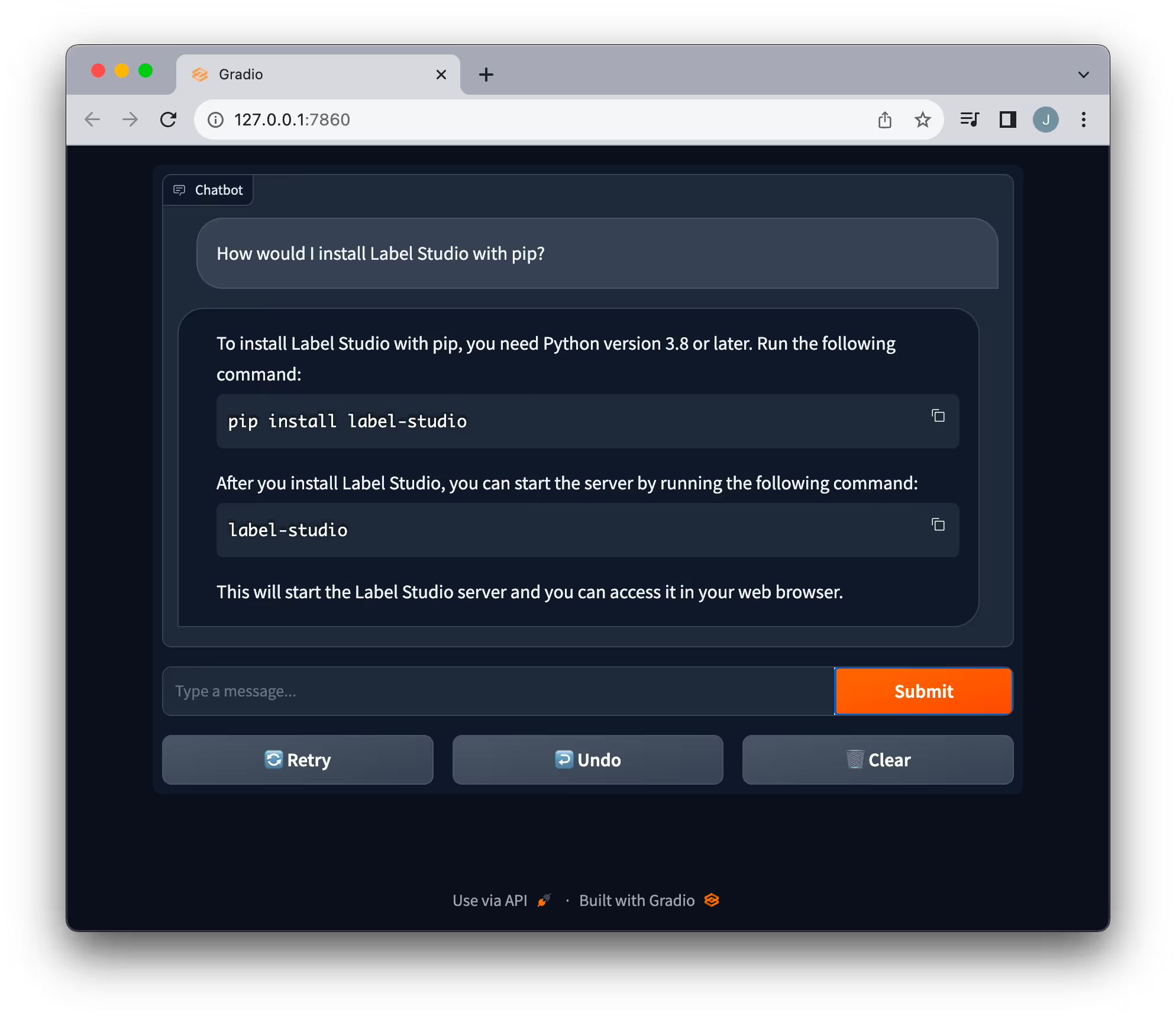
Our goal isn't solely to address user queries; it's vital to grasp the system's effectiveness by examining the quality and relevance of the answers. Therefore, we've implemented a Label Studio callback in LangChain to capture both the posed question and the system's response.
