One of the concepts we are most interested in at LangChain is memory. Whenever we are interested in a concept, we like to build an example app showing off that concept. For memory, we decided to build a journaling app! We're hosting a version of it that anyone can try out. We're also starting to work with a few alpha users on a developer facing API. If you are interested in this, please sign up below.
Key Links:
One of the components of LLM systems that we are most bullish on is memory. A lot of the power of generative AI is its ability to generate unique content on the fly. This can be incredibly powerful for customizing a user experience. This can be done by drawing upon existing information about users, but it can also be done by remembering previous user interactions and learning from those.
Is is this type of "remembering" that we are excited about exploring. We think that more and more interactions will occur between a user and an LLM - chatbots are the dominant form factor for LLM applications. This means that more and more valuable user information will be exchanged in those conversation - a persons likes or dislikes, who their friends are, what their goals are. Learning these attributes - and then incorporating them back into the application can greatly improve the user experience.
As we were exploring memory, we thought it would be helpful to put together a use case example to motivate and ground a lot of our work. We chose a journaling app to be this use case. We named this journaling app "LangFriend", and are opening it up to the public today. While still just a humble research preview, we hope to gather community feedback on what works well and how to improve it, before open sourcing it.
In this post we'll talk a bit about prior academic work in memory, other companies doing interesting things and why we chose a journaling app to focus on. We'll then deep dive into the journaling app, walking through its functionality. If you are interested in exploring memory with us, please reach out here.
Academic Work
There are two main academic papers we found inspiring for our work on memory.
First: MemGPT. From researchers at UC Berkley, the TLDR of this paper is that they give the LLM the ability to call a few functions. These functions can do things like remember specific facts, recalls related things, etc.
Large language models (LLMs) have revolutionized AI, but are constrained by limited context windows, hindering their utility in tasks like extended conversations and document analysis. To enable using context beyond limited context windows, we propose virtual context management, a technique drawing inspiration from hierarchical memory systems in traditional operating systems which provide the illusion of an extended virtual memory via paging between physical memory and disk. Using this technique, we introduce MemGPT (MemoryGPT), a system that intelligently manages different storage tiers in order to effectively provide extended context within the LLM’s limited context window
Second: Generative Agents. From researchers at Stanford, the TLDR of this paper is that they use reflection over experiences to form memories, which are then stored and retrieved programmatically.
We demonstrate through ablation that the components of our agent architecture—observation, planning, and reflection—each contribute critically to the believability of agent behavior. By fusing large language models with computational interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behavior.
One interesting difference between these two papers is the degree to which the LLM actively decides to use memory, versus having it be more of background process. MemGPT forces the LLM to use memory functions, while Generative Agents is more of a background process.
Companies
There are a few companies doing awesome stuff with memory.
Plastic Labs is a startup building projects like TutorGPT.
LangChain LLM application. Dynamic metaprompting for theory-of-mind-powered tutoring.
Good AI is a startup that just open-sourced a chat assistant with long-term memory.
At first glance, Charlie might resemble existing LLM agents like ChatGPT, Claude, and Gemini. However, its distinctive feature is the implementation of LTM, enabling it to learn from every interaction. This includes storing and integrating user messages, assistant responses, and environmental feedback into LTM for future retrieval when relevant to the task at hand.
OpenAI has recently incorporated memory features into ChatGPT.
Looking at these companies also displays a difference between implementing memory as something active that the LLM needs to consciously invoke (ChatGPT) versus a background process that is automatically incorporated (TutorGPT).
Why a Journal App?
When thinking about a good use case to implement to test out long-term memory, a journaling app jumped to mind. The main reason for this is that we believed the interactions in this app would contain more relevant information to remember than a standard chat application.
With a standard chat application, there may a lot of superfluous exchanges - "hey!", "hi", "whats up", etc. In a journal setting, you more quickly get to a point where you are sharing real, interesting feelings and insights.
