Editor's note: We're excited to share this blogpost as it covers several of the advanced retrieval strategies we introduced in the past month, specifically a lot of the ones that rely on changing the ingestion step. A lot of these advanced retrieval strategies can be summarized as changing how indexing of documents is done to retain some concept of hierarchy. Neo4j is an exciting database to use for these tasks since it can represent these hierarchies as part of the graph. This also allows you to switch between indexing strategies pretty easily.
Tomaz has implemented a single LangChain template that contains four different RAG strategies. Check it out here:
Retrieval-augmented generation applications seem to be the “Hello World” of AI applications. Nowadays, you can implement a “Chat with your PDF” application in only a couple of minutes due to the help of LLM framework libraries like LangChain.
“Chat with your PDF” applications typically rely on vector similarity search to retrieve relevant information, which are then fed to an LLM to generate a final answer that is returned to a user.
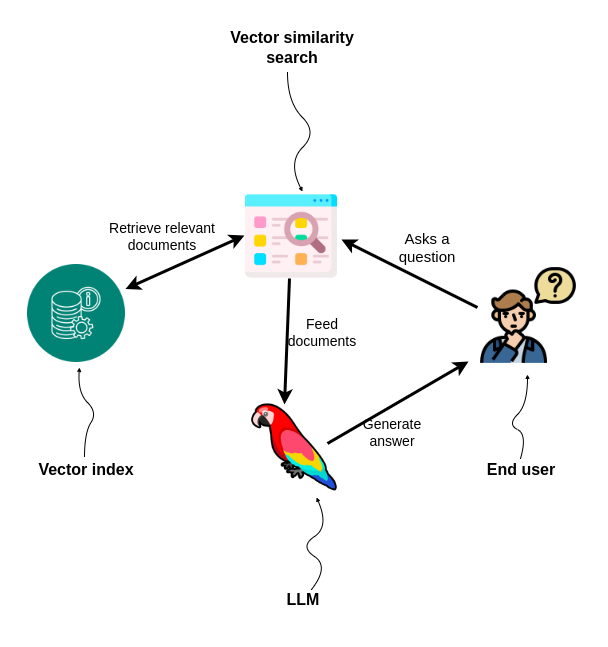
Lately, it is becoming more and more obvious that naive vector similarity search might not be accurate enough for all use cases. For example, we have seen the introduction of step-back approach to prompting, which emphasizes the importance of taking a step back from the immediate details of a task to focus on a higher-level abstraction.
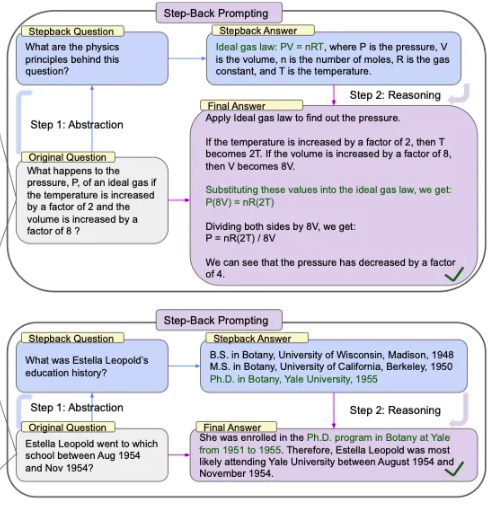
The step-back prompting technique is based on the observation that directly addressing intricate tasks can lead to errors, especially when there are numerous specifics to consider. Instead of plunging straight into the complexities, the model first prompts itself to ask a more generic question that encapsulates the core essence of the original query. By focusing on this broader concept or principle, it can retrieve more relevant and comprehensive facts. Once armed with this foundational knowledge, the model can then proceed to reason and deduce the answer to the specific task at hand.
On the other hand, we have also seen the introduction of so-called parent document retrievers, where the hypothesis is that directly using a document’s vector might not be efficient.
