TL;DR:
- The hard part of building reliable agentic systems is making sure the LLM has the appropriate context at each step. This includes both controlling the exact content that goes into the LLM, as well as running the appropriate steps to generate relevant content.
- Agentic systems consist of both workflows and agents (and everything in between).
- Most agentic frameworks are neither declarative or imperative orchestration frameworks, but rather just a set of agent abstractions.
- Agent abstractions can make it easy to get started, but they can often obfuscate and make it hard to make sure the LLM has the appropriate context at each step.
- Agentic systems of all shapes and sizes (agents or workflows) all benefit from the same set of helpful features, which can be provided by a framework, or built from scratch.
- LangGraph is best thought of as a orchestration framework (with both declarative and imperative APIs), with a series of agent abstractions built on top.
OpenAI recently released a guide on building agents which contains some misguided takes like the below:

This callout initially angered me, but after starting to write a response I realized: thinking about agent frameworks is complicated! There are probably 100 different agent frameworks, there are a lot of different axes to compare them on, sometimes they get conflated (like in this quote). There is a lot of hype, posturing, and noise out there. There is very little precise analysis or thinking being done about agent frameworks. This blog is our attempt to do so. We will cover:
- Background Info
- What is an agent?
- What is hard about building agents?
- What is LangGraph?
- Flavors of agentic frameworks
- “Agents” vs “workflows”
- Declarative vs non-declarative
- Agent abstractions
- Multi agent
- Common Questions
- What is the value of a framework?
- As the models get better, will everything become agents instead of workflows?
- What did OpenAI get wrong in their take?
- How do all the agent frameworks compare?
Throughout this blog I will make repeated references to a few materials:
- OpenAI’s guide on building agents (which I don’t think is particularly good)
- Anthropic’s guide on building effective agents (which I like a lot)
- LangGraph (our framework for building reliable agents)
Background info
Helpful context to set the stage for the rest of the blog.
What is an agent
There is no consistent definition of an agent, and they are often offered through different lenses.
OpenAI takes a higher level, more thought-leadery approach to defining an agent.
Agents are systems that independently accomplish tasks on your behalf.
I am personally not a fan of this. This is a vague statement that doesn’t really help me understand what an agent is. It’s just thought-leadership and not practical at all.
Compare this to Anthropic’s definition:
"Agent" can be defined in several ways. Some customers define agents as fully autonomous systems that operate independently over extended periods, using various tools to accomplish complex tasks. Others use the term to describe more prescriptive implementations that follow predefined workflows. At Anthropic, we categorize all these variations as agentic systems, but draw an important architectural distinction between workflows and agents:
Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
Agents, on the other hand, are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
I like Anthropic’s definition better for a few reasons:
- Their definition of an agent is much more precise and technical.
- They also make reference to the concept of “agentic systems”, and categorize both workflows and agents as variants of this. I love this.
Later in the blog post, Anthropic defines agents as “… typically just LLMs using tools based on environmental feedback in a loop.”
Despite their grandiose definition of an agent at the start, this is basically what OpenAI means as well.
These types of agents are parameterized by:
- The model to use
- The instructions (system prompt) to use
- The tools to use
You call the model in a loop. If/when it decides to call a tool, you run that tool, get some observation/feedback, and then pass that back into the LLM. You run until the LLM decides to not call a tool (or it calls a tool that triggers a stopping criteria).
Both OpenAI and Anthropic call out workflows as being a different design pattern than agents. The LLM is less in control there, the flow is more deterministic. This is a helpful distinction!
Both OpenAI and Anthropic explicitly call out that you do not always need agents. In many cases, workflows are simpler, more reliable, cheaper, faster, and more performant. A great quote from the Anthropic post:
When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all. Agentic systems often trade latency and cost for better task performance, and you should consider when this tradeoff makes sense.
When more complexity is warranted, workflows offer predictability and consistency for well-defined tasks, whereas agents are the better option when flexibility and model-driven decision-making are needed at scale.
OpenAI says something similar:
Before committing to building an agent, validate that your use case can meet these criteria clearly. Otherwise, a deterministic solution may suffice.
