
Today we’re excited to announce and showcase an open source chatbot specifically geared toward answering questions about LangChain’s documentation.
Key Links
- Deployed Chatbot: chat.langchain.dev
- Deployed Chatbot on HuggingFace spaces: huggingface.co/spaces/hwchase17/chat-langchain
- Open source repo: github.com/hwchase17/chat-langchain
- Next.js frontend: github.com/zahidkhawaja/langchain-chat-nextjs
Huge shoutout to Zahid Khawaja for collaborating with us on this. If you want this type of functionality for webpages in general, you should check out his browser extension: Lucid.
If you like this and want a more advanced version of this for your codebase, you should check out ClerkieAI. Their question answer bot is live on our Discord.
Overview
There have been a few other projects similar to this one in the past weeks (more on that below). However, we hope to share what we believe are unique insights, including:
- Document ingestion (what is and isn’t general)
- How to make this work in a chatbot setting (important UX)
- (Prompt Engineering) Tradeoff between speed and performance
- (Prompt Engineering) How to get it to cite sources
- (Prompt Engineering) Output format
Expanding on the bolded section, we believe the chatbot interface is an important UX (just see the success of ChatGPT!) and we think that is missing from other implementations.
Motivation
Combining LLMs with external data has always been one of the core value props of LangChain. One of the first demo’s we ever made was a Notion QA Bot, and Lucid quickly followed as a way to do this over the internet.
One of the pieces of external data we wanted to enable question-answering over was our documentation. We have a growing Discord community, and want to provide fast and accurate support for all their questions. So this seemed like a perfect opportunity to utilize our own technology internally! We reached out to Zahid, an ML creator and LangChain enthusiast, to see if he would be willing to team up for this, and to our relief he said yes! And so we started building.
Similar Work
For whatever reason, there was a lot of similar work done here in just the past week! Pretty much all of them followed the same pipeline, which can be condensed as follows:
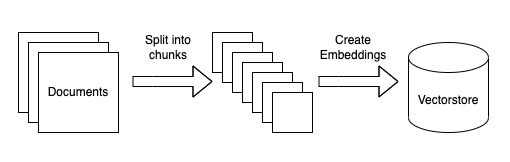
Ingestion:
- Take a set of proprietary documents
- Split them up into smaller chunks
- Create an embedding for each document
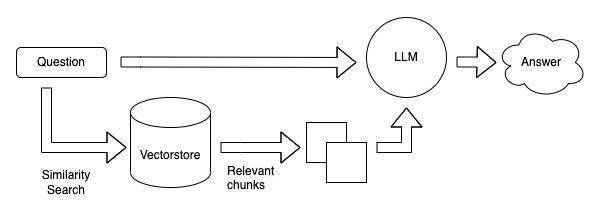
Query:
- Create an embedding for the query
- Find the most similar documents in the embedding space
- Pass those documents, along with the original query, into a language model to generate an answer
Some good other examples of this include:
- GitHub support bot (by Dagster) - probably the most similar to this in terms of the problem it’s trying to solve
- Dr. Doc Search - converse with a book (PDF)
- Simon Willison on “Semantic Search Answers” - a good explanation of the some of the topics here
- Ask My Book - by Sahil Lavingia, maybe the example that kicked off this current craze
Document Ingestion
We immediately faced a question: where exactly to get the data from. There were two options: the files in GitHub, or scraping from the internet. While some of the files in GitHub were in a nice format to work with (markdown and rst) we also had some less good for working with (.ipynb files, auto generated docs). For that reason we decided to go with scraping it from the internet.
After that, we faced a question of how to preprocess the html files. For this we initially did this in a generic way (just using Beautiful Soup to get all the text on the page). However, after using these results we found that some of the sidebar contents were creating bad results. As a visual example, in the picture below the two areas in red don’t really provide much new information.
