
Editor's Note: This post was written by the Kay team, in collaboration with Cybersyn. Financial data processing is hard. SEC Retriever on LangChain– Powered by Kay and Cybersyn–makes it easy for developers to retrieve context from SEC Filings for their generative and conversational agents.
Financial documents carry a wealth of nuanced information that is frequently used in high-stakes scenarios, from investing to corporate strategy. SEC Filings are a common source of such financial knowledge for US Public Companies. Several teams are starting to tap into this unstructured data for LLM use cases, but encounter multiple challenges.
- LLMs are missing context: LLM knowledge is as good as the last training date. Financial markets move rapidly, and developers need to leverage Retrieval Augmented Generation (RAG) to equip LLMs with up-to-date knowledge. Moreover, SEC Filings are hard to index by search engines due to their data formats. Developers then opt to train on derivative articles related to these documents, except this can overlook the source context and lesser-known companies.
- Embedding infra is evolving rapidly: Both in terms of planning and implementation, infrastructure for RAG is difficult to get right. Developers building their own RAG pipelines are inundated with choice. There are over 50 vector stores to choose from and an ever-changing list of embedding models on the MTEB Leaderboard. There are new ways to embed and retrieve every week. Things get trickier as you try to procure more GPU capacity and set up large-scale offline batch embedding pipelines; all while trying to tame compute costs.
- Financial documents are complex: In addition to extracting data from obscure data formats, financial documents also require careful processing and chunking of data. Developers need to experiment with different ways of transforming tables, determining relevant entities, and linking them to parent sections. There's a low tolerance for false positives in retrieving these documents since these numbers directly influence important decisions.
Multiple teams are building this exact same pipeline in-house, driving up costs. This is where the SEC Retriever on LangChain comes in. Powered by Kay and Cybersyn, developers can easily retrieve context from SEC Filings for their generative and conversational agents.
Kay provides data APIs that are specifically designed for RAG. We offer fully hosted embeddings of large datasets so developers don’t have to collect data, generate embeddings, and scale retrieval. Cybersyn is a data-as-a-service company delivering analytics-ready economic data on Snowflake Marketplace. Initially focused on where businesses and consumers spend money and time, Cybersyn offers multiple data products via Snowflake, including an LLM training dataset that features SEC Filings. Kay further enriches, embeds, and sets up a semantic retrieval API for this data. In this blog, we will cover how to get started with this API and an overview of the infrastructure behind it.
Getting Started
Using Kay in LangChain is incredibly straightforward.
First, install Kay (pip install kay) and get your free API key on Kay.ai.
Second, initialize the KayAiRetriever with the datasets you need. Currently, we index multiple datasets related to Companies. These datasets include financial documents, press releases, engineering blogs, and more (docs). In this case, we'll access 10-K and 10-Qs, and retrieve the top 6 chunks for a given query.
from langchain.retrievers import KayAiRetriever
retriever = KayAiRetriever.create(dataset_id="company", data_types=["10-K", "10-Q"], num_contexts=6)From here on, it's business as usual. Plug this context into your existing prompts and pass it to your favorite LLM. Here's a sample query that really highlights the power of embedded SEC data.
**Question**: What are patterns in Nvidia's financial performance over the past three quarters?
**Answer**: Based on the provided financial statements, here are some patterns in NVIDIA's financial performance over the past three quarters:
1. Cash Flows from Operating Activities: The net cash provided by operating activities has shown a consistent increase over the three quarters. It was $1,874 million in Q1 2023, $1,731 million in Q2 2023, and $1,288 million in Q3 2023.
2. Cash Flows from Investing Activities: The net cash provided by investing activities has fluctuated significantly. In Q1 2023, it was $2,612 million, indicating a positive cash flow. However, in Q2 2023, it was negative with a cash outflow of $8,244 million. In Q3 2023, it turned positive again with a cash inflow of $7,378 million.
3. Cash Flows from Financing Activities: The net cash provided by financing activities has also shown variation. In Q1 2023, it was $4,146 million, indicating a positive cash flow. In Q2 2023, it was negative with a cash outflow of $9,961 million. In Q3 2023, it remained negative but decreased to $2,610 million.
4. Acquisitions and Investments: NVIDIA has made acquisitions and investments in all three quarters, but the amounts have varied. In Q1 2023, the net cash used in investing activities was $1,272 million. In Q2 2023, it was a significant cash outflow of $8,244 million. In Q3 2023, it turned positive with a cash inflow of $7,378 million.
5. Payments related to Repurchases of Common Stock: NVIDIA made significant payments related to repurchases of common stock in Q2 2023, with a cash outflow of $8,826 million. This suggests a focus on returning value to shareholders through stock buybacks.