In practice, we see that most “agentic systems” are a combination of workflows and agents. This is why I actually hate talking about whether something is an agent, but prefer talking about how agentic a system is. h/t the great Andrew Ng for this way of thinking about things:
Rather than having to choose whether or not something is an agent in a binary way, I thought, it would be more useful to think of systems as being agent-like to different degrees. Unlike the noun “agent,” the adjective “agentic” allows us to contemplate such systems and include all of them in this growing movement.
What is hard about building agents?
I think most people would agree that building agents is hard. Or rather - building an agent as a prototype is easy, but a reliable one, that can power business-critical applications? That is hard.
The tricky part is exactly that - making it reliable. You can make a demo that looks good on Twitter easily. But can you run it to power a business critical application? Not without a lot of work.
We did a survey of agent builders a few months ago and asked them: “What is your biggest limitation of putting more agents in production?” The number one response by far was “performance quality” - it’s still really hard to make these agents work.

What causes agents to perform poorly sometimes? The LLM messes up.
Why does the LLM mess up? Two reasons: (a) the model is not good enough, (b) the wrong (or incomplete) context is being passed to the model.
From our experience, it is very frequently the second use case. What causes this?
- Incomplete or short system messages
- Vague user input
- Not having access to the right tools
- Poor tool descriptions
- Not passing in the right context
- Poorly formatted tool responses
As we discuss agent frameworks, it’s helpful to keep this in mind. Any framework that makes it harder to control exactly what is being passed to the LLM is just getting in your way. It’s already hard enough to pass the correct context to the LLM - why would you make it harder on yourself?
What is LangGraph
LangGraph is an event-driven framework for building agentic systems. The two most common ways of using it are through:
- a declarative, graph-based syntax
- agent abstractions (built on top of the lower level framework)
LangGraph also supports a functional API, as well as the underlying event-driven API. There exist both Python and Typescript variants.
Agentic systems can be represented as nodes and edges. Nodes represent units of work, while edges represent transitions. Nodes and edges are nothing more than normal Python or TypeScript code - so while the structure of the graph is represented in a declarative manner, the inner functioning of the graph’s logic is normal, imperative code. Edges can be either fixed or conditional. So while the structure of the graph is declarative, the path through the graph can be completely dynamic.
LangGraph comes with a built-in persistence layer. This enables fault tolerance, short-term memory, and long-term memory.
This persistence layer also enables “human-in-the-loop” and “human-on-the-loop” patterns, such as interrupt, approve, resume, and time travel.
LangGraph has built-in support for streaming: of tokens, node updates, and arbitrary events.
LangGraph integrates seamlessly with LangSmith for debugging, evaluation, and observability.
Flavors of agentic frameworks
Agentic frameworks are different across a few dimensions. Understanding - and not conflating - these dimensions is key to being able to properly compare agentic frameworks.
Workflows vs Agents
Most frameworks contain higher level agent abstractions. Some frameworks include some abstraction for common workflows. LangGraph is a low level orchestration framework for building agentic systems. LangGraph supports workflows, agents, and anything in-between. We think this is crucial. As mentioned, most agentic systems in production are a combination of workflows and agents. A production-ready framework needs to support both.
Let’s remember what is hard about building reliable agents - making sure the LLM has the right context. Part of why workflows are useful is that they make it easy to pass the right context to LLMs. You decide exactly how the data flows.
As you think about where on spectrum of “workflow” to “agent” you want to build your application, there are two things to think about:
- Predictability vs agency
- Low floor, high ceiling
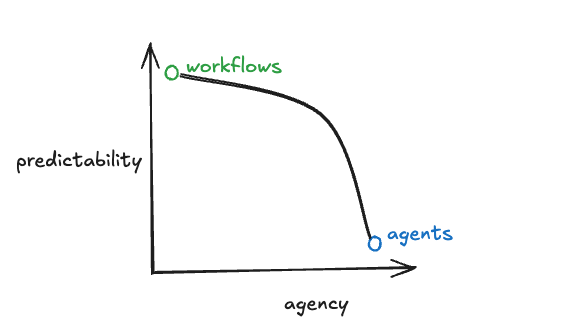
Predictability vs agency
As your system becomes more agentic, it will become less predictable.