class LabelStudioCallbackHandler(BaseCallbackHandler):
def __init__(self, api_key, url, project_id):
self.ls_client = ls.Client(url=url, api_key=api_key)
self.ls_project = self.ls_client.get_project(project_id)
self.prompts = {}
def on_llm_start(self, serialized, prompts, **kwargs):
self.prompts[str(kwargs["parent_run_id"] or kwargs["run_id"])] = prompts
def on_llm_end(self, response, **kwargs):
run_id = str(kwargs["parent_run_id"] or kwargs["run_id"])
prompts = self.prompts[run_id]
tasks = []
for prompt, generation in zip(prompts, response.generations):
tasks.append({'prompt': prompt, 'response': generation[0].text})
self.ls_project.import_tasks(tasks)
self.prompts.pop(run_id)This callback logs the queries and answers and directly inserts them into Label Studio. This provides an intuitive interface for examining, annotating, and evaluating the responses.
Step 3: Annotate the QA application’s performance
Once our data has landed in Label Studio, we have all the tools we need to understand and refine the data with our human expertise. There are many ways to refine your data, such as consensus gathering, applying filters, or even using other LLMs to evaluate your data.
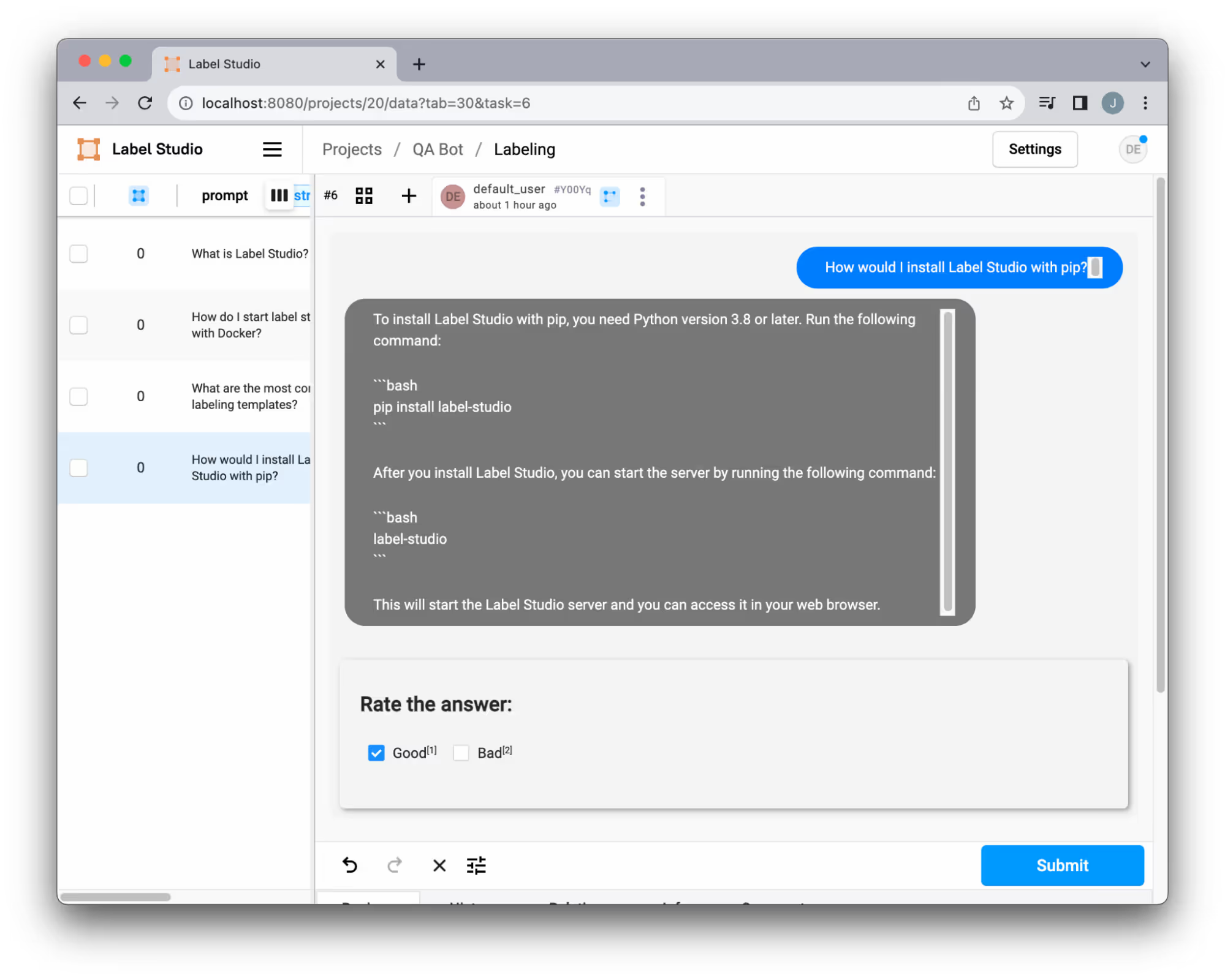
Our QA system utilizes a custom template to view chat interactions. The flexibility to tailor these templates to our unique requirements ensures a labeling experience perfectly aligned with our needs. Whether adding new categories, allowing response edits, or incorporating other customizations, the system offers extensive adaptability. Learn more about how to personalize templates.