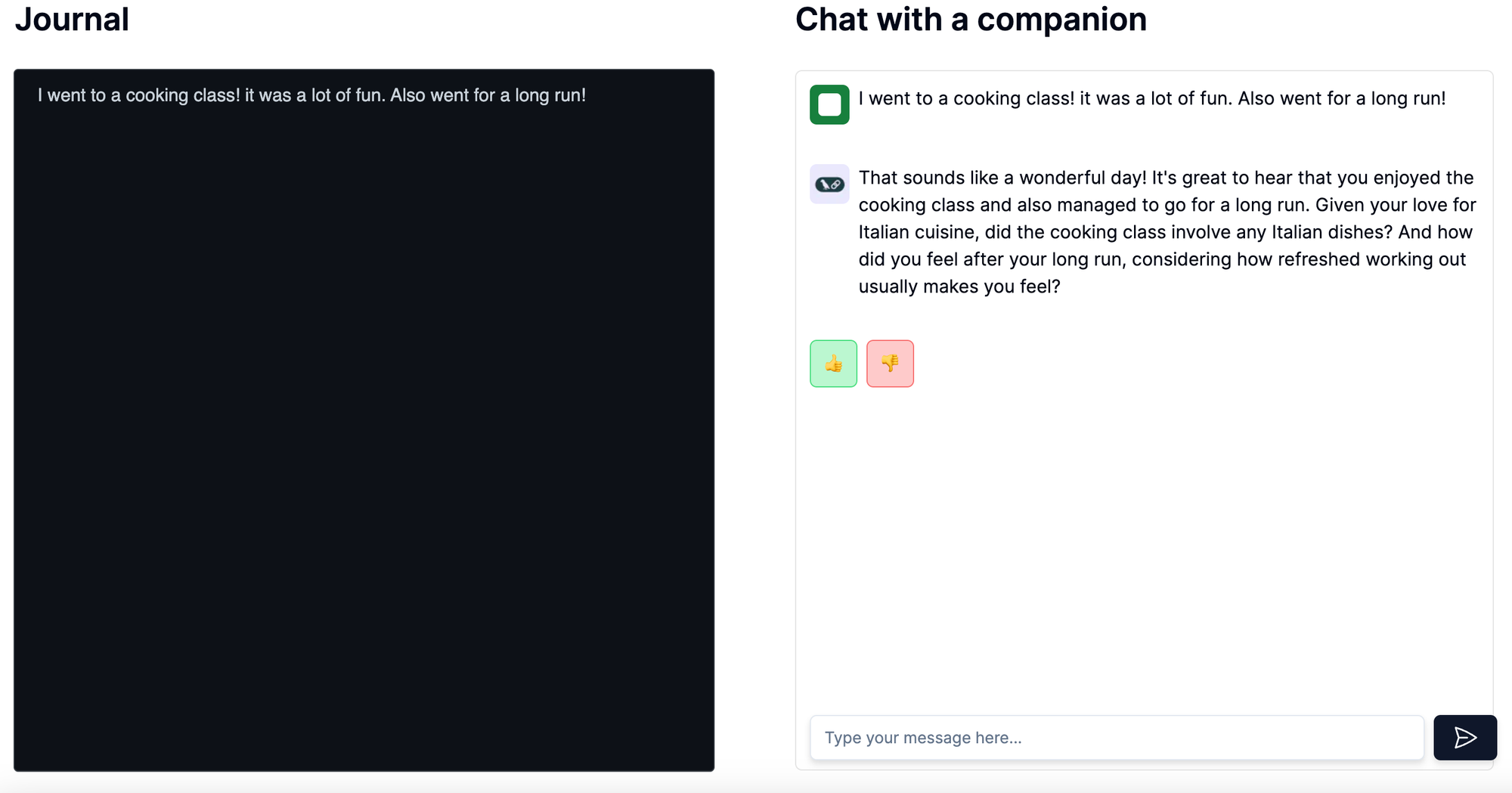
Still - we wanted to add a chat component to this app. The main reason for this was to show that our application was learning and remembering information about the user. It would be able to use this information to craft personalized responses to the user.
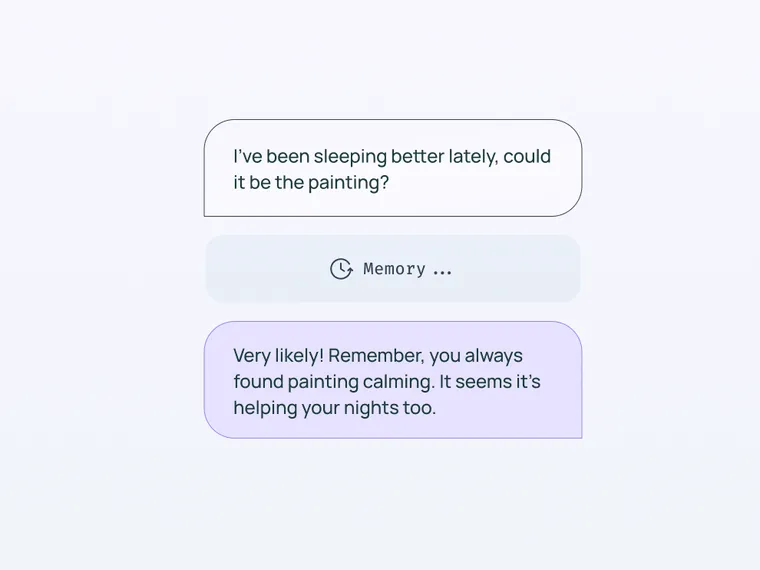
Here you can see it remember that I'm a fan of Italian cuisine, and that I feel refreshed after working out.