Sometimes you want or need your system to be predictable - for user trust, regulatory reasons, or other.
Reliability does not track 100% with predictability, but in practice they can be closely related.
Where you want to be on this curve is pretty specific to your application. LangGraph can be used to build applications anywhere on this curve, allowing you to move to the point on the curve that you want to be.
High floor, low ceiling
When thinking about frameworks, it can be helpful to think about their floors and ceilings:
- Low floor: A low floor framework is beginner-friendly and easy to get started with
- High floor: A framework with a high floor means it has a steep learning curve and requires significant knowledge or expertise to begin using it effectively.
- Low ceiling: A framework with a low ceiling means it has limitations on what can be accomplished with it (you will quickly outgrow it).
- High ceiling: A high ceiling framework offers extensive capabilities and flexibility for advanced use cases (it grows with you?).
Workflow frameworks offer a high ceiling, but come with a high floor - you have to write lot of the agent logic yourself.
Agent frameworks are low floor, but low ceiling - easy to get started with, but not enough for non-trivial use cases.
LangGraph aims to have aspects that are low floor (built-in agent abstractions that make it easy to get started) but also high ceiling (low-level functionality to achieve advanced use cases).
Declarative vs non-declarative
There are benefits to declarative frameworks. There are also downsides. This is a seemingly endless debate among programmers, and everyone has their own preferences.
When people say non-declarative, they are usually implying imperative as the alternative.
Most people would describe LangGraph as a declarative framework. This is only partially true.
First - while the connections between the nodes and edges are done in a declarative manner, the actual nodes and edges are nothing more than Python or TypeScript functions. Therefore, LangGraph is kind of a blend between declarative and imperative.
Second - we actually support other APIs besides the recommended declarative API. Specifically, we support both functional and event-driven APIs. While we think the declarative API is a useful mental model, we also recognize it is not for everyone.
A common comment about LangGraph is that is like Tensorflow (a declarative deep learning framework), while frameworks like Agents SDK are like Pytorch (an imperative deep learning framework).
This is just incorrect. Frameworks like Agents SDK (and original LangChain, CrewAI, etc) are neither declarative or imperative - they are just abstractions. They have an agent abstraction (a Python class) and it contains a bunch of internal logic that runs the agent. They’re not really orchestration frameworks. They are just abstractions.
Agent Abstractions
Most agent frameworks contain an agent abstraction. They usually start as a class that involves a prompt, model, and tools. Then they add in a few more parameters… then a few more… then even more. Eventually you end up with a litany of parameters that control a multitude of behaviors, all abstracted behind a class. If you want to see what’s going on, or change the logic, you have to go into the class and modify the source code.
We learned this the hard way. This was the issue with the original LangChain chains and agents. They provided abstractions that got in the way. One of those original abstractions from two years ago was an agent class that took in a model, prompt, and tools. This isn’t a new concept. It didn’t provide enough control back then, and it doesn’t now.
To be clear, there is some value in these agent abstractions. It makes it easier to get started. But I don’t think these agent abstractions are good enough to build reliable agents yet (and maybe ever).
We think the best way to think about these agent abstractions is like Keras. They provide higher level abstractions to get started easily. But it’s crucial to make sure they are built on top of a lower level framework so you don’t outgrow it.
That is why we have built agent abstractions on top of LangGraph. This provides an easy way to get started with agents, but if you need to escape to lower-level LangGraph you easily can.
Multi Agent
Oftentimes agentic systems won’t just contain one agent, they will contain multiple. OpenAI says in their report:
For many complex workflows, splitting up prompts and tools across multiple agents allows for improved performance and scalability. When your agents fail to follow complicated instructions or consistently select incorrect tools, you may need to further divide your system and introduce more distinct agents.
There a bunch of ways to do this! Handoffs are one way. This is an agent abstraction from Agents SDK that I actually quite like.
