
Editor's Note: This post was written by Andrew Kean Gao through LangChain's Student Hacker in Residence Program.
Brief Overview
Tuna is a no-code tool for quickly generating LLM fine-tuning datasets from scratch. This enables anyone to create high-quality training data for fine-tuning large language models like the LLaMas. There is both a web interface (Streamlit) and a Python script (Repl.it, recommended for speed).
You provide an input CSV file of text data that will be individually sent to OpenAI as context to generate prompt-completion pairs from. This means that there is minimized hallucination since we feed directly in-context into GPT the information we want it to write prompt-completion pairs about!
Repl.it template: https://replit.com/@olafblitz/tuna-asyncio?v=1
Streamlit web interface: https://tunafishv1.olafblitz.repl.co/

Sample inputs for Tuna, which are ground-truth contexts/information that Tuna will send to OpenAI for a GPT model to draw from.

Sample outputs from Tuna, which could be used for fine-tuning an LLM for RAG
What is Fine-Tuning and When is it Useful?
Fine-tuning is the technique of taking a pre-trained large language model (LLM) like GPT-3.5-turbo or LLaMa-2-7b and training it further on a specific task or dataset. It is also known as transfer learning. This adapts the model to a new domain or specific purpose. Fine-tuning is used to specialize a large language model for a particular application. For example, you could fine-tune GPT-3 on a dataset of legal documents to create a model optimized for legal writing. As another example, LLaMa-2-7b-chat is a fine-tuned version of LLaMa-2-7b that is intended to be better at replying in a conversational format.
If you are curious to learn more about how fine-tuning works, here are some nice tutorials on how to fine-tune a large language model:
- https://www.datacamp.com/tutorial/fine-tuning-llama-2
- https://lightning.ai/pages/community/tutorial/accelerating-llama-with-fabric-a-comprehensive-guide-to-training-and-fine-tuning-llama/
- https://www.mlexpert.io/machine-learning/tutorials/alpaca-fine-tuning
Fine-tuning is useful because you can get a model to be more predictable and constrain the range of potential outputs. For instance, you may want your model to always respond with a correctly JSON-formatted list. Or, you may want your model to be very polite. Fine-tuning lets you perturb the model weights so it is more likely to do what you want. For instance, you could fine-tune a model to talk more like Kim Kardashian by default. Fine-tuning can also improve the performance of smaller LLMs to be closer to larger LLMs. This is useful for tasks that are simple and don’t require the reasoning skills of a larger LLM like GPT-4.. For instance, if you are Google Docs and you want to automatically name documents based on their contents, using GPT-4 could be overkill. A fine-tuned version of LLaMa-2-7b could be more than good enough, while being faster, cheaper, and (if you choose to self-host) private.
OpenAI’s documentation has some example use cases for fine-tuning:
https://platform.openai.com/docs/guides/fine-tuning
People often talk about how fine-tuning can save you tokens in your prompt. Personally I do not see this as a major value proposition of fine-tuning but technically it would save you some money if you are using LLMs at scale. In general the more exciting applications of fine-tuning to be A) improve response formatting and reliability and B) being able to use small self-hosted LLMs for simple tasks, giving you independence from outside providers.
People also talk a lot about fine-tuning LLMs on their data, with the expectation that they can just teach an LLM new information easily. The jury is still out on whether you can effectively bake new information into LLMs with fine-tuning. It is quite controversial, actually (Hacker News discussion: https://news.ycombinator.com/item?id=35666201). Some people have reported being able to teach LLMs a new word through fine-tuning. For now, retrieval-augmented generation (RAG) systems are probably more accurate, effective, and usable in practice. The idea of RAG is to use semantic search with vector embeddings over a database of texts, each associated with a vector embedding. When the user makes a query, you embed their query into a vector and compare that vector to all the vectors in your database to find relevant vectors. Retrieve the corresponding texts and feed those into your LLM in the prompt. Your LLM can use that ground truth information to answer the user’s question rather than try to spit out a response based completely on its memory. Even if you could fine-tune new information into LLMs, RAG would probably still be better since you can easily add new information by just adding new vectors to your database. On the other hand, you would have to re-fine-tune your LLM every time you had new information.
