
In 2023 we saw an explosion of interest in Generative AI upon the heels of ChatGPT. All companies - from startups to enterprises - were (and still are) trying to figure out their GenAI strategy.
"How can we incorporate GenAI into our product? What reference architectures should we be following? What models are best for our use case? What is the technology stack we should be using? How can we test our LLM applications?"
These are all questions that companies are asking themselves. In a time of such uncertainty, everyone also wants to know what everyone else is doing. There have been a few attempts to shed light on this so far, but with LangChain's unique position in ecosystem we feel like we can shed real light into how teams are actually building with LLMs.
To do this, we turn to anonymized metadata in LangSmith. LangSmith is our cloud platform aimed at making it easy to go from prototype to production. It provides capabilities like tracing, regression testing and evaluation, and more. While still in private beta, we are letting people off the waitlist everyday so sign up here, and if you are interested in enterprise access or support, please reach out.
Through this we can answer questions about what people are building, how they are building those things, and how they are testing those applications. All stats are taken from 2023-07-02 to 2023-12-11.
What are people building?

Here we take a look at some of the common things people are building.
Although LangSmith integrates seamlessly with LangChain, it is also easily usable outside of the LangChain ecosystem. We see that about 15% of usage in LangSmith come from users NOT using LangChain. We've invested a lot of work in making the onboarding experience for ALL the above components work just as well for whether you are using LangChain or not.
Retrieval has emerged as the dominant way to combine your data with LLMs. LangChain offers integrations with 60+ vectorstores (the most common way to index unstructured data). LangChain also offers many advanced retrieval strategies. We see that 42% of complex queries involve retrieval - speaking both to the importance of retrieval and how easy LangChain has made it.
Finally, we see that about 17% of complex queries are part of an agent. Agents involve letting the LLM decide what steps to take, which allows your system to better handle complex queries or edge cases. However, they are still not super reliable or performant, which is probably why we don't see more.
LCEL Usage
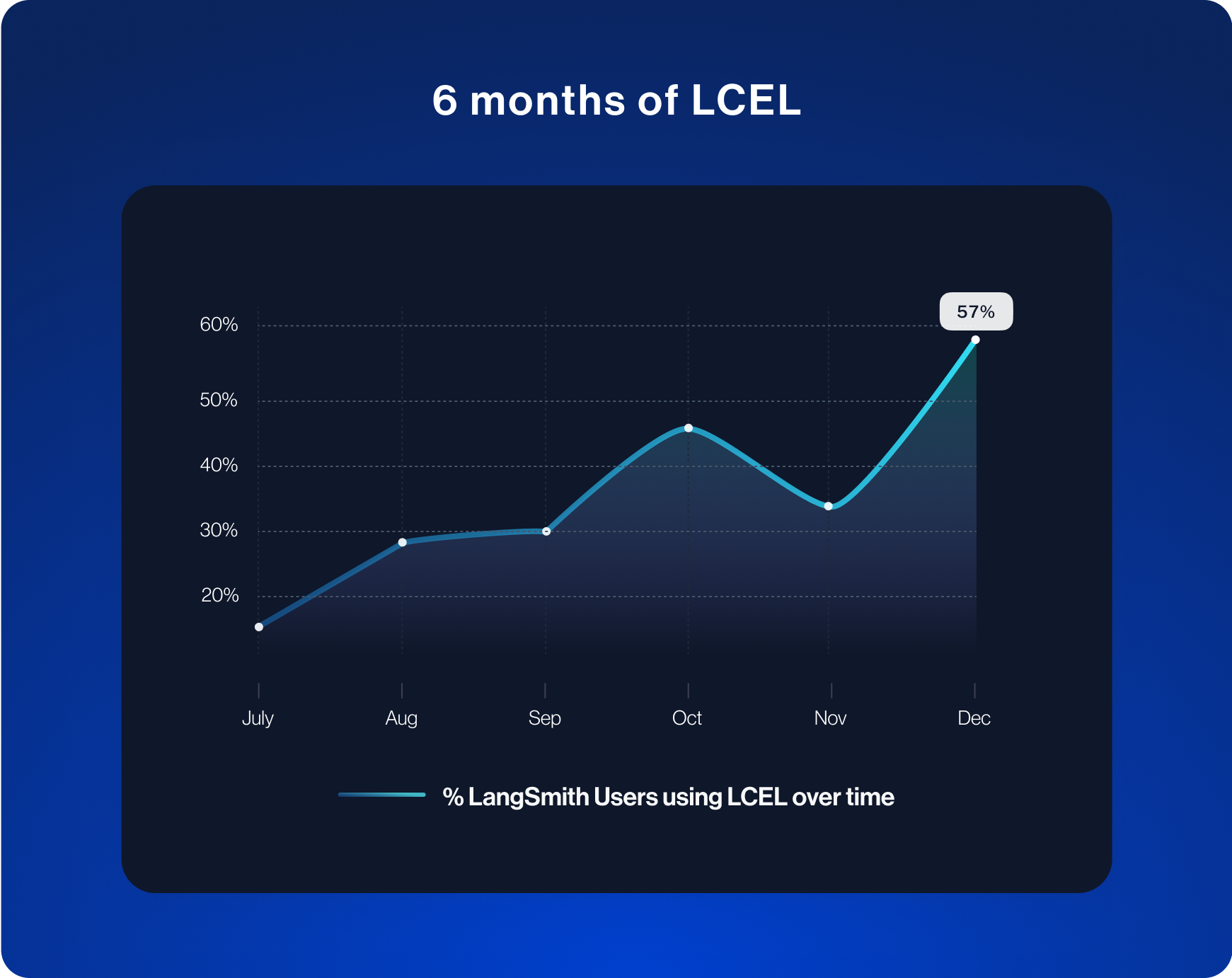
One of the big additions to LangChain over the past months has been LangChain Expression Language (or LCEL for short). This is an easy way to compose components together, making it perfect for creating complex, customized chains. It is still super early on in this whole GenAI journey, and everyone is trying to figure out how exactly to make LLMs work for them. This involves a lot of experimentation and customization. LCEL makes this easy - and we saw its usage rapidly increase over the past few months as we've added more features and improved documentation.
Most Used LLM Providers