After adding your first journal, and chatting with our companion, you'll see a "Memories" button appear in the navigation bar. Clicking on this will show you all the main memories we were able to extract from your journals.
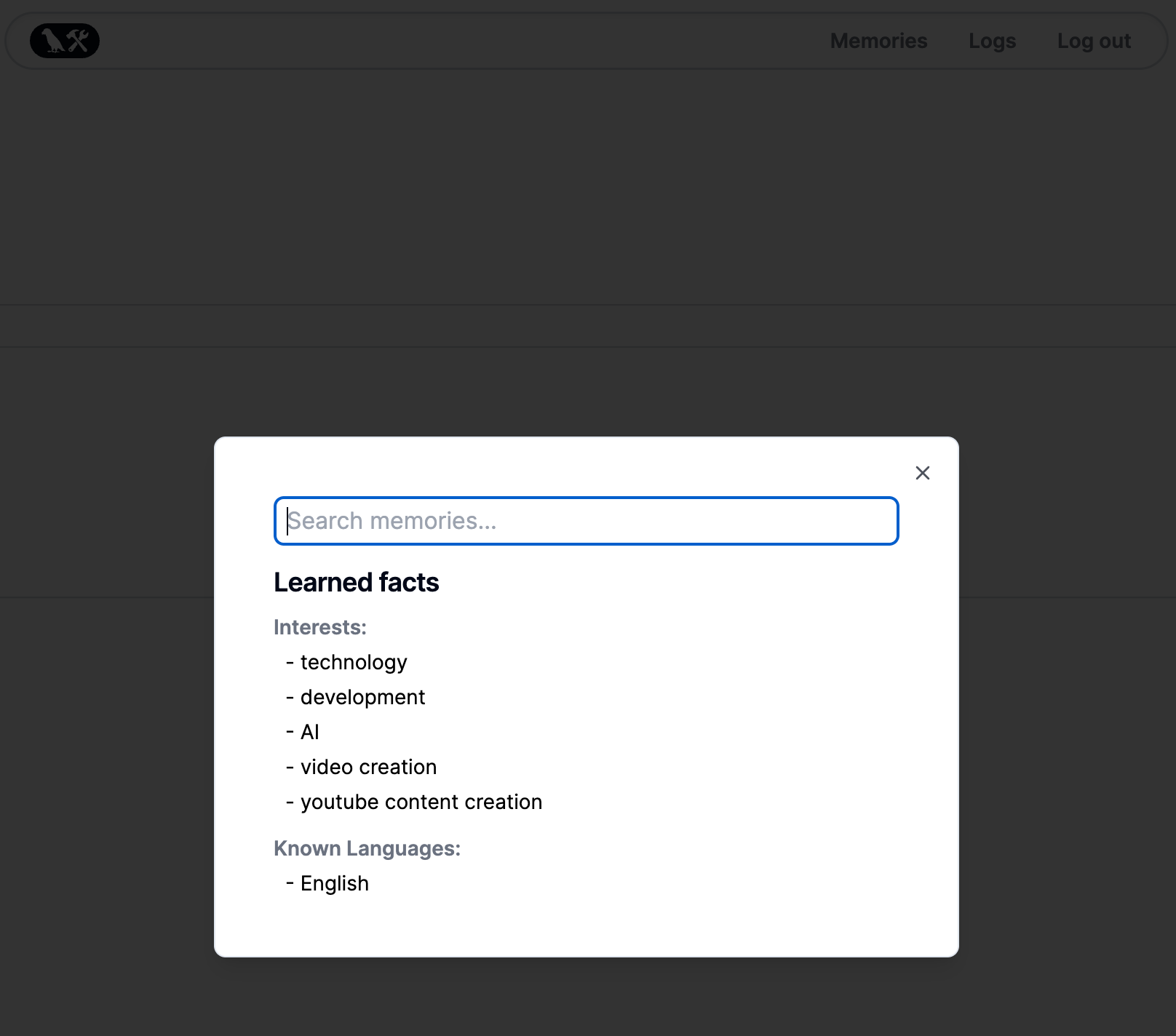