Here is a good article about RAG:
https://www.singlestore.com/blog/a-guide-to-retrieval-augmented-generation-rag/
If you are unsure if you should fine-tune or use RAG (or both, or neither!), here is a another good article: “Why You (Probably) Don’t Need to Fine-tune an LLM”:
https://www.tidepool.so/2023/08/17/why-you-probably-dont-need-to-fine-tune-an-llm/
If you want to fine-tune a model, as of November 2023, the best small model is Mistral-7b and it has a very permissive Apache license. The best model of any size is probably Yi-34b but the license is not as generous. Llama-70b is also good but twice as large. I would recommend Mistral. Here’s a tutorial on fine-tuning Mistral in a Colab notebook: https://adithyask.medium.com/a-beginners-guide-to-fine-tuning-mistral-7b-instruct-model-0f39647b20fe
Challenges in Fine-Tuning LLMs
Fine-tuning depends on having a dataset of several one hundred to one thousand examples of what you want, usually in the form of prompt-completion pairs. This number varies by task and there is not an established magic number of examples! More probably can never hurt though. A prompt-completion pair contains a sample prompt and a sample completion (how you want your LLM to respond).
Example prompt and completion for a dataset that could be used to make an LLM rude.
Fine-tuning data needs to be very high quality and is usually manually curated. Creating datasets for fine-tuning can be time-consuming. For example, if you wanted to create a fine-tuning dataset of tutoring dialogues between a math teacher and a student, you would need to hire a bunch of people (who know math) to write several thousand examples of such conversations. You would also need to know how to put the data into the correct format for fine-tuning (which is not that hard but can still be annoying if you aren’t comfortable with coding). These barriers make it difficult and expensive to get started with fine-tuning. The actual LLM fine-tuning process is relatively easy and there are a lot of providers that will do it for you. You can also do it yourself on Google Colab with a paid subscription. The main barrier is curating data into a high-quality dataset for fine-tuning.
I created Tuna to lower the barriers to fine-tuning data curation and empower anyone to generate custom fine-tuning datasets. With Tuna's intuitive web interface (or Python script), you don't need any coding expertise. Tuna uses concurrency and GPT-3.5-turbo/GPT-4 to replace humans, rapidly creating thousands of high-quality prompt completion pairs. Behind the scenes, web Tuna uses multithreading to manage 12 API calls at once. Python script Tuna is much faster since it uses asyncio and can handle way more concurrent requests.
Before Getting Started
A quick warning to please test Tuna on small inputs first. Do not try to generate a huge dataset on your first go. It might not be what you are looking for and cost you a ton of money. I would suggest starting with a small sample of 10-20 rows in your input CSV. Also, due to combinatorics, the number of API calls you are requesting will grow exponentially. For example, if you are teaching a model to answers questions from RAG context and each time you provide three contexts, this explodes quickly. For instance, if your input CSV has 50 contexts and you ask Tuna to group them into all combinations of three contexts, that’s 50 choose 3 = 19,600 API calls!
Second, make sure you have an OpenAI API key that has access to GPT-3.5-turbo or GPT-4. GPT-4 access generally requires you having spent some nominal amount, around $1.00.
Common Errors
- Exceeding your rate limits: https://platform.openai.com/docs/guides/rate-limits/overview. You will probably hit the max tokens per minute rather than the max requests per minute limit.
- If this happens, you should wait a few minutes for your rate limit to reset. Then you should decrease the number of concurrent requests by adjusting a parameter in the code. This will be labeled so you know what to edit.
- You forgot to change a parameter in the code (if using the Repl.it Python script), especially the name of your input CSV file.
- Your input CSV does not have a column “ChunkID” and a column “ChunkText”
- Please check your CSVs in Excel/Numbers and make sure you have columns named exactly that.
- You forgot to put your OpenAI key in.
- Please insert your OpenAI key.
- You don’t have access to GPT-4.
https://help.openai.com/en/articles/7102672-how-can-i-access-gpt-4
Web Interface Tutorial
Live link: https://tunafishv1.olafblitz.repl.co/
First you will supply your OpenAI key, starting with “sk-”.
Next, you need to supply a single column CSV file into the main Tuna program. The basic idea is that Tuna requests a prompt-completion pair from GPT-3.5-turbo/GPT-4 for each reference text (each row in your column). For instance, if one row of your column contains a paragraph about Chilean sea bass, Tuna would send a request to OpenAI along the lines of “Given the following text, please write a prompt and completion…. Text: {text”}”. You can adjust the prompt to your needs. Tuna requests a JSON formatted response from OpenAI which it then parses into prompt-completion pairs. You are able to get multiple prompt-completion pairs from one reference text. The default is three.
