
Note: This post assumes some familiarity with LangChain and is moderately technical.
💡 TL;DR: We’ve introduced a new abstraction and a new document Retriever to facilitate the post-processing of retrieved documents. Specifically, the new abstraction makes it easy to take a set of retrieved documents and extract from them only the information relevant to the given query.
Introduction
Many LLM-powered applications require some queryable document storage that allows for the retrieval of application-specific information that's not already baked into the LLM.
Suppose you wanted to create a chatbot that could answer questions about your personal notes. One simple approach is to embed your notes in equally-sized chunks and store the embeddings in a vector store. When you ask the system a question, it embeds your question, performs a similarity search over the vector store, retrieves the most relevant documents (chunks of text), and appends them to the LLM prompt.
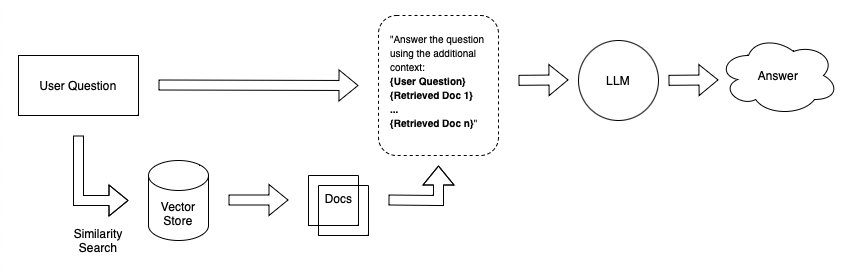
Problem
One problem with this approach is that when you ingest data into your document storage system, you often don’t know what specific queries will be used to retrieve those documents. In our notes Q&A example, we simply partitioned our text into equally-sized chunks. That means that when we get a specific user question and retrieve a document, even if the document has some relevant text it likely has some irrelevant text as well.
Inserting irrelevant information into the LLM prompt is bad because:
- It might distract the LLM from the relevant information
- It takes up precious space that could be used to insert other relevant information.
Solution
To help with this we’ve introduced a DocumentCompressor abstraction which allows you to run compress_documents(documents: List[Document], query: str) on your retrieved documents. The idea is simple: instead of immediately returning retrieved documents as-is, we can compress them using the context of the given query so that only the relevant information is returned. “Compressing” here refers to both compressing the contents of an individual document and filtering out documents wholesale.
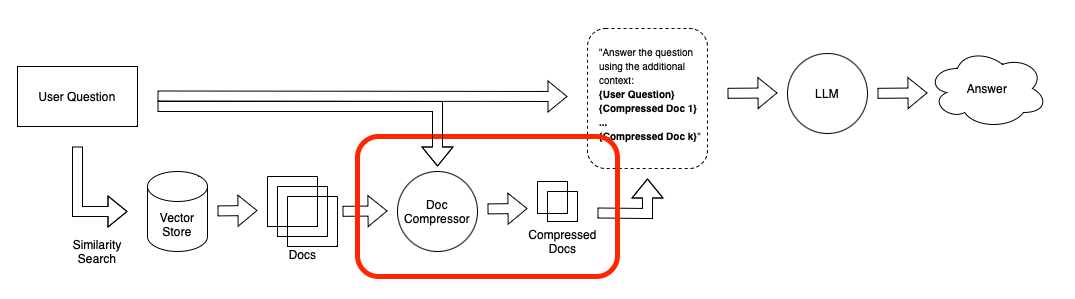
The goal of compressors is to make it easy to pass only the relevant information to the LLM. By doing this, it also enables you to pass along more information to the LLM, since in the initial retrieval step you can focus on recall (e.g. by increasing the number of documents returned) and let the compressors handle precision.
Features
We’ve implemented a couple new features in the LangChain Python package:
- A set of DocumentCompressors that you can use out of the box.
- A
ContextualCompressionRetrieverwhich wraps another Retriever along with a DocumentCompressor and automatically compresses the retrieved documents of the base Retriever.
Some example DocumentCompressors:
- The
LLMChainExtractoruses an LLMChain to extract from each document only the statements that are relevant to the query. - The
EmbeddingsFilterembeds both the retrieved documents and the query and filters out any documents whose embeddings aren’t sufficiently similar to the embedded query. On it’s own this compressor does something very similar to most VectorStore retrievers, but it becomes more useful as a component in… - … the
DocumentCompressorPipeline, which makes it easy to create a pipeline of transformations and compressors and run them in sequence. A simple example of this is you may want to combine aTextSplitterand anEmbeddingsFilterto first break up your documents into smaller pieces and then filter out the split documents that are no longer relevant.
You can try these out with any existing Retriever (whether VectorStore based or otherwise) with something like:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
# base_retriever defined somewhere above...
compressor = LLMChainExtractor.from_llm(OpenAI(temperature=0))
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
contextual_retriever.get_relevant_documents("insert query here")
Head to the walkthrough here to get started!