But the best way for these agents to communicate can sometimes be workflows. Take all the workflow diagrams in Anthropic’s blog post, and replace the LLM calls with agents. This blend of workflows and agents often gives the best reliability.
Again - agentic systems are not just workflows, or just an agent. They can be - and often are - a combination of the two. As Anthropic points out in their blog post:
Combining and customizing these patterns
These building blocks aren't prescriptive. They're common patterns that developers can shape and combine to fit different use cases.
Common Questions
Having defined and explored the different axes that you should be evaluating frameworks on, let’s now try to answer some common questions.
What is the value of a framework?
We often see people questioning whether they need a framework to build agentic systems. What value can agent frameworks provide?
Agent abstractions
Frameworks are generically useful because they contain useful abstractions which make it easy to get started and provide a common way for engineers to build, making it easier to onboard and maintain projects. As mentioned above, there are real downsides to agent abstractions as well. For most agent frameworks, this is the sole value they provide. We worked really hard to make sure this was not case for LangGraph.
Short term memory
Most agentic applications today involve some sort of multi-turn (e.g. chat) component. LangGraph provides production ready storage to enable multi-turn experiences (threads).
Long term memory
While still early, I am very bullish on agentic systems learning from their experiences (e.g. remembering things across conversations). LangGraph provides production ready storage for cross-thread memory.
Human-in-the-loop
Many agentic systems are made better with some human-in-the-loop component. Examples include getting feedback from the user, approving a tool call, or editing tool call arguments. LangGraph provides built in support to enable these workflows in a production system.
Human-on-the-loop
Besides allowing the user to affect the agent as it is running, it can also be useful to allow the user to inspect the agent’s trajectory after the fact, and even go back to earlier steps and then rerun (with changes) from there. We call this human-on-the-loop, and LangGraph provides built in support for this.
Streaming
Most agentic applications take a while to run, and so providing updates to the end user can be critical for providing a good user experience. LangGraph provides built in streaming of tokens, graph steps, and arbitrary streams.
Debugging/observability
The hard part of building reliable agents is making sure you are passing the right context to the LLM. Being able to inspect the exact steps taken by an agent, and the exact inputs/outputs at each step is crucial for building reliable agents. LangGraph integrates seamlessly with LangSmith for best in class debugging and observability. Note: AI observability is different from traditional software observability (this deserves a separate post).
Fault tolerance
Fault tolerance is a key component of traditional frameworks (like Temporal) for building distributed applications. LangGraph makes fault tolerance easier with durable workflows and configurable retries.
Optimization
Rather than tweaking prompts manually by hand, it can sometimes be easier to define an evaluation dataset and then automatically optimize your agent based on this. LangGraph currently does not support this out of the box - we think it is a little early for this. But I wanted to include this because I think it is an interesting dimension to consider, and something we are constantly keeping our eyes on. dspy is the best framework for this currently.
So - do you really need an agentic framework?
If your application does not require all of these features, and/or if you want to build them yourself, then you may not need one. Some of them (like short term memory) aren’t terribly complicated. Others of them (like human-on-the-loop, or LLM specific observability) are more complicated.
And regarding agent abstractions: I agree with what Anthropic says in their post:
If you do use a framework, ensure you understand the underlying code. Incorrect assumptions about what's under the hood are a common source of customer error.
As the models get better, will everything become agents instead of workflows?
One common argument in favor of agents (compared to workflows) is that while they don’t work now, they will work in the future, and therefore you will just need the simple, tool-calling agents.
I think multiple things can be true:
- The performance of these tool-calling agents will rise
- It will still really important to be able to control what goes into the LLM (garbage in, garbage out)
- For some applications, this tool calling loop will be enough
- For other applications, workflows will just be simpler, cheaper, faster, and better
- For most applications, the production agentic system will be a combination of workflows and agents
I don’t think OpenAI or Anthropic would debate any of these points? From Anthropic’s post:
When building applications with LLMs, we recommend finding the simplest solution possible, and only increasing complexity when needed. This might mean not building agentic systems at all. Agentic systems often trade latency and cost for better task performance, and you should consider when this tradeoff makes sense.