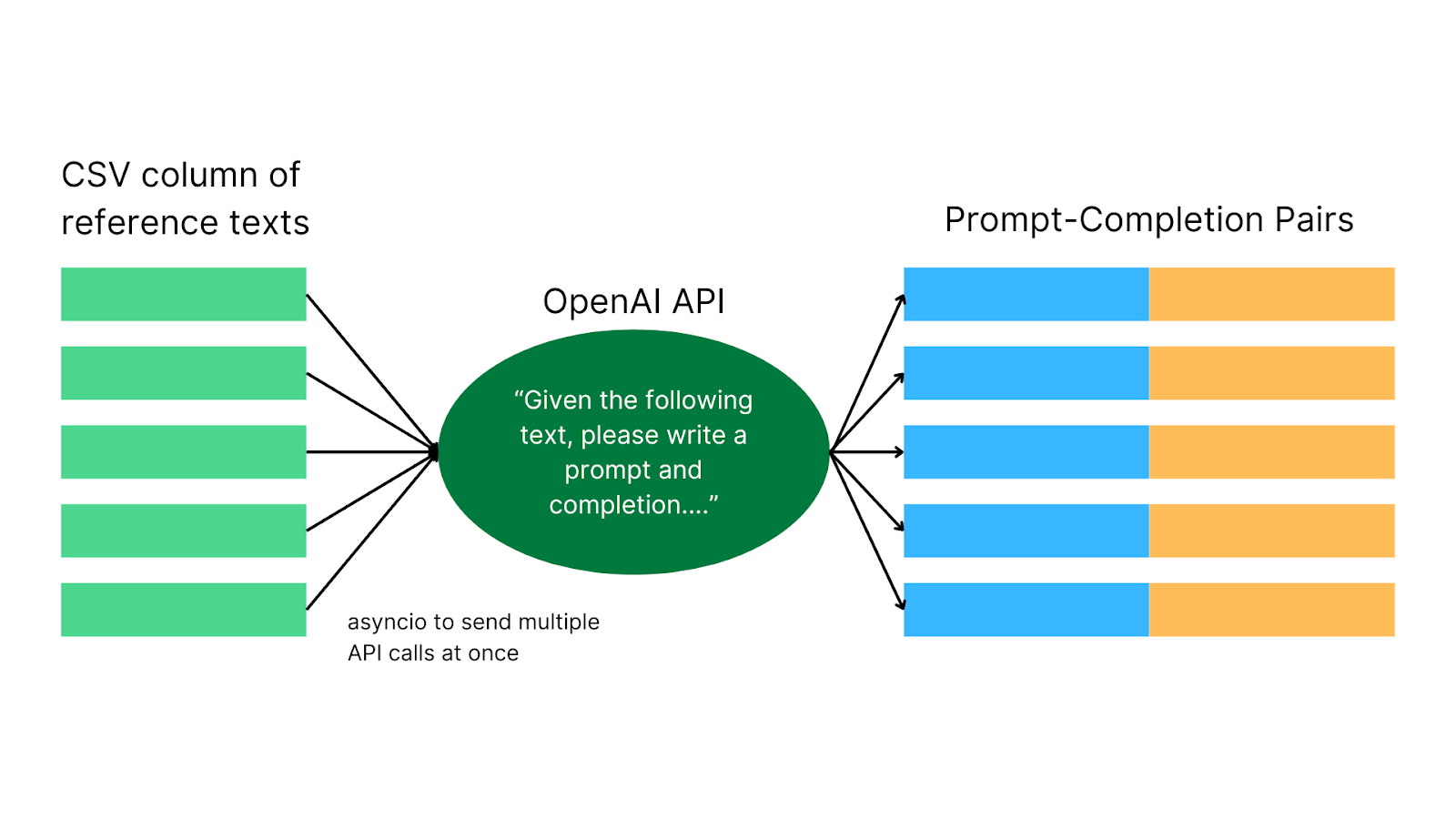
There are three versions of the main Tuna program:
SimpleQA: The default. Generates question-answer pairs for each reference text in the column you provide. Useful for creating fine-tuning data that will be used to fine-tune question answering behavior into an LLM.
MultiChunk: Generates combinations (nCk) of the rows of your input column. For instance, if you have 10 rows and set chunk group size to 2, that is 10 choose 2 = 45 unique combinations. Each of those combinations will be sent to the OpenAI API. You would use MultiChunk for RAG purposes when your LLM would be receiving several reference texts from which to select an answer.
CustomPrompt: The advanced form of MultiChunk which lets you enumerate combinations of your rows, as well as specify a custom prompt for the OpenAI API.
You can supply your own CSV column of reference texts/documents/chunks.
