
Today we're releasing the LangMem SDK, a library that helps your agents learn and improve through long-term memory.
It provides tooling to extract information from conversations, optimize agent behavior through prompt updates, and maintain long-term memory about behaviors, facts, and events.
You can use its core API with any storage system and within any Agent framework, and it integrates natively with LangGraph's long-term memory layer. We are also launching a managed service that provides additional long-term memory results for free - sign up here if you are interested in using it in production.
Our goal is to make it easier for anyone to build AI experiences that become smarter and more personalized over time. This work builds on our previous work of the hosted LangMem alpha service and LangGraph's persistent long-term memory layer.
To install, just run:
pip install -U langmemQuick links
On memory and adaptive agents
Agents use memory to learn, but the way their memories are formed, stored, updated, and retrieved impacts types of things your agent can learn to know or do. At LangChain, we’ve found it useful to first identify the capabilities your agent needs to be able to learn, map these to specific memory types or approaches, and only then implement them in your agent. Before adding memory, we think you should consider:
- What behavior should be learned (user-informed) vs. pre-defined?
- What types of knowledge or facts should be tracked?
- What conditions should trigger a memory to be recalled?
While there may be some overlap, each memory type serves distinct functions when building adaptive agents:
| Memory Type | Purpose | Agent Example | Human Example | Typical Storage Pattern |
|---|---|---|---|---|
| Semantic | Facts & Knowledge | User preferences; knowledge triplets | Knowing Python is a programming language | Profile or Collection |
| Episodic | Past Experiences | Few-shot examples; Summaries of past conversations | Remembering your first day at work | Collection |
| Procedural | System Behavior | Core personality and response patterns | Knowing how to ride a bicycle | Prompt rules or Collection |
So then revisiting our questions above:
- What behavior should be learned vs. fixed? Some aspects of your agent's behavior may need to adapt based on feedback and experience, while others should remain consistent. This will guide whether you need procedural memory to evolve behavior patterns, or if fixed prompt rules are sufficient. This is similar in spirit to the concept of the "chain of command" in OpenAI's model spec since learned behaviors are shaped by user interactions.
- What types of knowledge or facts should be tracked?
Different use cases require different types of knowledge persistence. You might need semantic memory to maintain facts about users or domains, episodic memory to learn from successful interactions, or both working together. - What conditions should trigger a memory to be recalled?
Some memories (core procedural memory) may be data-independent - they are always present in the prompt. Some are data-dependent and may be recalled based on semantic similarity. Others may be recalled based on a combination of application context, similarity, time, etc.
A related concern is memory privacy. In LangMem, all memories are given a namespace. The most common namespaces would include a use_id in order to prevent cross-over of user memories. In general, memories can be scoped to particular app routes, to individual users, shared across teams, or the agent could learn core procedures across all users. The extent of memory sharing is determined both by privacy and performance needs.
All of these memory types are meant to address recall beyond individual conversations. Memory within a given conversation, or thread, is already handled reasonably well using checkpointing in LangGraph (so long as it doesn’t extend beyond the model’s effective context window), which serves as the “short-term” or “working” memory system for your agent.
Note that this also differs from standard RAG in a couple ways. One is the way the information is gained: through interaction rather than offline data ingestion. The other is in the type of information that’s prioritized. Below, we will share more about the memory types in more detail.
Semantic memory: facts
Semantic memory stores key facts (and their relationships) and other information that ground an agent's responses. It lets your agent remember important details that wouldn’t be “pre-trained” into the model itself and that isn’t accessible from a web search or generic retriever.

Code
from langmem import create_memory_manager
manager = create_memory_manager(
"anthropic:claude-3-5-sonnet-latest",
instructions="Extract user preferences and facts",
enable_inserts=True
)
# Process conversation to extract facts
conversation = [
{"role": "user", "content": "Alice manages the ML team and mentors Bob, who is also on the team."}
]
memories = manager.invoke({"messages": conversation})
# Extract and store new knowledge
conversation2 = [
{"role": "user", "content": "Bob now leads the ML team and the NLP project."}
]
update = manager.invoke({"messages": conversation2, "existing": memories})
memories = [
ExtractedMemory(
id="27e96a9d-8e53-4031-865e-5ec50c1f7ad5",
content=Memory(
content="Alice manages the ML team and mentors Bob, who is also on the team."