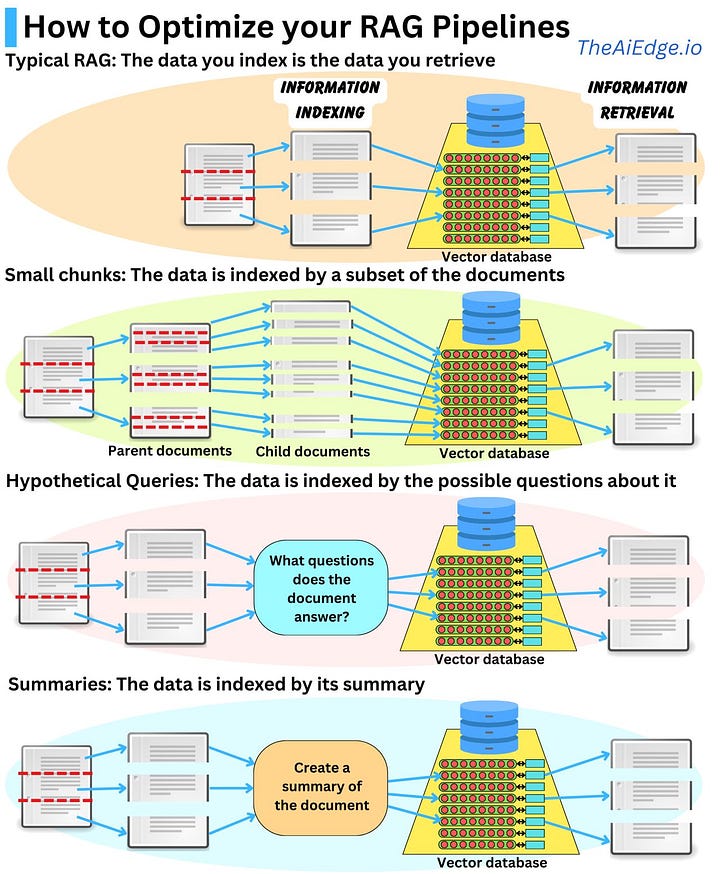
Large documents can be split into smaller chunks, where the smaller chunks are converted to vectors, improving indexing for similarity searches. Although these smaller vectors better represent specific concepts, the original large document is retrieved as it provides better context for answering questions. Similarly, you can use an LLM to generate questions the document answers. The document is then indexed by these question embeddings, providing closer similarity with user questions. In both examples, the full parent document is retrieved to provide complete context for answers, hence the name “Parent Document Retriever”.
In this blog post, you will learn how to use the neo4j-advanced-rag template and host it using LangServe.
Neo4j Environment Setup
You need to set up a Neo4j 5.11 or greater to follow along with the examples in this blog post. The easiest way is to start a free instance on Neo4j Aura, which offers cloud instances of the Neo4j database. Alternatively, you can also set up a local instance of the Neo4j database by downloading the Neo4j Desktop application and creating a local database instance.
from langchain.graphs import Neo4jGraph
url = "neo4j+s://databases.neo4j.io"
username ="neo4j"
password = ""
graph = Neo4jGraph(
url=url,
username=username,
password=password
)Neo4j Advanced RAG template
LangChain Templates offers a collection of easily deployable reference architectures that anyone can use. This is a new way to create, share, maintain, download, and customize chains and agents. They are all in a standard format that allows them to easily be deployed with LangServe, allowing you to easily get production-ready APIs and a playground for free.
The neo4j-advanced-rag template allows you to balance precise embeddings and context retention by implementing advanced retrieval strategies.
Available Strategies
1. Typical RAG:
- Traditional method where the exact data indexed is the data retrieved.
2. Parent retriever:
- Instead of indexing entire documents, data is divided into smaller chunks, referred to as Parent and Child documents.
- Child documents are indexed for better representation of specific concepts, while parent documents are retrieved to ensure context retention.
3. Hypothetical Questions:
- Documents are processed to generate potential questions they might answer.
- These questions are then indexed for better representation of specific concepts, while parent documents are retrieved to ensure context retention.
4. Summaries:
- Instead of indexing the entire document, a summary of the document is created and indexed.
- Similarly, the parent document is retrieved in a RAG application.