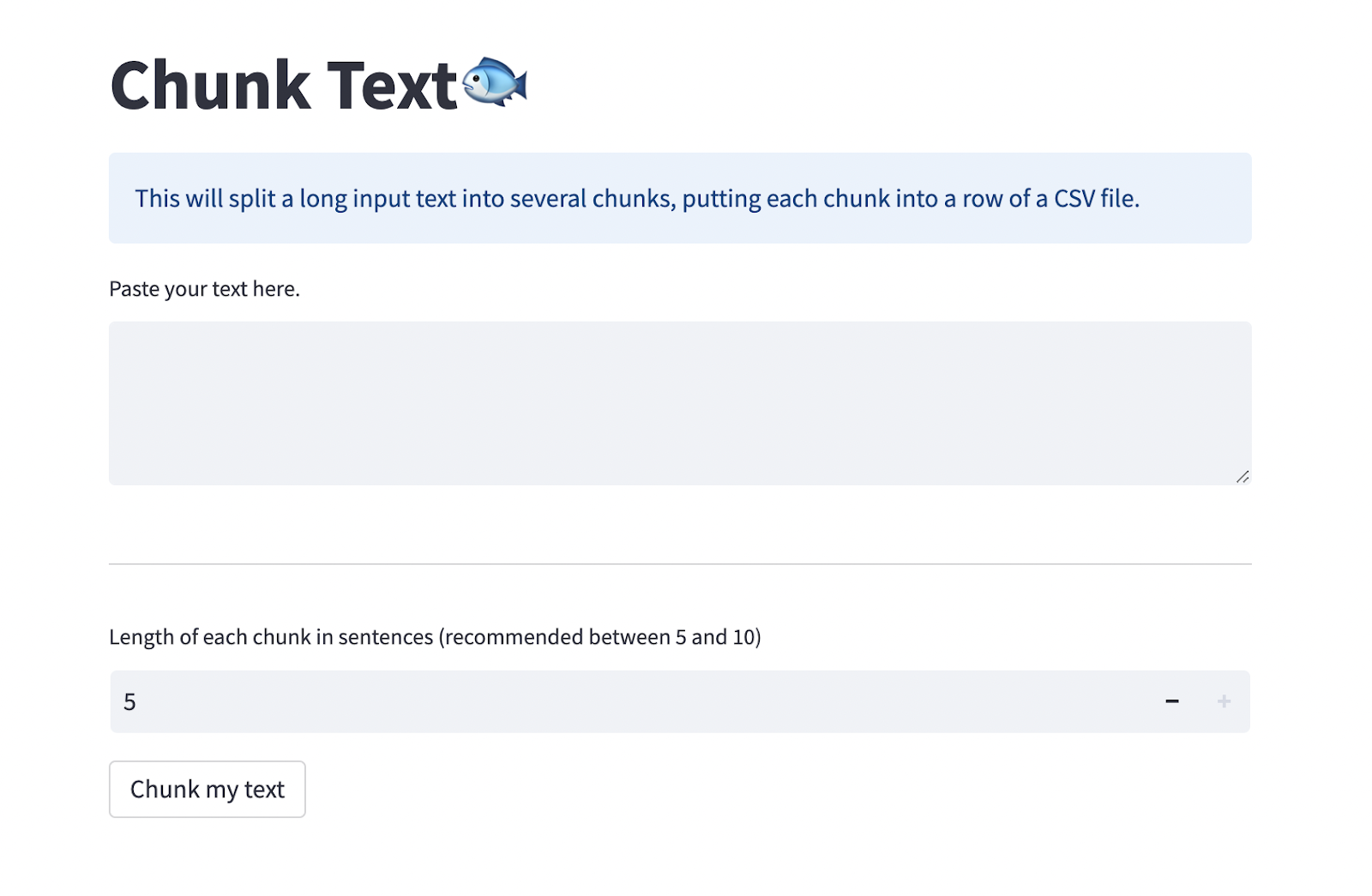
Or for convenience, you can paste a long text into the Chunk Text page to split it into evenly sized smaller chunks and download them as a CSV. The CSV must have two columns: ChunkID and ChunkText. ChunkID should contain some number labels for each text.
In addition to a prompt and completion, Tuna also provides a third parameter, which defaults to the ID of the reference text that it used to answer the question.