Step 4: Gauging Quality
As we accumulate answered questions and accompanying annotations, we can begin measuring the quality of our system. This feedback loop gives us insight into how well our LLM application performs and where it needs tuning.
For example, we may want to know the general accuracy of our system. We can use the number of examples labeled “good” in our dataset with the simple formula:

We can simply view these numbers by filtering for the “good” results in the labeling interface to compute accuracy, or we can export the dataset for a more robust analysis.
We can export our data in a CSV format in the UI. Once we have our dataset, we can perform any type of data analysis on our QA system, such as computing the percentage of irrelevant questions, out-of-domain responses, and so on.
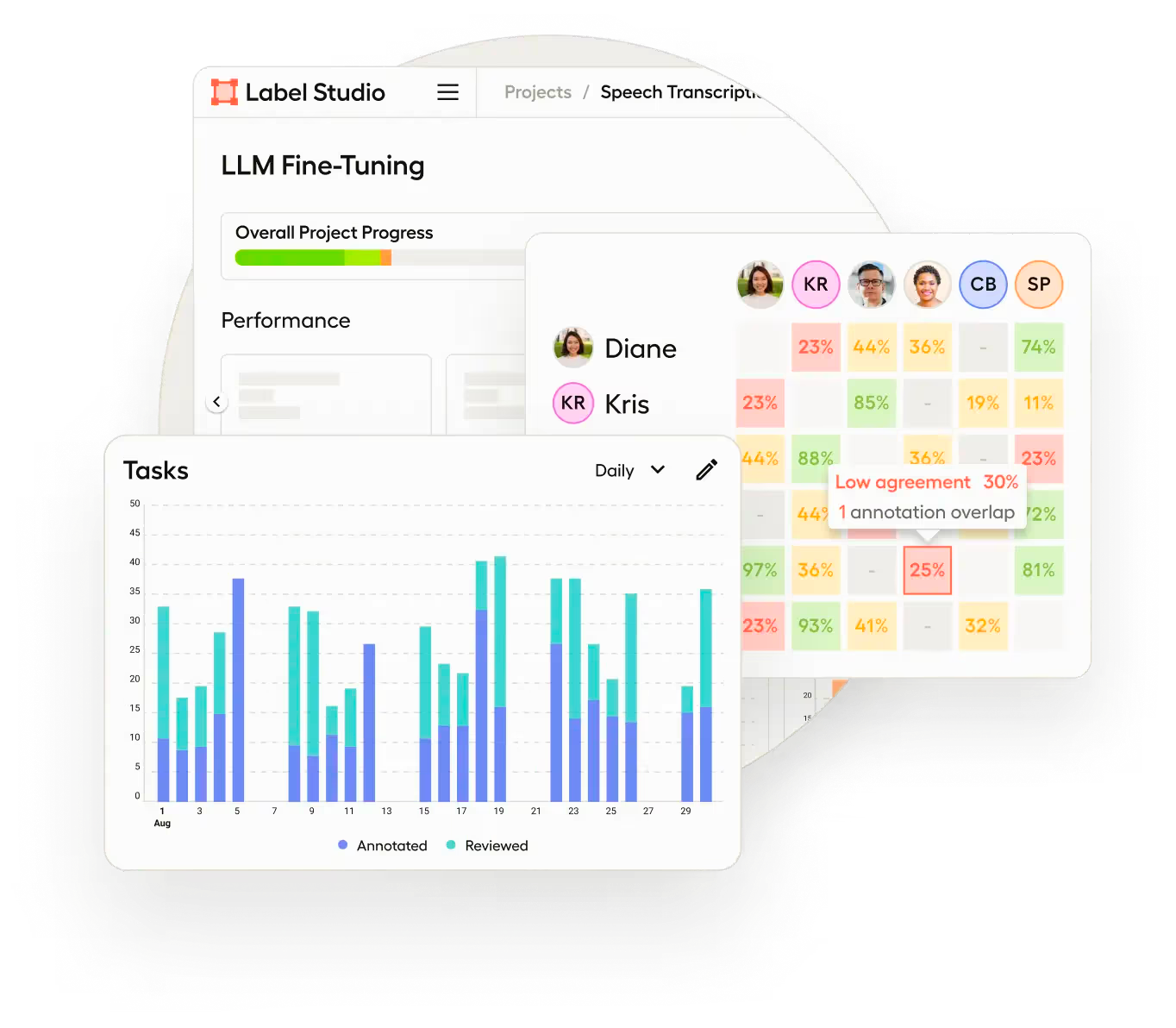
Many of these metrics and dashboards are built-in features of the enterprise version of Label Studio to support more robust labeling workflows, as shown below.
Step 5: Improve the system
The beauty of this iterative approach lies in its self-improving nature. As users engage with the system, we accrue invaluable feedback. We bolster the system’s contextual understanding by integrating positively reviewed ("good") responses into our document database. For more details on this snippet, see the full example on GitHub.
# Extract "good" examples and convert them to Documents
good_examples = extract_good_examples_from_jsonl(json_path)
docs = [Document(page_content=str(example), metadata={"source": json_path}) for example in good_examples]
# Add documents to the vector store and persist
vectorstore.add_documents(docs)
vectorstore.persist()
This approach can be advantageous to realize immediate improvements to our system, but this can become cumbersome. However, as our dataset grows larger and larger, we can incorporate other tuning techniques, such as fine-tuning the LLM or embeddings generator. Every user interaction, and every question and answer, becomes a valuable dataset. It paints a clearer picture of potential system gaps and general user pain points. Ultimately, this user-driven feedback loop fortifies our application, making it increasingly aligned with our domain and perpetually enhancing its response quality.
