
At Sequoia’s AI Ascent conference in March, I talked about three limitations for agents: planning, UX, and memory. Check out that talk here. In this post I will dive more into memory. See the previous post on planning here, and the previous posts on UX here, here, and here.
If agents are the biggest buzzword of LLM application development in 2024, memory might be the second biggest. But what even is memory?
At a high level, memory is just a system that remembers something about previous interactions. This can be crucial for building a good agent experience. Imagine if you had a coworker who never remembered what you told them, forcing you to keep repeating that information - that would be insanely frustrating!
People often expect LLM systems to innately have memory, maybe because LLMs feel so human-like already. However, LLMs themselves do NOT inherently remember things — so you need to intentionally add memory in. But how exactly should you think about doing that?
Memory is application-specific
We’ve been thinking about memory for a while, and we believe that memory is application-specific.
What Replit’s coding agent may choose to remember about a given user is very different than what Unify’s research agent might remember. Replit may choose to remember Python libraries that the user likes; Unify may remember the industries of the companies a user is researching.
Not only does what an agent remember vary by application, but how the agent remembers may differ too. As discussed in a previous post, a key aspect of agents is the UX around them. Different UXs offer distinct ways to gather and update feedback accordingly.
So, how are we approaching memory at LangChain?
This philosophy guided much of our development of the Memory Store, which we added into LangGraph last week.
Types of memory
While the exact shape of memory that your agent has may differ by application, we do see different high level types of memory. These types of memory are nothing new - they mimic human memory types.
There’s been some great work to map these human memory types to agent memory. My favorite is the CoALA paper. Below is my rough, ELI5 explanation of each type and practical ways for how todays agents may use and update this memory type.
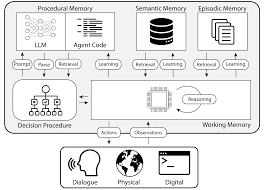
Decision procedure diagram from CoALA paper (Sumers, Yao, Narasimhan, Griffiths 2024)
Procedural Memory
This term refers to long-term memory for how to perform tasks, similar to a brain’s core instruction set.
Procedural memory in humans: remembering how to ride a bike.
Procedural memory in Agents: the CoALA paper describes procedural memory as the combination of LLM weights and agent code, which fundamentally determine how the agent works.
In practice, we don’t see many (any?) agentic systems that update the weights of their LLM automatically or rewrite their code. We do, however, see some examples of an agent updating its own system prompt. While this is the closest practical example, it remains relatively uncommon.
Semantic Memory
This is someone’s long-term store of knowledge.
Semantic memory in humans: it’s composed of pieces of information such as facts learned in school, what concepts mean and how they are related.
Semantic memory in agents: the CoALA paper describes semantic memory as a repository of facts about the world.
Today, this is most often used by agents to personalize an application.
Practically, we see this being done by using an LLM to extract information from the conversation or interactions the agent had. The exact shape of this information is usually application-specific. This information is then retrieved in future conversations and inserted into the system prompt to influence the agent’s responses.
Episodic Memory
This refers to recalling specific past events.
Episodic memory in humans: when a person recalls a particular event (or “episode”) experienced in the past.
Episodic memory in agents: the CoALA paper defines episodic memory as storing sequences of the agent’s past actions.
This is used primarily to get an agent to perform as intended.
In practice, episodic memory is implemented as few-shot example prompting. If you collect enough of these sequences, then this can be done via dynamic few-shot prompting. This is usually great for guiding the agent if there is a correct way to perform specific actions that have been done before. In contrast, semantic memory is more relevant if there isn’t necessarily a correct way to do things, or if the agent is constantly doing new things so the previous examples don’t help much.
How to update memory
Besides just thinking about the type of memory to update in their agents, we also see developers thinking about how to update agent memory.
One way to update agent memory is “in the hot path”. This is where the agent system explicitly decides to remember facts (usually via tool calling) before responding. This is the approach taken by ChatGPT.
Another way to update memory is “in the background”. In this case, a background process runs either during or after the conversation to update memory.
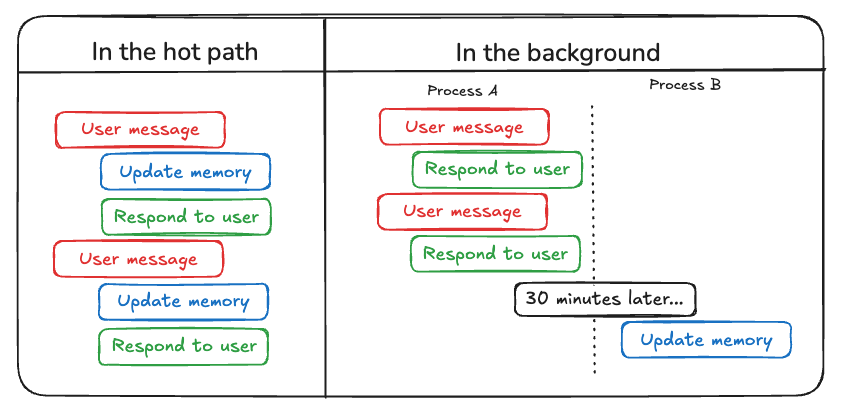
Comparing these two approaches, the “in the hot path” approach has the downside of introducing some extra latency before any response is delivered. It also requires combining the memory logic with the agent logic.
However, running in the background avoids those issues - there’s no added latency, and memory logic remains separate. But running “in the background” also has its own drawbacks: the memory is not updated immediately, and extra logic is needed determine when to kick off the background process.
Another way to updating memory involves user feedback, which is particularly relevant to episodic memory. For example, If the user marks an interaction as a positive one, you can save that feedback to recall in the future.
Why do we care about memory for agents?
How does this impact what we’re building at LangChain? Well, memory greatly affects the usefulness of an agentic system, so we’re extremely interested in making it as easy as possible to leverage memory for applications
To this end, we’ve built a lot of functionality for this into our products. This includes:
- Low-level abstractions for a memory store in LangGraph to give you full control over your agent’s memory
- Template for running memory both “in the hot path” and “in the background” in LangGraph
- Dynamic few shot example selection in LangSmith for rapid iteration
We’ve even built a few applications of our own that leverage memory! It’s still early though, so we’ll keep on learning about agent memory and the areas it can be used effectively 🙂