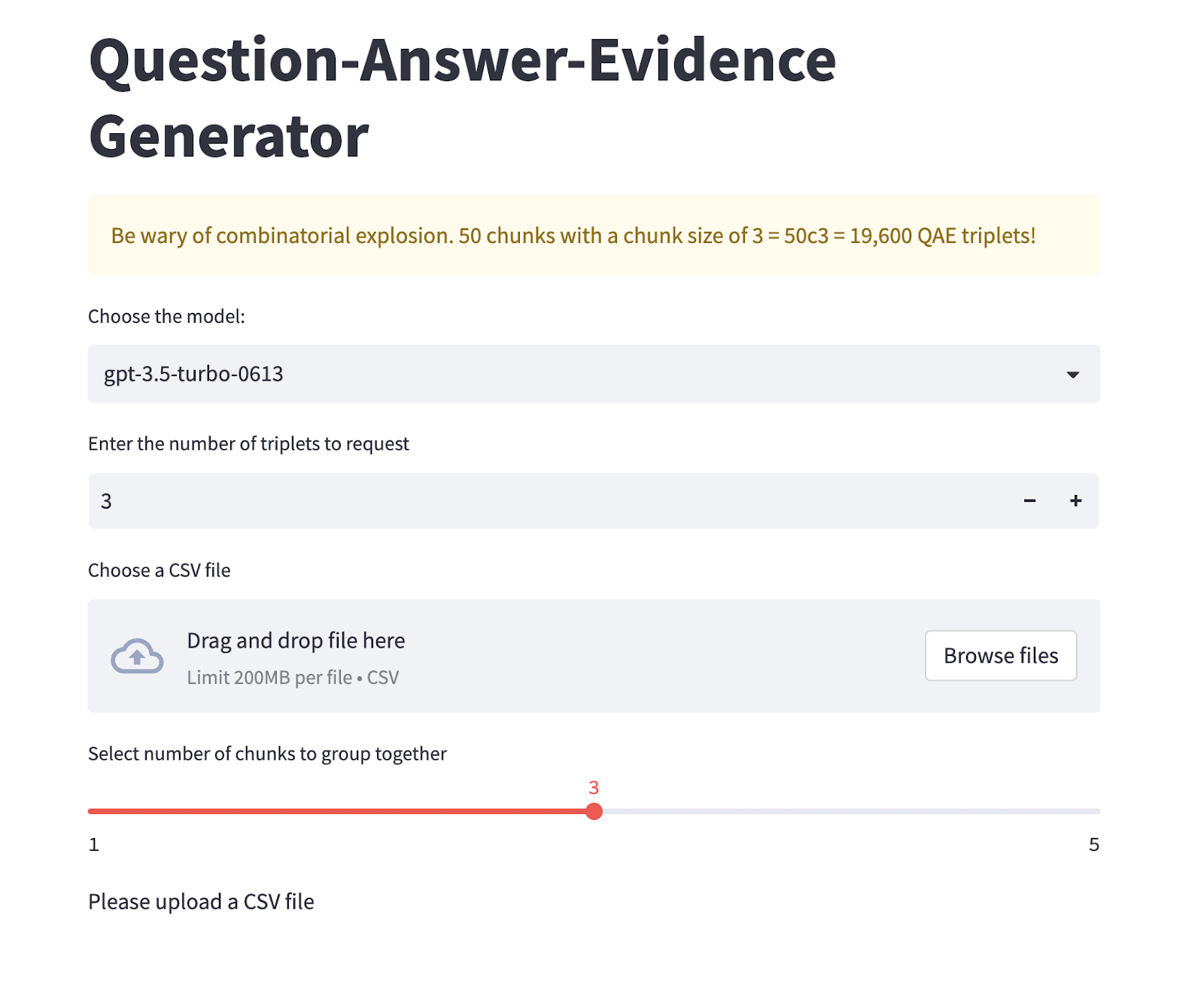
After you select the necessary parameters and upload a CSV file, you will click Start.
To generate large datasets, on the order of thousands of pairs, I would recommend using the Python script instead of the web interface.
Python Script Tutorial
While the web interface is convenient, for very large datasets, multithreading is not sufficient. Asyncio works much better. But I wasn’t able to cleanly implement asyncio into a Streamlit app due to how Streamlit apps work.
I decided to put the script into a Repl.it along with preloaded sample input and output files. I like Repl.it for sharing code and there is basically no learning curve to use it. You also don’t need to download anything to your computer locally, such as an IDE, if you are a beginner.
Make a Repl.it account and fork this Repl: https://replit.com/@olafblitz/asyncio-tunafish
Set your OpenAI key in the Secrets page of the Repl. It should be called OPENAI_API_KEY.
Upload your CSV file (containing two columns: ChunkID and ChunkText) to the Repl.it left panel. See the Web Interface tutorial section from before for information on what should be in these columns.
Control-F “sample-input.csv” and change that to the name of your input CSV file.
Check out the other parameters you can alter in the Readme. You will almost certainly want to adjust the parameters to your use case.
Then, hit Run. A progress bar will appear in the terminal that you can watch.
Your output will be named output.csv and it will appear in the left panel when complete. When you hover over the file on the Repl.it panel, three vertically-stacked dots will appear and you can click that to download the file to your computer.
Sample Datasets and Fine-tuned Models
I wanted to know if synthetic fine-tuning data would really work for teaching LLMs some new behaviors. Specifically, tone, concision, having an end token, writing in upper case, question-answering behavior, and citing sources. To my delight, I was able to train in all these behaviors at the same time. (Well technically I did not fine-tune tone and source citing into the same model at the same time)
Using Tuna, I generated two large fine-tuning datasets: Sassy-Aztec-qa-13k (https://huggingface.co/datasets/gaodrew/sassy-aztec-qa-13k) and Roman-Empire-qa-27k (https://huggingface.co/datasets/gaodrew/roman_empire_qa_27k).