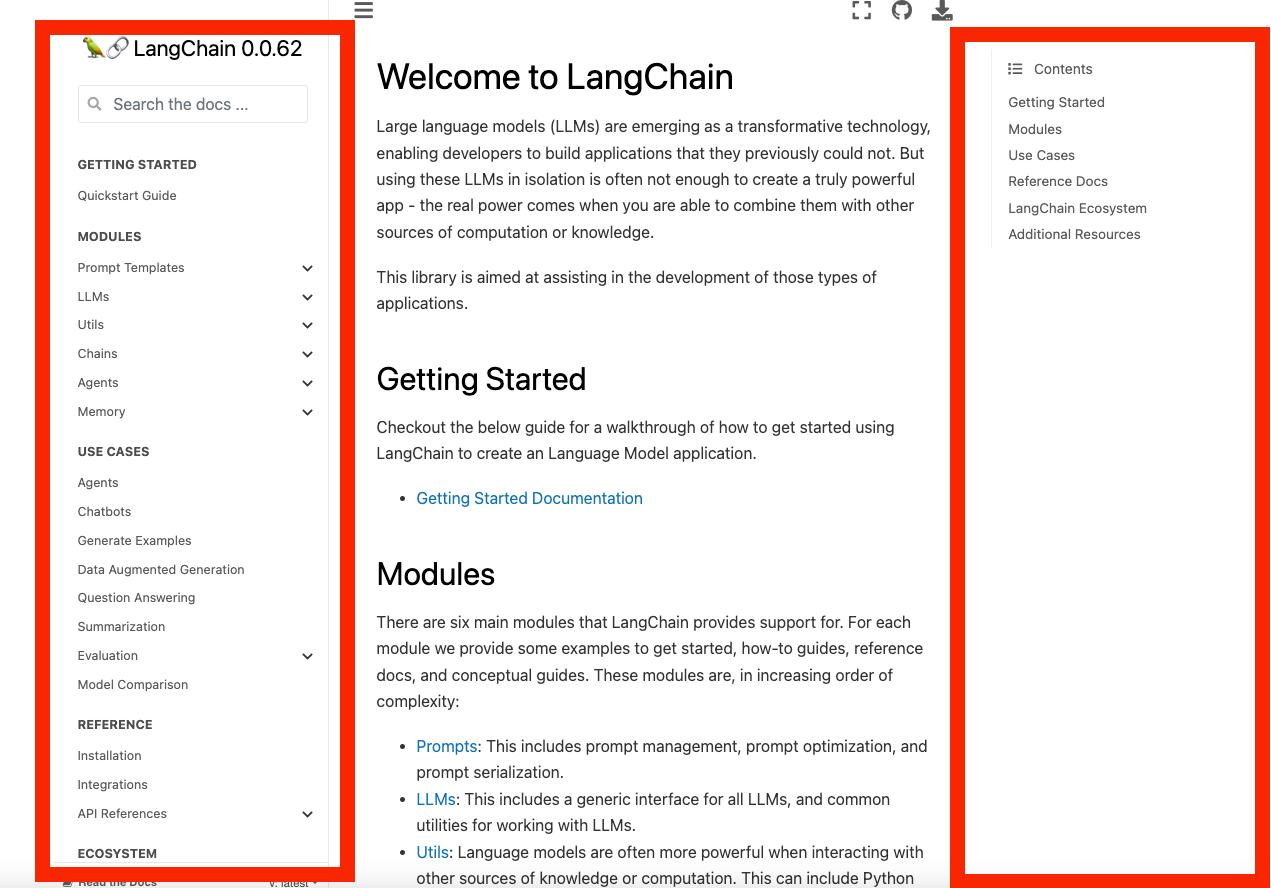
When we inspected some of the bad results we were getting, we saw that often it was these pieces of information that were getting pulled and stuffed into the context. We fixed this by changing the parser to explicitly ignore those areas.
Although specific to this layout, we do believe this highlights the importance of being very intentional about what data you do (or do not) include as potential context. While it may be easy to take a generic ingestion tool and use that as a way to get quickly started, doing deeper inspection and modifying your pipeline will probably be necessary to get better performance.
