Learn to implement an open-source Mixtral agent that interacts with a graph database Neo4j through a semantic layer
Editor's note: This post is written by Tomaz Bratanic from Neo4j
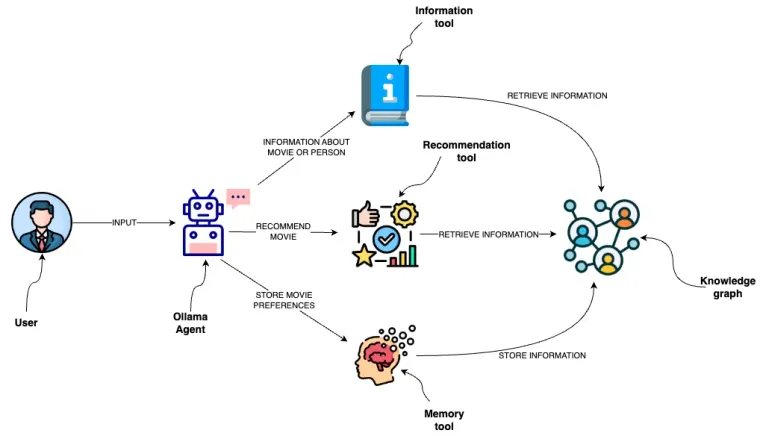
By now, we all have probably recognized that we can significantly enhance the capabilities of LLMs by providing them with additional tools. For example, even ChatGPT can use Bing Search and Python interpreter out of the box in the paid version. OpenAI is a step ahead and provides fine-tuned LLM models for tool usage, where you can pass the available tools along with the prompt to the API endpoint. The LLM then decides if it can directly provide a response or if it should use any of the available tools first. Note that the tools don’t have to be only for retrieving additional information; they can be anything, even allowing LLMs to book a dinner reservation. I have previously implemented a project allowing an LLM to interact with a graph database through a set of predefined tools, which I called a semantic layer.

In essence, these tools augment a LLM like GPT-4 by providing dynamic, real-time access to information, personalization through memory, and a sophisticated understanding of relationships through the knowledge graph. Together, they enable the LLM to offer more accurate recommendations, understand user preferences over time, and access a broader range of up-to-date information, resulting in a more interactive and adaptive user experience. As mentioned, besides the ability to retrieve additional information at query time, they also give the LLM an option to influence their environment by, for example, booking a meeting in the calendar.
While OpenAI has spoiled us with its fine-tuned models for tool usage, the reality is that most other LLMs aren’t at the level of OpenAI when it comes to function calling and tool usage. I have tried most of the models available in Ollama, and most struggle with consistently generating predefined structured output that could be used to power an agent. On the other hand, there are some models that are fine-tuned for function-calling. However, those models have a custom prompt engineering schema for function-calling they follow, which is not well documented, or they can’t be used for anything other than function-calling.
Ultimately, I decided to follow the existing LangChain implementation of a JSON-based agent using the Mixtral 8x7b LLM. I used the Mixtral 8x7b as a movie agent to interact with Neo4j, a native graph database, through a semantic layer. The code is available as a Langchain template and as a Jupyter notebook. If you are interested in how the tools are implemented, you can look at my previous blog post. Here, we will discuss how to implement a JSON-based LLM agent.
Tools in the semantic layer
The examples in LangChain documentation (JSON agent, HuggingFace example) use tools with a single string input. Since the tools in the semantic layer use slightly more complex inputs, I had to dig a little deeper. Here is an example input for a recommender tool.
all_genres = [
"Action",
"Adventure",
"Animation",
"Children",
"Comedy",
"Crime",
"Documentary",
"Drama",
"Fantasy",
"Film-Noir",
"Horror",
"IMAX",
"Musical",
"Mystery",
"Romance",
"Sci-Fi",
"Thriller",
"War",
"Western",
]
class RecommenderInput(BaseModel):
movie: Optional[str] = Field(description="movie used for recommendation")
genre: Optional[str] = Field(
description=(
"genre used for recommendation. Available options are:" f"{all_genres}"
)
)
The recommender tools has two optional inputs, movie and genre. Additionally, we use an enumeration of available values for the genre parameter. While the inputs are not highly complex, they are still more advanced than a single string input, so the implementation has to be slightly different.
JSON-based prompt for an LLM agent
In my implementation, I took heavy inspiration from the existing hwchase17/react-json prompt available in LangChain hub. The prompt uses the following system message.
Answer the following questions as best you can. You have access to the following tools:
{tools}
The way you use the tools is by specifying a json blob.
Specifically, this json should have a `action` key (with the name of the tool to use) and a `action_input` key (with the input to the tool going here).
The only values that should be in the "action" field are: {tool_names}
The $JSON_BLOB should only contain a SINGLE action, do NOT return a list of multiple actions. Here is an example of a valid $JSON_BLOB:
```
{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}
```
ALWAYS use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin! Reminder to always use the exact characters `Final Answer` when responding.