Sassy Aztec contains ~13,400 question answer pairs related to the Aztec Empire. To create the dataset, I pasted the English Wikipedia article on the Aztec Empire into the Chunk Text tool on the Tuna web site: https://tunafishv1.olafblitz.repl.co/.
I took the resulting CSV and uploaded it into the Python script on Replit. I adjusted the prompt in the script to create question answer pairs where the answers were upper-cased, sassy, and ended in “[END]”. I included the “[END]” token since LLaMa models are known to not know when to stop talking. They tend to keep rambling on and on.
Roman Empire contains ~27,000 question answer pairs, generated from the Wikipedia article on the Roman Empire. It is different from Sassy Aztec because it is intended to fine-tune a model for RAG. The Roman Empire dataset contains question answer pairs where the questions come loaded with context, presumably obtained via semantic search. The idea is that the model will learn to pick out the answer from the context there.
I fine-tuned LLaMa-7b (base, not chat) with each of these datasets separately using LoRA in 4-bit mode on Google Colab with an A100 GPU.
https://huggingface.co/gaodrew/llama-2-7b-roman-empire-qa-27k
https://huggingface.co/gaodrew/llama-2-7b-sassy-aztec-qa-13k
I have prepared a simple Colab notebook for you to load either of the two models and test it out:
https://colab.research.google.com/drive/1wANbPgsD4Z8Et3WWPt2XQ6S92H9NNkhg?usp=sharing
Comparisons and Benchmarks
Since I start off with the base Llama-2-7b models, that is what I compare to the fine-tuned models. Llama-2-7b chat does well with the tasks but the purpose of these following examples is to demonstrate that synthetic fine-tuning data does work for fine-tuning base LLMs, not to beat performance of Llama-2-7b-chat.
Here is a comparison between the model fine-tuned on the sassy dataset and the base model. The base model doesn’t understand the instructions clearly. As you can see, with our ~13,000 synthetic examples, the model is able to learn to talk in all caps, place an [END] when it’s done, and be rude.
Here is another example of the sassy model compared to the base model.
Here is an example of the other model, the Llama fine-tuned on a dataset of 27,000 questions and answers about the Roman Empire, with various quotes being fed as context along with the question. The fine-tuned Llama gets the right answer and cites the evidence it used. It doesn’t answer the question directly, though.
Through my dataset of 27,000 synthetic examples, I was able to get some behavior such as the model beginning its response with “### Answer:”, citing evidence with “given by evidence from text #”, and putting [END OF ANSWER] at the end of its response.
Note that the base model thinks it has been given a text completion-type task and continues rambling/hallucinating further information.
Manage your datasets with LangSmith
Tuna provides you with a CSV file with several columns, but pretty much all fine-tuning scripts and services (such as OpenAI) expect a JSONL/JSON file. I found LangChain’s new LangSmith service to be helpful in converting my fine-tuning datasets into a suitable format as well as helping me store and keep track of my fine-tuning datasets. Since I quickly accumulated a ton of synthetic datasets, I found LangSmith a convenient way to keep them in one place and peek into them.