And from OpenAI's post:
Before committing to building an agent, validate that your use case can meet these criteria clearly. Otherwise, a deterministic solution may suffice.
Will there be applications where this simple tool calling loop will be enough? I think this will likely only be true if you are using a model trained/finetuned/RL’d on lots of data that is specific to your use case. This can happen in two ways:
- Your task is unique. You gather a lot of data and train/finetune/RL your own model.
- Your task is not unique. The large model labs are training/finetuning/RL’ing on data representative of your task.
(Side note: if I was building a vertical startup in an area where my task was not unique, I would be pretty worried about the long term viability of my startup).
Your task is unique
I would bet that most use cases (certainly most enterprise use cases) fall into this category. How AirBnb handles customer support is different from how Klarna handles customer support which is different from how Rakuten handles customer support. There is a ton of subtlety in these tasks. Sierra - a leading agent company in the customer support space - is not building a single customer support agent, but rather a customer support agent platform:
The Sierra Agent SDK enables developers to use a declarative programming language to build powerful, flexible agents using composable skills to express procedural knowledge
They need to do this because each company’s customer support experience is unique enough where a generic agent is not performant enough.
One example of an agent that is a simple tool calling loop using a model trained on a specific task: OpenAI’s Deep Research. So it can be done, and it can produce amazing agents.
If you can train a SOTA model on your specific task - then yes, you probably don’t need a framework that enables arbitrary workflows, you’ll just use a simple tool calling loop. In this case, agents will be preferred over workflows.
A very open question in my mind is: how many agent companies will have the data, tools, or knowledge to train a SOTA model for their task? At this exact moment, I think only the large model labs are able to do this. But will that change? Will a small vertical startup be able to train a SOTA model for their task? I am very interested in this question. If you are currently doing this - please reach out!
Your task is not unique
I think some tasks are generic enough that the large model labs will be able to provide models that are good enough to do the simple tool-calling loop on these non-generic tasks.
OpenAI released their Computer Use model via the API, which is a model finetuned on generic computer use data aiming to be good enough at that generic task. (Side note: I don’t think it is close to good enough yet).
Code is an interesting example of this. Coding is relatively generic, and coding has definitely been a break out use case for agents so far. Claude code and OpenAI’s Codex CLI are two examples of coding agents that use this simple tool calling loop. I would bet heavily that the base models are trained on lots of coding data and tasks (see evidence here that Anthropic does this).
Interestingly - as the general models are trained on this data, how much does the exact shape of this data matter? Ben Hylak had an interesting tweet the other day that seemed to resonate with folks:
models don't know how to use cursor anymore.
they're all being optimized for terminal. that's why 3.7 is and o3 are so awful in Cursor, and so amazing outside of it.
This could suggest two things:
- Your task has to be very very close to the task the general models are trained on. The less similar your task is, the less likely it is that the general models will be good enough for your use case.
- Training the general models on other specific tasks may decrease performance on your task. I’m sure there is just as much (if not more) data similar to Cursor’s use case used to train the new models. But if there is this influx of new data of a slightly different shape, it outweighs any other type of data. This implies it is currently hard for the general models to be really amazing at a large number of tasks.
What did OpenAI get wrong in their take?
If we revisit OpenAI's stance, we find it to be premised on false dichotomies that conflate different dimensions of "agentic frameworks" in order to inflate the value of their singular abstraction. Specifically, it conflates “declarative vs imperative” with “agent abstractions” as well as “workflows vs agents”.
Let's break down specific parts I take issue with:

”Declarative vs non-declarative graphs”
LangGraph is not fully declarative - but it’s declarative enough so that’s not my main gripe. My main gripe would be that “non-declarative” is doing a lot of work and misleading. Normally when people criticize declarative frameworks they would prefer a more imperative framework. But Agents SDK is NOT an imperative framework. It’s an abstraction. A more proper title would be “Declarative vs imperative” or “Do you need an orchestration framework” or “Why agent abstractions are all you need” or “Workflows vs Agents” depending on what they want to argue (they seem to argue both below).