The new technology in all of this are LLMs. So which LLM providers are people using?
To no surprise, we see OpenAI at the top, with AzureOpenAI right behind it. OpenAI has emerged as the leading LLM provider of 2023, and Azure (with more enterprise guarantees) has seized that momentum well.
Other hosting services that offer proprietary models include Anthropic (3rd), Vertex AI (4th), and Amazon Bedrock (8th).
On the open source model side, we see Hugging Face (4th), Fireworks AI (6th), and Ollama (7th) emerge as the main ways users interact with those models.
Note that these rankings are based on number of users who have used a given provider.
Most Used OSS Model Providers

A lot of attention recently has been given to open source models, with more and more providers racing to host them at cheaper and cheaper costs. So how exactly are developers accessing these open source models?
We see that the people are mainly running them locally, with options to do so like Hugging Face, LlamaCpp, Ollama, and GPT4All ranking high.
Of providers offering API access to OSS models, Fireworks AI leads the pack, followed by Replicate, Together, and Anyscale.
Note that these rankings are based on number of users who have used a given provider.
Most Used Vectorstores

As mentioned earlier, retrieval is a huge part of LLM applications. Vectorstores are emerging as the primary way to retrieve relevant context. In LangChain we have 60+ vectorstore integrations - which ones are people using most?
We see that local vectorstores are the most used, with Chroma, FAISS, Qdrant and DocArray all ranking in the top 5. These rankings are based on the number of users who had used a given vectorstore, so it makes sense that local, free vectorstores are the most used if you count that way.
Of the hosted offerings, Pinecone leads the pack as the only hosted vectorstore in the top 5. Weaviate follows next, showing that vector-native databases are currently more used than databases that add in vector functionality.
Of databases that have added in vector functionality, we see Postgres (PGVector), Supabase, Neo4j, Redis, Azure Search, and Astra DB leading the pack.
Note that these rankings are based on number of users who have used a given provider.
Most Used Embeddings

In order to use a vectorstore, you need to calculate embeddings for pieces of text. So how are developers doing that?
Similar to LLMs, OpenAI reigns supreme - but we see more diversity after that. Open source providers are more used, with Hugging Face coming in 2nd most used, and GPT4All and Ollama also in the top 8. On the hosted side, we see that Vertex AI actually beats out AzureOpenAI, and Cohere and Amazon Bedrock are not far behind.
Top Advanced Retrieval Strategies

Just doing cosine similarity between embeddings only gets you so far in retrieval. We see a lot of people relying on advanced retrieval strategies - a lot of which we've implemented and documented in LangChain.
Even still - the most common retrieval strategy we see is not a built-in one but rather a custom one. This speaks to:
- The ease of implementing a custom retrieval strategy in LangChain
- The need to implement custom logic in order to achieve the best performance
After that, we see more familiar names popping up:
- Self Query - which extracts metadata filters from user's questions
- Hybrid Search - mainly through provider specific integrations like Supabase and Pinecone
- Contextual Compression - which is postprocessing of base retrieval results
- Multi Query - transforming a single query into multiple, and then retrieving results for all
- TimeWeighted VectorStore - give more preference to recent documents
How are people testing?

Evaluation and testing has emerged as one of the largest pain points developers run into when building LLM applications, and LangSmith has emerged as one of the best ways to do this.
We see that most users are able to formulate some metrics to evaluate their LLM apps - 83% of test runs have some form of feedback associated with them. Of the runs with feedback, they average 2.3 different types of feedback, suggesting that developers are having difficulty finding a single metric to rely entirely on, and instead use multiple different metrics to evaluate.
Of the feedback logged, the majority of them use an LLM to evaluate the outputs. While some have expressed concern and hesitation around this, we are bullish on this as an approach and see that in practice it has emerged as the dominant way to test. Another notable datapoint is that nearly 40% of evaluators are custom evaluators. This is in line with the fact that we've observed that evaluation is often really specific to the application being worked on, and there's no one-size-fits-all evaluator to rely on.
What are people testing?

We can see that most people are still primarily concerned with the correctness of their application (as opposed to toxicity, prompt leakage, or other guardrails). We can also see from the low usage of Exact Matching as an evaluation technique that judging correctness is often quite complex (you can't just compare the output exactly as is)!
Conclusion
As the first real year of LLM app development comes to a close, we are hearing from a lot of teams that they want to close the gap from prototype to production. Hopefully sharing these usage statistics helps shine some light on what people are building, how they are building those things, and how they are testing those things.
LangSmith is emerging as the dominant way that teams are bringing their applications from prototype to production - whether they are using LangChain or not. If you are interested in enterprise access or support, please reach out or sign up here.