These patterns indicate fluctuations in cash flows from investing and financing activities, while operating cash flows have remained relatively stable. Acquisition and investment activities have also contributed to the variations in cash flows. Additionally, NVIDIA's focus on returning value to shareholders is evident through payments related to repurchases of common stock.In contrast, try the same query with search-enabled LLMs like ChatGPT, Bard, or Perplexity. Kay captures a lot more nuance, since we pre-embed all this data and tailor our retrieval for each dataset and use case. This includes data enrichment, state-of-the-art embeddings, query understanding, and many other topics covered in the infrastructure section below.
Use cases
SEC Filings are large, unstructured documents. They capture crucial information about US public companies. In the past, all this data was squeezed into a few rigid tables, making most practitioners miss valuable signals from these files. Now, we can enable analysts, auditors, investors, executives, sales, and marketing teams to parse this information in seconds. Here are a few examples of how users are already utilizing this data.
Analyzing Financial Performance
"Show me the revenue growth trend of Company X over the past five years."
"Compare the debt-to-equity ratios of Company A and Company B."
Identifying Sales Opportunities
"Which new hardware products did Company X release this year?" "Summarize Company A's strategic direction and their expansion plans."
Monitoring Industry Trends
"What are some key market trends Company X is tapping into?" "Identify differences in positioning between Company A and Company B."
Compliance Research
"How is Company X adapting to recent GDPR guidelines?" "What are the potential risks associated with the acquisition of Company A?"
Behind the Scenes: Infrastructure
RAG systems consist of three essential components: data, representation, and retrieval. In this scenario, data is typically represented as embeddings. The decisions we make regarding these components directly impact performance. At Kay, we care a lot about these choices and constantly stay up to date with the latest techniques. The diagram below depicts some of the key processes within each component. Let's break that down
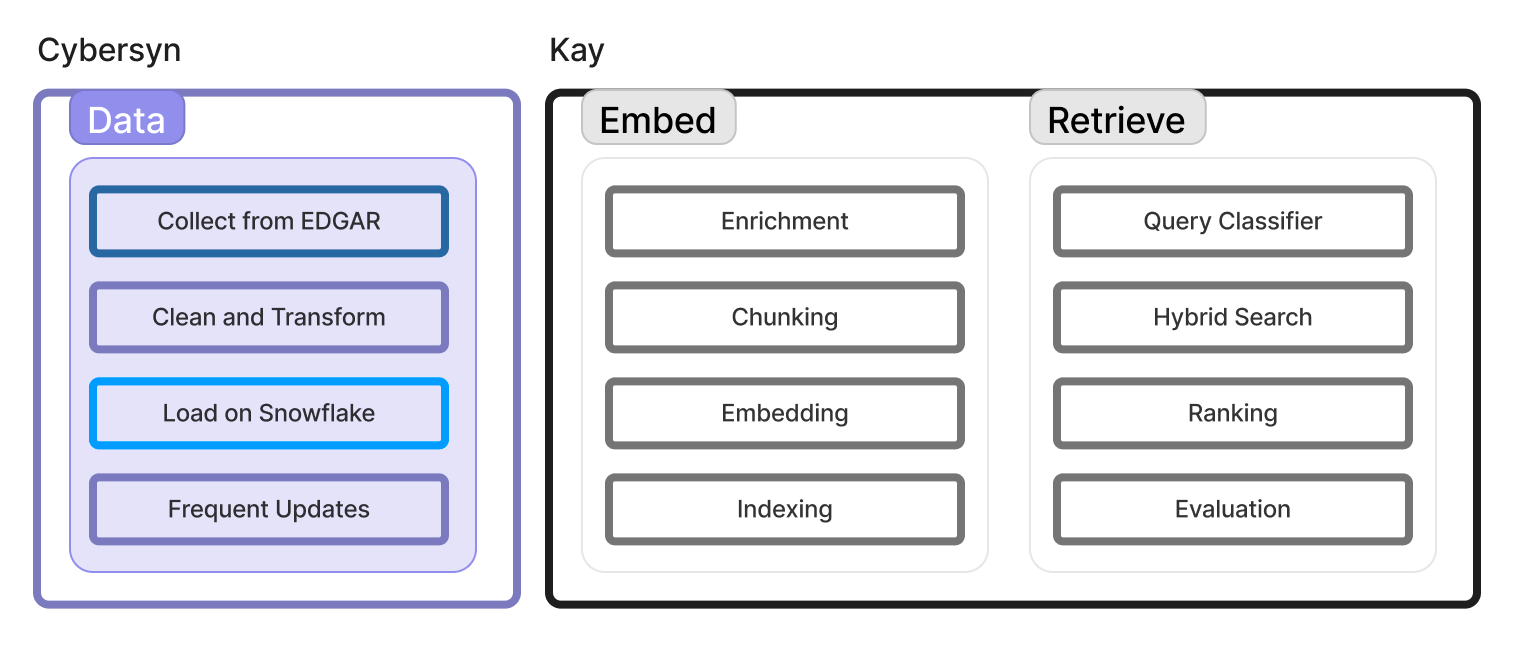
Collecting data
The foundation of our system is high-quality data. All US public companies submit their mandatory filings through SEC's Electronic Data Gathering, Analysis, and Retrieval (EDGAR) system. While this data is available via an API, it can be challenging to process and embed this due to its varied data formats. This is where Cybersyn steps in.