The prompt starts by defining the available tools, which we will get to a bit later. The most important part of the prompt is instructing the LLM on what the output should look like. When the LLM needs to call a function, it should use the following JSON structure:
{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}
That’s why it is called a JSON-based agent: we instruct the LLM to produce a JSON when it wants to use any available tools. However, that is only a part of the output definition. The full output should have the following structure:
Thought: you should always think about what to do
Action:
```
$JSON_BLOB
```
Observation: the result of the action
... (this Thought/Action/Observation can repeat N times)
Final Answer: the final answer to the original input question
The LLM should always expain what is it doing in the thought part of the output. When it wants to use any of the available tools, it should provide the action input as a JSON blob. The observation part is reserved for tool outputs, and when the agent decides it can return an answer to the user, it should use the final answer key. Here is an example from the movie agent using this structure.

In this example, we asked the agent to recommend a good comedy. Since one of the available tools of the agent is a recommender tool, it decided to utilize the recommender tool by providing the JSON syntax to define its input. Luckily, LangChain has a built-in output parser of the JSON agent, so we don’t have to worry about implementing it. Next, the LLM gets a response from the tool and uses it as an observation in the prompt. Since the tool provided all the required information, the LLM decided that it had enough information to construct a final answer, which could be returned to the user.
I noticed that it’s hard to prompt engineer Mixtral in a way so that it only uses the JSON syntax when it needs to use a tool. In my experiments, when it didn’t want to use any tools, it sometimes used the following JSON action input.
{{
"action": Null,
"action_input": ""
}}
The output parsing function in LangChain doesn’t ignore the action if it is null or similar, but returns an error that the null tool is not defined. I tried to prompt engineer a solution for this problem, but couldn’t do it in a consistent manner. Therefore, I decided to add a dummy smalltalk tool that the agent can call when the user wants to smalltalk.
response = (
"Create a final answer that says if they "
"have any questions about movies or actors"
)
class SmalltalkInput(BaseModel):
query: Optional[str] = Field(description="user query")
class SmalltalkTool(BaseTool):
name = "Smalltalk"
description = "useful for when user greets you or wants to smalltalk"
args_schema: Type[BaseModel] = SmalltalkInput
def _run(
self,
query: Optional[str] = None,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
"""Use the tool."""
return response
This way, the agent can decide to use a dummy Smalltalk tool when the user greets it, and we no longer have problems with parsing null or missing tool names.
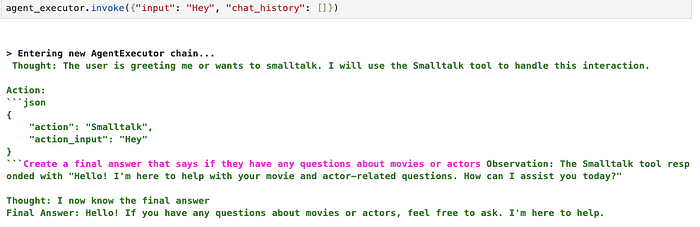
This workaround works quite well, so I decided to keep it. As mentioned, most models aren’t trained to produce action inputs or text if no action is required, so we have to work with what is currently available. However, sometimes the model successfully doesn’t call any tools on the first iteration as well, it depends. But giving it an escape option like the smalltalk tool seems to prevent exceptions.
Defining tool inputs in system prompt
As mentioned, I had to figure out how to define slightly more complex tool inputs so that the LLM could correctly interpret them. Funnily enough, after implementing a custom function, I found an existing LangChain function that transforms the custom Pydantic tool input definition into a JSON object that the Mixtral recognizes.
from langchain.tools.render import render_text_description_and_args
tools = [RecommenderTool(), InformationTool(), Smalltalk()]
tool_input = render_text_description_and_args(tools)
print(tool_input)
Produces the following string description:
"Recommender":"useful for when you need to recommend a movie",
"args":{
{
"movie":{
{
"title":"Movie",
"description":"movie used for recommendation",
"type":"string"
}
},
"genre":{
{
"title":"Genre",
"description":"genre used for recommendation. Available options are:['Action', 'Adventure', 'Animation', 'Children', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy', 'Film-Noir', 'Horror', 'IMAX', 'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']",
"type":"string"
}
}
}
},
"Information":"useful for when you need to answer questions about various actors or movies",
"args":{
{
"entity":{
{
"title":"Entity",
"description":"movie or a person mentioned in the question",
"type":"string"
}
},
"entity_type":{
{
"title":"Entity Type",
"description":"type of the entity. Available options are 'movie' or 'person'",
"type":"string"
}
}
}
},
"Smalltalk":"useful for when user greets you or wants to smalltalk",
"args":{
{
"query":{
{
"title":"Query",
"description":"user query",
"type":"string"
}
}
}
}
We can simply copy this tool description in the system prompt and Mixtral will be able to use the defined tools, which is quite cool.
Conclusion
Most of the work to implement the JSON-based agent was done by Harrison Chase and the LangChain team, for which I am grateful. All I had to do was find the puzzle pieces and put them together. As mentioned, don’t expect the same level of agent performance as with GPT-4. However, I think the more powerful OSS LLMs like Mixtral could be used as agents today (with a bit more exception handling than GPT-4). I am looking forward to more open source LLMs being fine-tuned as agents.
The code is available as a Langchain template and as a Jupyter notebook.