A Generative AI Workflow for Any QA System
At the end of the day, we have a generative AI workflow that can be used to tune any QA system. It demonstrates the power of combining cutting-edge technologies like LangChain and Label Studio with LLMs from OpenAI, resulting in a robust solution to taming bias and boosting the quality of language models.
As we embrace this workflow, we open doors to creating more nuanced, domain-specific applications that not only answer user questions accurately but also do so in a manner that aligns closely with the values and needs of our unique domains. The continuous improvement of our LLM applications is thus not just a goal but an ongoing process that we are committed to – one made possible through innovative tools and a steadfast dedication to quality.
Conclusion
In an era where large language models (LLMs) have changed the landscape of AI-driven applications, ensuring their quality and relevance has never been more crucial. The iterative approach we've discussed showcases the importance of fine-tuning these models to meet specific application requirements, particularly in overcoming inherent biases and ensuring domain-specific accuracy. This dynamic of quantity versus quality is at the forefront of making AI truly impactful in real-world scenarios. We've paved a promising way forward by employing Label Studio in tandem with LangChain and LLMs. Through continuous human feedback, iterative improvements, and domain-specific calibrations, we can ensure that our AI systems are powerful, precise, reliable, and aligned with user expectations.
Join the Label Studio Community!
Open source is about building communities, sharing knowledge, and innovating together. Label Studio invites you to be a part of this movement. Contribute to the project, learn from the community, and harness the power of collective wisdom. Together, let's fine-tune the future of AI and make technology more inclusive and adaptive.