Cybersyn builds derived data products from proprietary and public datasets that are difficult to procure, clean, or join. One of their data products is LLM Training Essentials, which includes SEC Filings along with several other government datasets. This brings us several benefits:
- Cybersyn converts unstructured TXT and XBRL data into a relational database, eliminating the need to set up your own OCR and text extraction pipelines from Filing PDFs.
- They also provide additional metadata that helps users join companies with common company identifiers including CIK, EIN, LEI, PermID, and OpenFIGI. This proves useful down the line for retrieval.
- This data is then loaded onto the Snowflake Marketplace. Snowflake ensures secure and fully-governed access to this data, allowing users to read and interact with it using SQL queries. This significantly improves ease of access.
- Cybersyn also takes responsibility for regularly updating this data, recognizing its time-sensitive nature for use cases involving SEC data.
Working with Cybersyn and Snowflake has significantly contributed to Kay's data quality, accessibility, and reliability. We highly recommend exploring all of their data products.
Generating embeddings
Once we have raw text data, we start data enrichment. We focus on creating two types of metadata.
- Company Metadata: We source company information such as ticker symbol, industry, location, summary, website, and more. This data helps us normalize and group companies for efficient retrieval.
- Document Metadata: We also extract information specific to each document such as different sections, all mentions of time and date, and significant entities with NER. This metadata further enhances retrieval. Some of this gets embedded with the chunk and others are used in filtering.
Next step is choosing an embedding model. First, we quickly decided to move away from OpenAI embedding APIs to self-hosting open-source models. OSS embedding models are state of the art, give full control on scaling, are a lot cheaper and open up fine-tuning capabilities down the line. This was essential for us to iterate fast and be able to scale later. Amongst OSS models, after internal evaluation of different use cases for this dataset, we landed on gte-base which is one of the top models on the current leaderboard.
To handle SEC data, we implement dynamic variable chunking based on sections, ensuring that the chunk size is limited to an average of 1500 characters using sentences. We handle chunks with tables differently by having a LLM summarize them in natural language. At the end of this process, we have all the data and the tools to start chunking and embedding. For offline batch embedding jobs, we leveraged Ray's parallelization framework. Ray has been easy to set up, does the job, and has reliable support. It enabled us to chunk and embed over 20 million embeddings in under 15 minutes.
Finally, we push the generated embeddings into a vector database. We use HNSW for vector indexing and BM25 for text indexing, which is fairly standard for these data types. One notable observation was that several vector stores perform simultaneous write and indexing operations, resulting in a significant decrease in write throughput. To address this issue, we highly recommend transitioning to incremental indexing.
Optimizing Retrieval
Retrieval goes beyond making a default call to your vector store. There's a lot we can do to decrease the candidate set and rank chunks better. In this component, we aim to make the retrieval process as accurate and efficient as possible.
First, we build our own Query Intent Classifier (QIC) powered by LLMs. Given a query, this extracts all the entities that can either help us filter chunks on our metadata or get us some new information that validates hybrid search. This is where we force the LLM for structured output (s/o Instructor). We also run sanity checks on the final response with string matching libraries to not miss out on entities that might exist in our metadata, for example. nike and nike inc. Turns out normalization itself for each metadata is a massive internal effort to do right.
In addition to the classifier, we have also begun generating hallucinated search queries to conduct retrieval over, and to vote on the most relevant answers. While this has latency costs, this is an ongoing experiment to see how this improves accuracy.
After obtaining a collection of search queries along with relevant filters, we initiate the retrieval process by narrowing down potential candidates using these filters. Next, we dynamically select between vector search and hybrid search, depending on the presence of any significant entities identified by QIC that warrant a keyword search. For vector search, we go with the default cosine distance.
Once we have our top-k retrieved chunks, we apply Cohere's Re-rank and take log of the context relevancy score. These scores help us set up our human evaluation task to unpack how users can intuitively reason through these scores. In the interim, we continue experiments to keep improving the distribution of context relevancy scores.
Resources and next steps
RAG is obviously an evolving process that requires consistent commitment to optimization. Our motive for sharing how we approach this stack is to bring more transparency, share our learnings, and welcome feedback so we can continue improving retrieval for public datasets. The strategies we use are not set in stone and we'd love for you to try our SEC retriever and share what you think. Happy to chat and share notes at cal.com/kaydotai/chat.
Here’s some resources to dive in further
- SEC Retriever on LangChain
- Cybersyn’s LLM Training Essentials
- Snowflake Marketplace
- Kay’s Github
Also, a reminder: LangChain Users get 10,000 Free Kay Requests for next 3 Months ⚡️