),
),
ExtractedMemory(
id="e2f6b646-cdf1-4be1-bb40-0fd91d25d00f",
content=Memory(
content="Bob now leads the ML team and the NLP project."
),
),
]
In our experience, semantic memory is the most common form of “memory” that engineers ask for and imagine (after, perhaps, short-term “conversation history” memory) when they first seek to add a memory layer.
It also (debatably) has the most overlap with traditional RAG systems. If the knowledge is available from another store (docs site, codebase, etc.), and if that store is the source of truth (rather than the interactions themselves), then your agent may work fine simply retrieving over that knowledge corpus directly. Or you can periodically ingest that knowledge to integrate that in the semantic memory system. If the knowledge is regarding personalization (about the user) or conceptual relationships not found in the raw materials, then semantic memory is perfect for you.
Procedural memory: evolving behavior
Procedural memory represents internalized knowledge of how to perform tasks. It is distinct from episodic memory in that it focuses on generalized skills, rules, and behaviors. For AI agents, procedural memory is saved across a combination of model weights, agent code, and agent's prompt that collectively determine the agent's functionality. In LangMem, we focus on saving learned procedures as updated instructions in the agent's prompt.
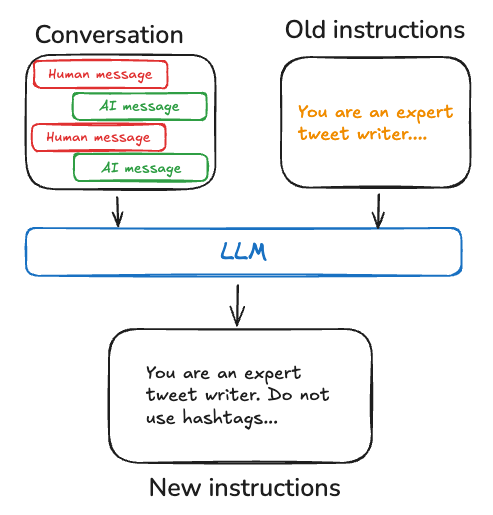
Code
from langmem import create_prompt_optimizer
trajectories = [
(
[
{"role": "user", "content": "Tell me about Mars"},
{"role": "assistant", "content": "Mars is the fourth planet..."},
{"role": "user", "content": "I wanted more about its moons"},
],
{"score": 0.5, "comment": "Missed key information about moons"}
)
]
optimizer = create_prompt_optimizer(
"anthropic:claude-3-5-sonnet-latest",
kind="metaprompt",
config={"max_reflection_steps": 3}
)
improved_prompt = optimizer.invoke({
"trajectories": trajectories,
"prompt": "You are a planetary science expert"
})
"""
You are a helpful assistant..
If the user asks about astronomy, explain topics clearly using real-world examples and current scientific data.
Use visual references when helpful and adapt to the user's knowledge level.
Balance practical observational astronomy with theoretical concepts, providing either viewing advice or technical explanations based on user needs.
"""The optimizer is prompted with identifying patterns in successful and unsuccessful interactions, then updating the system prompt to reinforce effective behaviors. This creates a feedback loop where the agent's core instructions evolve based on observed performance.
Informed by our work on prompt optimization, LangMem provides multiple algorithms for generating prompt update proposals, including: metaprompt uses reflection & additional “thinking” time to study the conversations and then use a meta-prompt to propose the update; gradient explicitly divides the work into separate steps of critique and prompt proposals to further simplify the task at each step; and a simple prompt_memory algorithm that attempts to do the above in a single step.
Episodic memory: events and experiences
Episodic memory stores memories of past interactions. It is distinct from procedural memory in its focus on recalling specific experiences. It is distinguished from semantic memory in its focus on past events rather than general knowledge, answering “how” the agent solved a particular problem rather than just “what” the answer was. It often takes the form of few-shot examples, with each example distilled from a longer raw interaction. LangMem doesn't yet support opinionated utilities for episodic memory.
Try it today
Check out the docs for more examples on how to implement custom memory systems using LangMem, including guides on how to:
- Create an agent that actively manage its own memory
- Share memories between agents
- Namespace memories to organize information by user or team.
- Integrate LangMem in your custom framework
If your team wants to add personalization or life-long learning to your agents, fill out our interest form.
Join our team
We're recruiting engineers to build the world's best runtime for adaptive agents. If you're interested in designing and building with us, check out our open positions.