”this approach can quickly become cumbersome and challenging as workflows grow more dynamic and complex”
This doesn’t have anything to do with declarative or non-declarative. This has everything to do with workflows vs agents. You can easily express the agent logic in Agents SDK as a declarative graph, and that graph is just as dynamic and flexible as Agents SDK.
And on the point of workflows vs agents. A lot of workflows do not require this level of dynamism and complexity. Both OpenAI and Anthropic acknowledge this. You should use workflows when you can use workflows. Most agentic systems are a combination. Yes, if a workflow is really dynamic and complex then use an agent. But don’t use an agent for everything. OpenAI literally says this earlier in the paper.
”often necessitating the learning of specialized domain-specific languages”
Again - Agents SDK is not an imperative framework. It is an abstraction. It also has a domain specific language (it’s abstractions). I would argue that having to learn and work around Agents SDK abstractions is, at this point in time, worse than having to learn LangGraph abstractions. Largely because the hard thing about building reliable agents is making sure the agent has the right context, and Agents SDKs obfuscates that WAY more than LangGraph.
"more flexible"
This is just strictly not true. It’s the opposite of the truth. Everything you can do with Agents SDK you can do with LangGraph. Agents SDK only lets you do 10% of what you can do with LangGraph.
“code-first”
With Agents SDK you write their abstractions. With LangGraph you write a large amount of normal code. I don’t see how Agents SDK is more code first.
”using familiar programming constructs”
With Agents SDK you have to learn a whole new set of abstractions. With LangGraph you write a large amount of normal code. What is more familiar than that?
”enabling more dynamic and adaptable agent orchestration”
Again - this doesn’t have to with declarative vs non-declarative. This has to do with workflows vs agents. See above point.
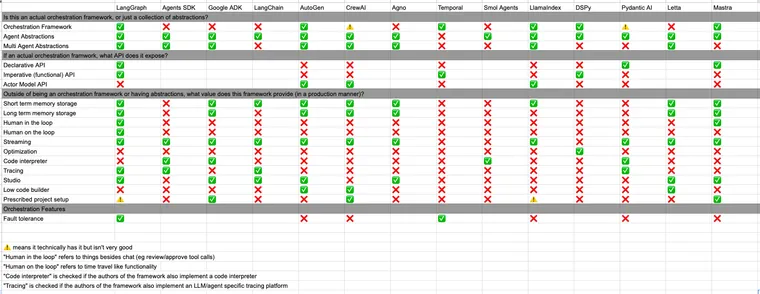
Comparing Agent Frameworks
We've talked about a lot of different components of agent frameworks:
- Are they flexible orchestration layer, or just an agent abstraction?
- If they are a flexible orchestration layer, are they declarative or otherwise?
- What features (aside from agent abstractions) does this framework provide?
I thought it would be fun to try to list out these dimensions in an spreadsheet. I tried to be as impartial as possible about this (I asked for - and got - a lot of good feedback from Twitter!).
This currently contains comparisons to Agents SDK, Google's ADK, LangChain, Crew AI, LlamaIndex, Agno AI, Mastra, Pydantic AI, AutoGen, Temporal, SmolAgents, DSPy.
If I left out a framework (or got something wrong about a framework) please leave a comment!
Conclusion
- The hard part of building reliable agentic systems is making sure the LLM has the appropriate context at each step. This includes both controlling the exact content that goes into the LLM, as well as running the appropriate steps to generate relevant content.
- Agentic systems consist of both workflows and agents (and everything in between).
- Most agentic frameworks are neither declarative or imperative orchestration frameworks, but rather just a set of agent abstractions.
- Agent abstractions can make it easy to get started, but they can often obfuscate and make it hard to make sure the LLM has the appropriate context at each step.
- Agentic systems of all shapes and sizes (agents or workflows) all benefit from the same set of helpful features, which can be provided by a framework, or built from scratch.
- LangGraph is best thought of as a orchestration framework (with both declarative and imperative APIs), with a series of agent abstractions built on top.