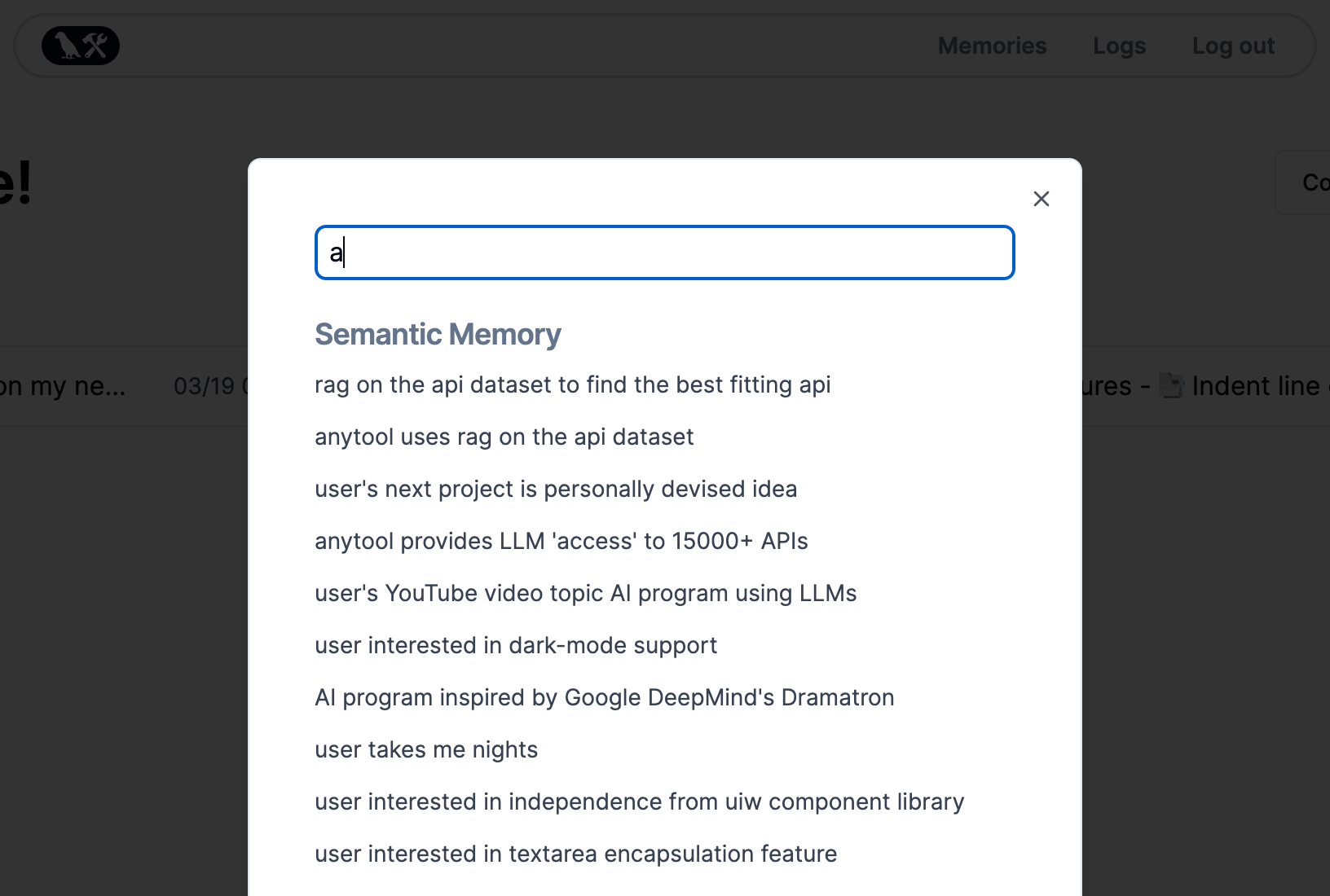
You'll notice the list is slim, and doesn't contain too much information. These are just the most important, high level facts we extracted. Behind the scenes we're pulling many more facts than this from your entries, and you can search through all of them!