How to make this work in a chatbot setting
As mentioned before, we believe a chatbot setting is an important UX decision that:
- People find familiar (see the success of ChatGPT)
- Enable other key features (more on this below)
One of the key features that we wanted to make sure to include that we did not see being done a lot of other places is the ability to ask follow up questions. We believe this is very important for any chat based interface. Most (all?) implementations out there primarily ignore this issue, and treat each question as independent. This breaks down when someone wants to ask a follow up question in a natural way, or refer to pieces of context in the prior questions or answers.
The primary way to do this in LangChain is with memory in a conversation chain. In the simplest implementation of this, the previous lines of conversation are added as context to the prompt. However, this breaks down a bit for our use case, as not only do we care about adding the conversational history to the prompt, but we also care about using it to determine which documents to fetch. If asking a follow up question, we need to know what that follow up question is about in order to fetch relevant documents.
Therefore, we created a new chain that had the following steps:
- Given a conversation history and a new question, create a single, standalone question
- Use that question in a normal Vector Database Question Answer Chain.
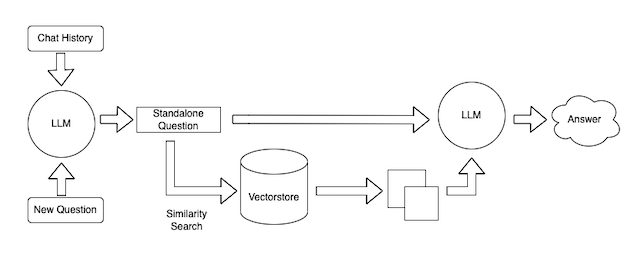
We were a bit worried that using that question in the Vector Database Question Answer Chain would be lossy and lose some of the context, but we did not really observe any negative effects there.
In the process of getting to this solution, we tried a few other things with respect to fetching documents from the Vector Database that did not work nearly as well:
- Embedding the chat history + question together: once the chat history got long, would massively overly index on that if you were trying to change topics.
- Embedding the chat and question separately and then combining results: better than the above, but still pulled too much information about previous topics into context
Prompt Engineering
When building a chatbot, delivering a good user experience is crucial. In our use case, there were a few important considerations:
- Each answer should include an official source to the documentation.
- If the answer includes code, it should be properly formatted as a code block.
- The chatbot should stay on topic and be upfront about not knowing an answer.
We were able to achieve all of this with the following prompt:
You are an AI assistant for the open source library LangChain. The documentation is located at https://langchain.readthedocs.io.
You are given the following extracted parts of a long document and a question. Provide a conversational answer with a hyperlink to the documentation.
You should only use hyperlinks that are explicitly listed as a source in the context. Do NOT make up a hyperlink that is not listed.
If the question includes a request for code, provide a code block directly from the documentation.
If you don't know the answer, just say "Hmm, I'm not sure." Don't try to make up an answer.
If the question is not about LangChain, politely inform them that you are tuned to only answer questions about LangChain.
Question: {question}
=========
{context}
=========
Answer in Markdown:
In this prompt, we’re requesting a response in Markdown format. This allows us to render the answer in a visually appealing format with proper headings, lists, links, and code blocks.