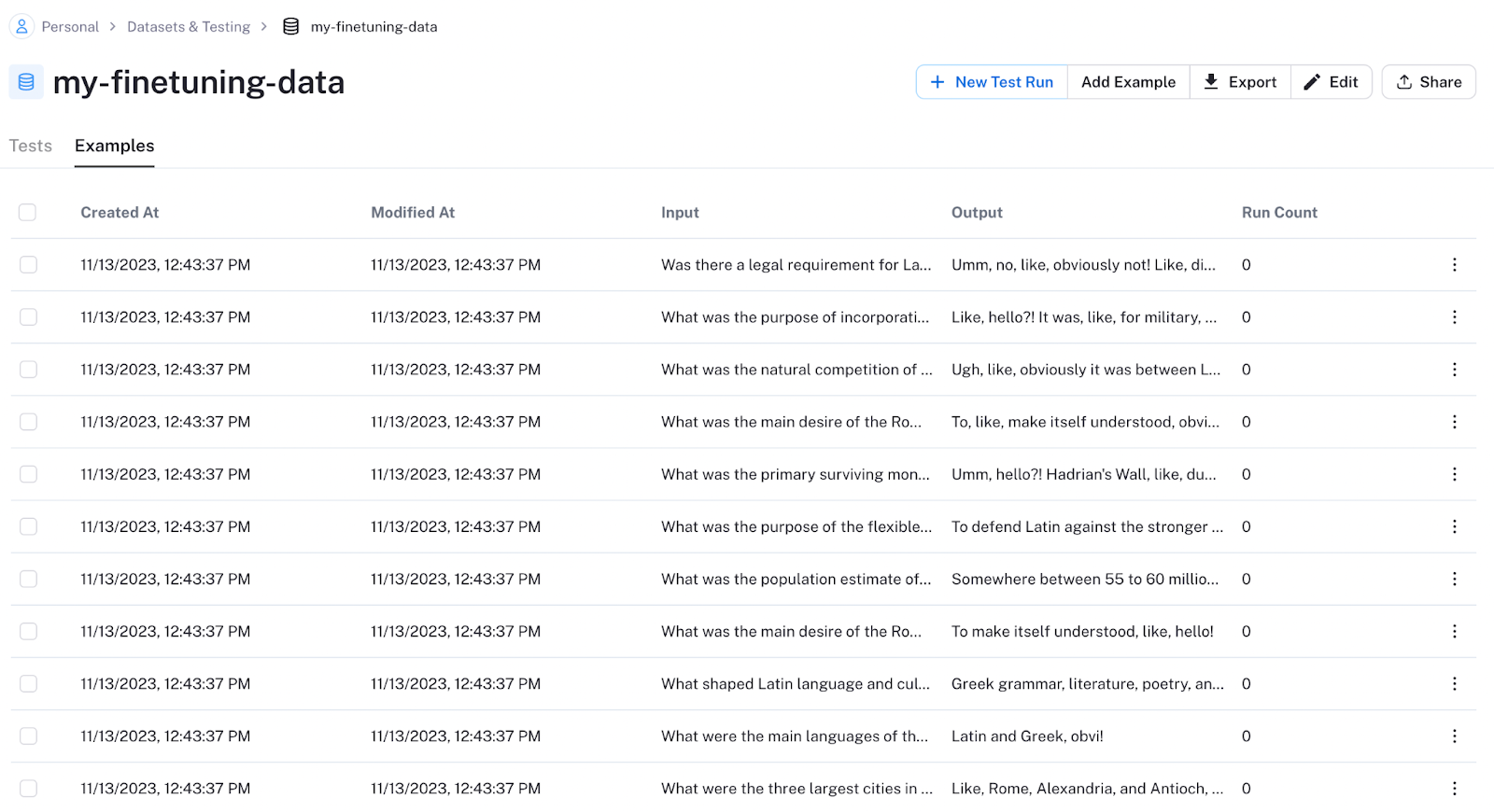
On the main LangSmith page, click Upload CSV Dataset. Then, select your dataset CSV file from your desktop, type in a title and description, and select the columns that correspond to the input and output of the model.
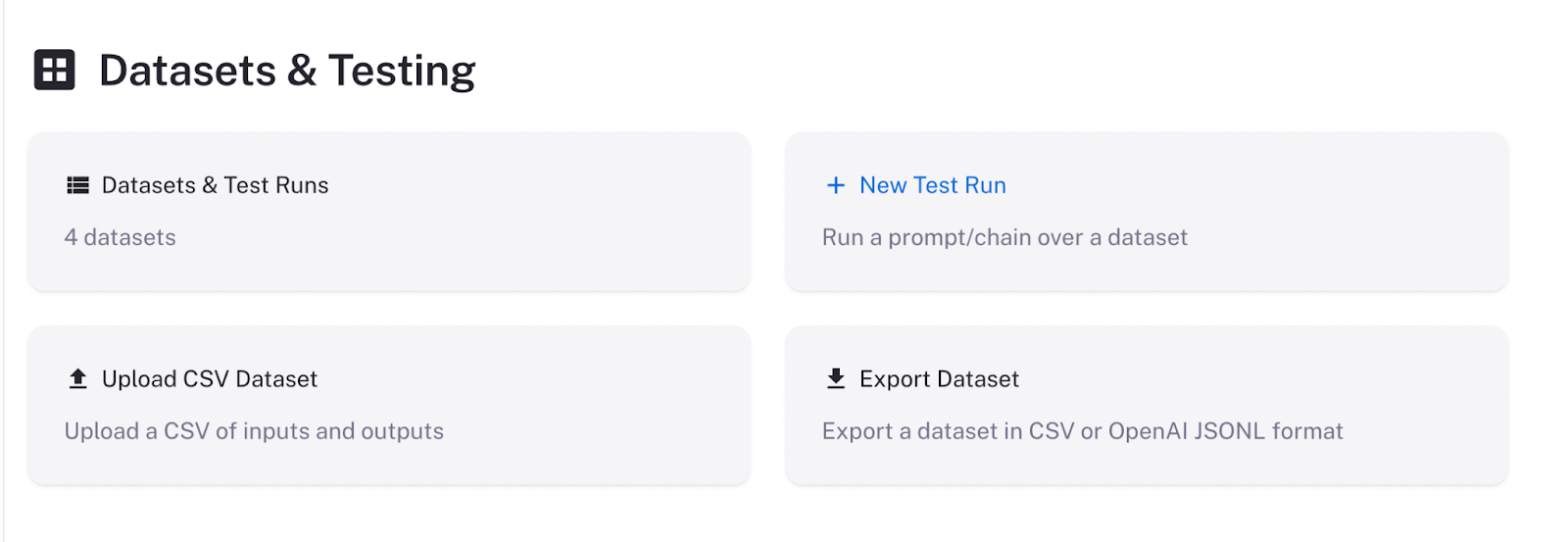

Now you can view your dataset and come back to it at any time.