To be able to use LangChain templates, you should first install the LangChain CLI:
pip install -U "langchain-cli[serve]"Retrieving the LangChain template is then as simple as executing the following line of code:
langchain app new my-app --package neo4j-advanced-ragThis code will create a new folder called my-app, and store all the relevant code in it. Think of it as a “git clone” equivalent for LangChain templates. This will construct the following structure in your filesystem.
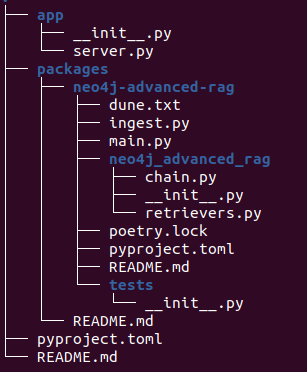
There are two top-level folders created:
- App: stores the FastAPI server code
- Packages: stores all the templates that you selected to use in this application. Remember, you can use multiple templates in a single application
Every template is a standalone project with its own poetry file, readme, and potentially also an ingest script, which you can use to populate the database. In the neo4j-advanced-rag template, the ingest script will construct a small graph based on the information from the Dune wikipedia page. Before running, you need to make sure to add relevant environment variables:
export OPENAI_API_KEY=sk-..
export NEO4J_USERNAME=neo4j
export NEO4J_PASSWORD=password
export NEO4J_URI=bolt://localhost:7687Make sure to change the environment variables to appropriate values. Then, you can run the ingest script with the following command.
python ingest.pyThe ingest can take a minute as we use the LLM to generate hypothetical questions and summaries. If you inspect the generated graph in Neo4j Browser, you should get a similar visualization:
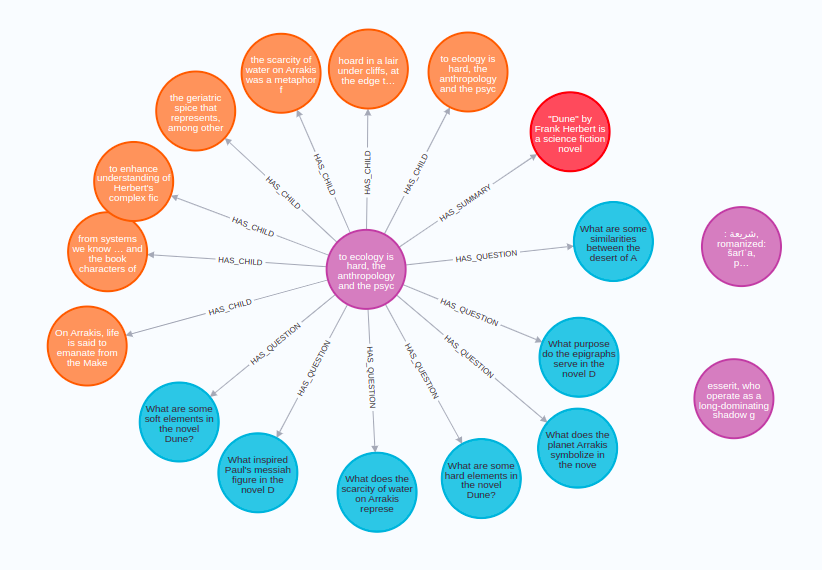
The purple nodes are the parent documents, which have a length of 512 tokens. Each parent document has multiple child nodes (orange) that contain a subsection of the parent document. Additionally, the parent nodes also have potential questions represented as blue nodes and a single summary node in red. As we have all the data needed for different strategies in a single store, we can easily compare the results of using different advanced retrieval strategies in the Playground application. One thing you need to do is to change the server.py to include the neo4j-advanced-rag template as an endpoint.
from fastapi import FastAPI
from langserve import add_routes
from neo4j_advanced_rag import chain as neo4j_advanced_chain
app = FastAPI()
# Add this
add_routes(app, neo4j_advanced_chain, path="/neo4j-advanced-rag")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)You can now serve this template by executing the following line of code in the root application directory.