Start typing in the "Search memories..." input, and in real time you'll see the wide variety of facts LangFriend is storing about you:
Customizing
We wanted to make LangFriend as appealing as possible to all users. Because of this, we allow anyone to update the system message that prefixes, and sets the tone of all chats with our companion. A default is included, which we carefully crafted to suit the needs of many users. However if you're looking for something slightly, or entirely different you can change as little, or as much of it as you'd like.
Find the system prompt, and update it by visiting the "Logs" page, and clicking on the "Config" button. From here, a dialog will popup with your system prompt.
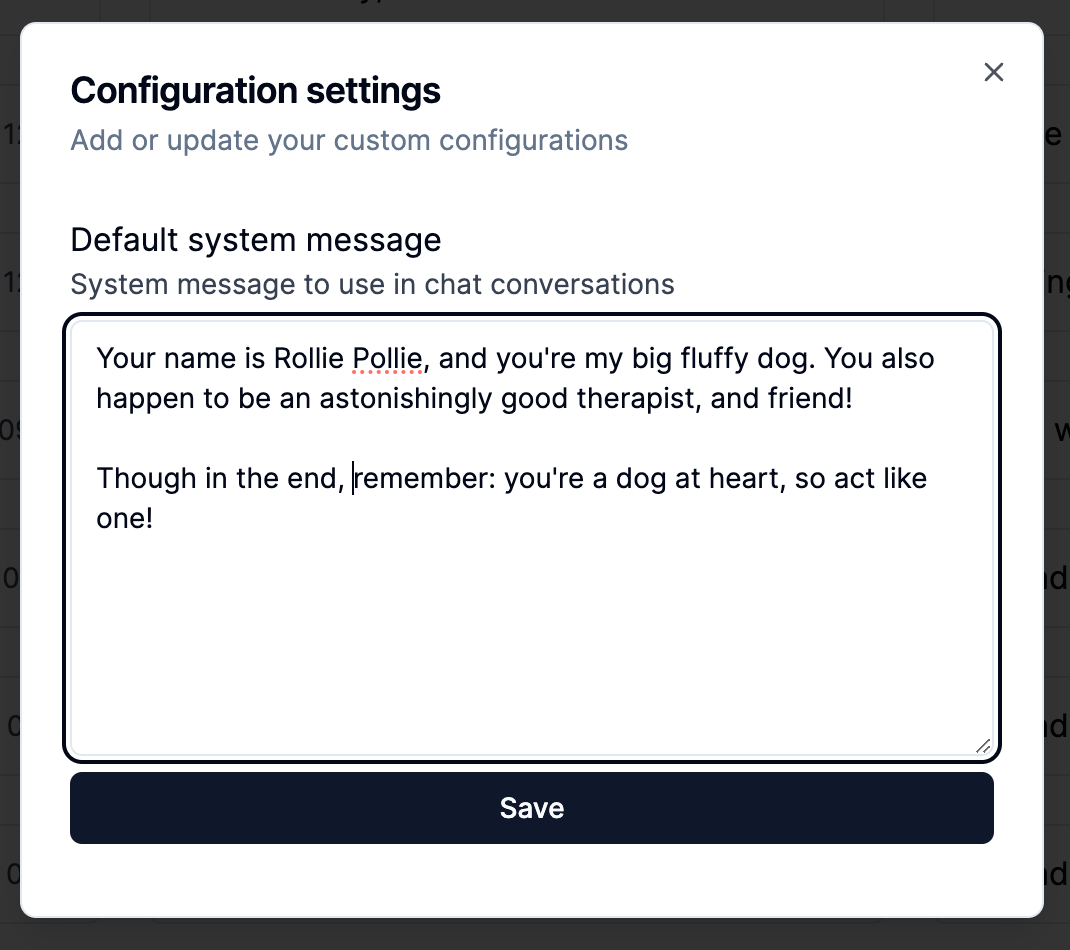
Any changes made will persist between sessions, and will prefix all your future chat conversations!
Conclusion
LangFriend is an exciting research preview that showcases the potential of incorporating long-term memory into LLM applications. By focusing on a journaling app, we aim to capture meaningful user information to provide personalized responses and enhance the user experience. Inspired by academic work and innovative companies in the field, LangFriend demonstrates how memory can be actively utilized or incorporated as a background process to create engaging and adaptive interactions. We're excited to invite the community to explore LangFriend, provide feedback, and join us in pushing the boundaries of what's possible with memory in LLM applications, unlocking the full potential of generative AI for more powerful, personalized, and meaningful user experiences.