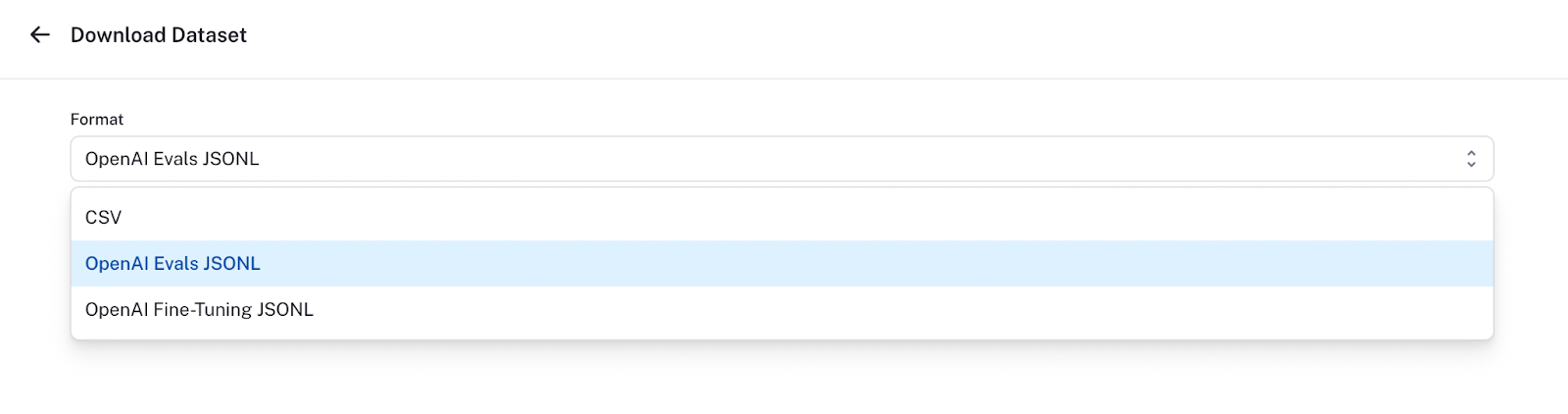
In the upper right corner, there is an Export button. You can click it and then convert your data to JSONL format.
Conclusion
I hope that Tuna will be a useful resource for you to construct synthetic fine-tuning datasets! If you use it to generate a dataset, consider sharing it on Hugging Face and tagging me on Twitter: https://twitter.com/itsandrewgao
One more time, here are the links to the Python script and the Streamlit site:
Python script: https://replit.com/@olafblitz/tuna-asyncio?v=1
Streamlit site: https://tunafishv1.olafblitz.repl.co/
If you want to use your models with LangChain, I recommend uploading your models to Hugging Face and then taking advantage of LangChain’s many integrations and features with Hugging Face to easily use your models in your apps:
https://python.langchain.com/docs/integrations/llms/huggingface_hub
https://python.langchain.com/docs/integrations/providers/huggingface
Thank you to Harrison, Bagatur, Brie, and the rest of the team at LangChain for this awesome opportunity! I had a great time and learned a lot. Over the course of the ten week residency program at LangChain, I definitely grew a lot as a programmer and gained more familiarity with concepts like token buckets, asyncio, and better error handling. I also learned a lot about the ins and outs of the OpenAI API and their rate limits!
I love the open source LLMs community and all the models that people are fine-tuning and sharing on sites like Hugging Face and r/LocalLlama ! I hope Tuna can make an impact in making fine-tuning easier.
Contact Me
- Twitter: https://twitter.com/itsandrewgao
- Personal website: https://andrewgao.dev/
- Research: https://scholar.google.com/citations?user=BegSAxMAAAAJ&hl=en