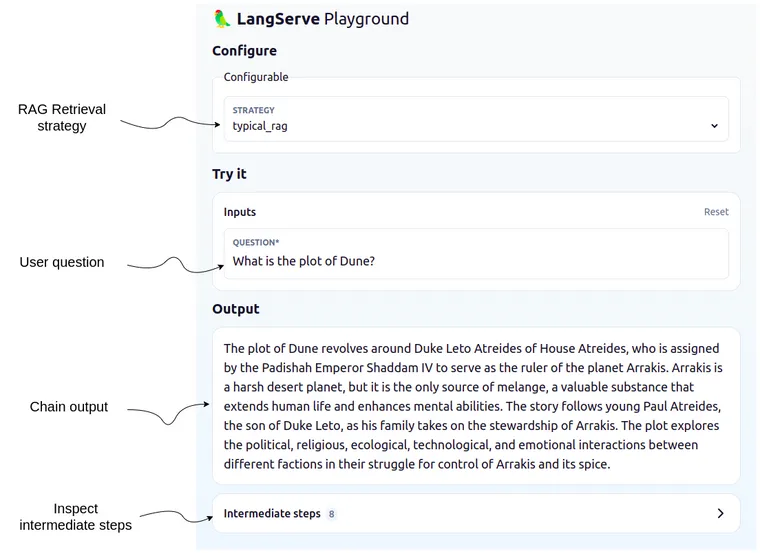
langchain serveFinally, you can open the playground application in your browser and compare different advanced RAG retrieval approaches.
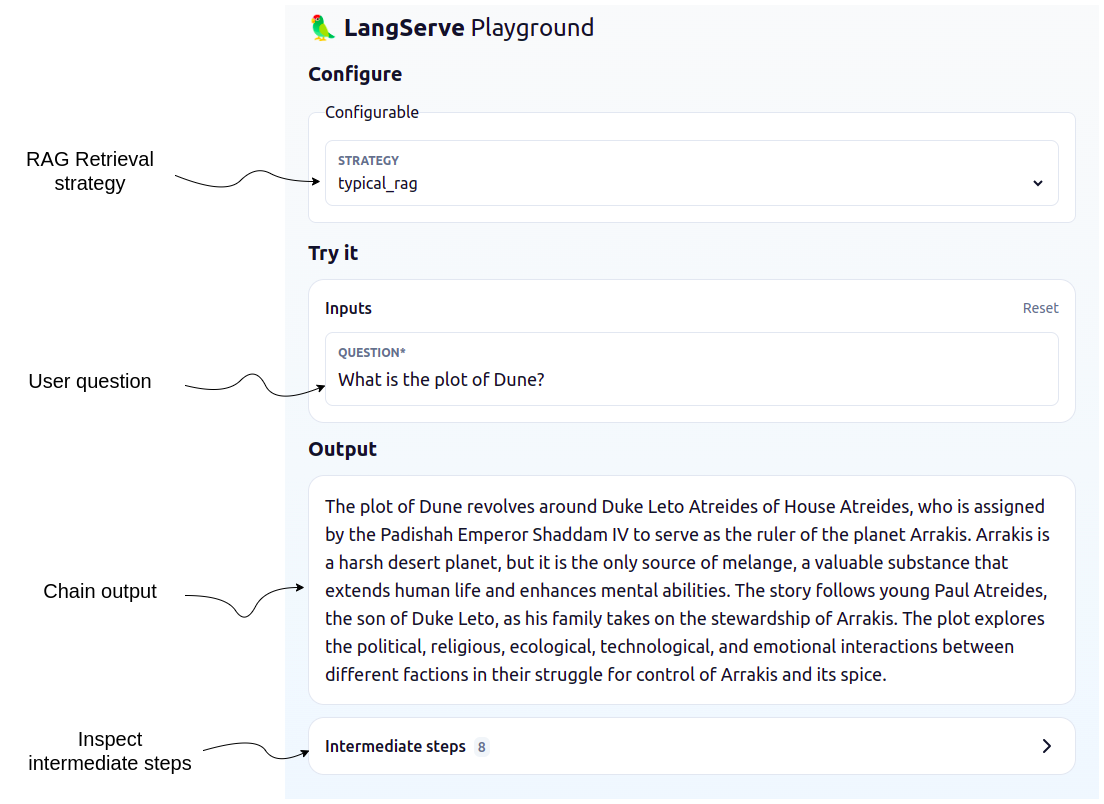
The playground is really nice as it offers a nice user interface to test out and inspect various LangChain Templates. For example, you can expand the “Intermediate steps” and inspect which documents were passed to the LLM, what is in the prompt, and all the other details of a chain.