Here’s how it looks on our Next.js frontend:
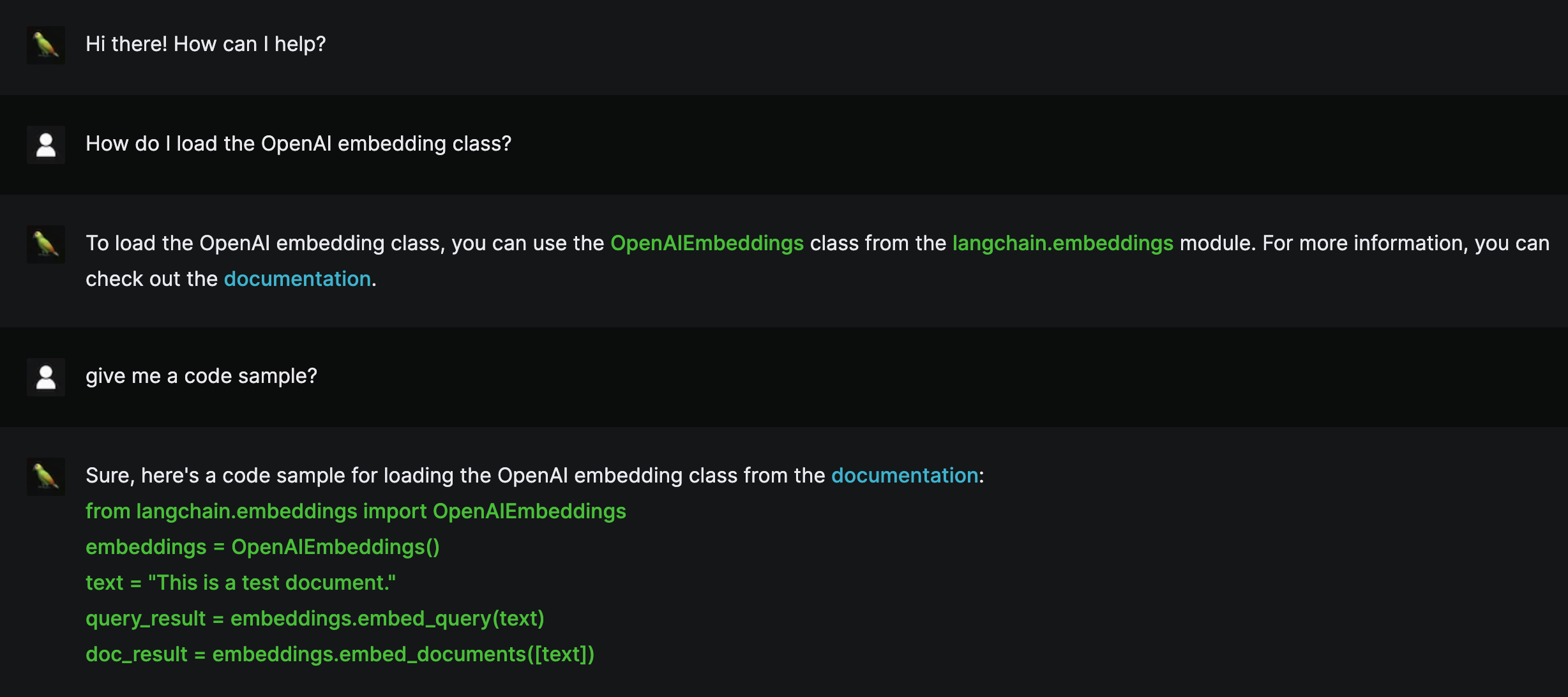
The hyperlink in each answer is constructed using the base URL to the documentation, which we’re providing upfront in our prompt. Since we scraped the documentation website in our data ingestion pipeline, we’re able to identify the path to the answer and combine it with the base URL to create a working link.
To keep the chatbot as accurate as possible, we keep the temperature at 0 and include instructions in the prompt to say “Hmm, I’m not sure.” if given a question with an unclear answer. To keep the conversation on topic, we also include instructions to decline questions that are not about LangChain.
Striking a balance between speed and performance:
- We began our testing with longer Markdown answers. Although the answer quality was great, the response times were slightly longer than desired.
- We spent a lot of time refining the prompt and experimenting with different keywords and sentence structures to improve performance.
- One method was to mention the Markdown keyword at the end of the prompt. For our use case, we were able to return formatted outputs with only a single mention of the keyword.
- Providing the base URL near the beginning of the prompt improved overall performance - it gives the model a working reference to create a final URL to include in the answer.
- We found that using the singular form, such as "a hyperlink" instead of "hyperlinks" and "a code block" instead of "code blocks", improves response times.
Future Work
We're just getting started and we welcome feedback from the LangChain community. We can't wait to introduce new features and improvements in the near future! Follow us on Twitter for updates and checkout the code.
If you like this and want a more advanced version of this for your codebase, you should check out ClerkieAI. Their question answer bot is live on our Discord.