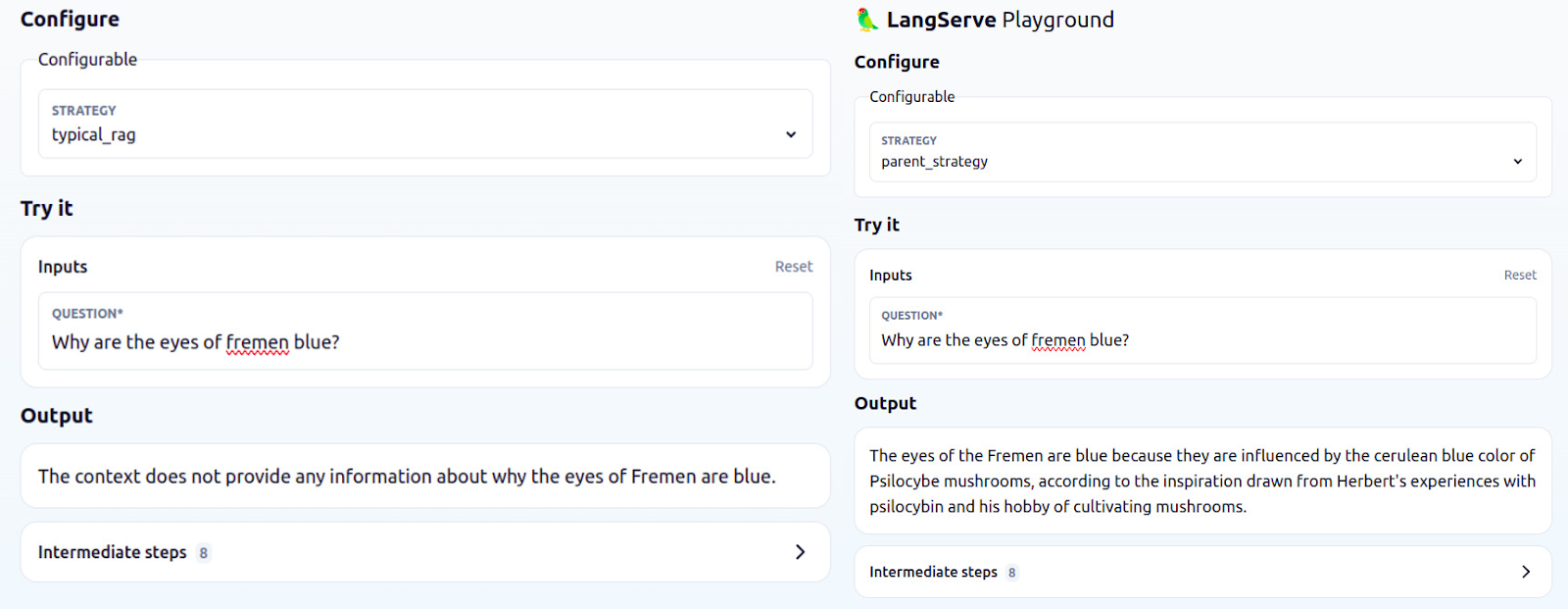
Since the strategy can be selected in the dropdown menu, you can easily compare how the output differs based on the selected retrieval strategy (or inspect documents in the Intermediate steps section).
Summary
In today’s RAG applications, the ability to retrieve accurate and contextual information from a large text corpus is crucial. The traditional approach to vector similarity search, while powerful, might sometimes overlook the specific context when longer text is embedded. By splitting longer documents into smaller vectors and indexing these for similarity, we can increase the retrieval accuracy while retaining the contextual information of parent documents to generate the answers with LLMs. Similarly, we can use LLMs to generate hypothetical questions or summaries of text and index those instead but still return the text of the parent document.
Test it out and let us know how it goes!