Key Links
- LangChain public benchmark evaluation notebooks
- LangChain template for multi-modal RAG on presentations
Motivation
Retrieval augmented generation (RAG) is one of the most important concepts in LLM app development. Documents of many types can be passed into the context window of an LLM, enabling interactive chat or Q+A assistants. While many of the RAG apps to date have focused on text, a great deal of information is conveyed as visual content. As an example, slide decks are common for use-cases ranging from investor presentations to internal company communications. With the advent of multi-modal LLMs like GPT-4V, it is now becoming possible to unlock RAG on the visual content often captured in slide decks. Below, we show two different ways to tackle this problem. We share a public benchmark for evaluating RAG on slide decks and use it highlight the trade-offs between these approaches. Finally, we provide a template for quickly creating multi-modal RAG apps for slide decks.
Design
The task is analogous to RAG apps on text documents: retrieve the relevant slide(s) based upon a user question and pass them to a multi-modal LLM (GPT-4V) for the answer synthesis. There are at least two general ways to approach this problem.
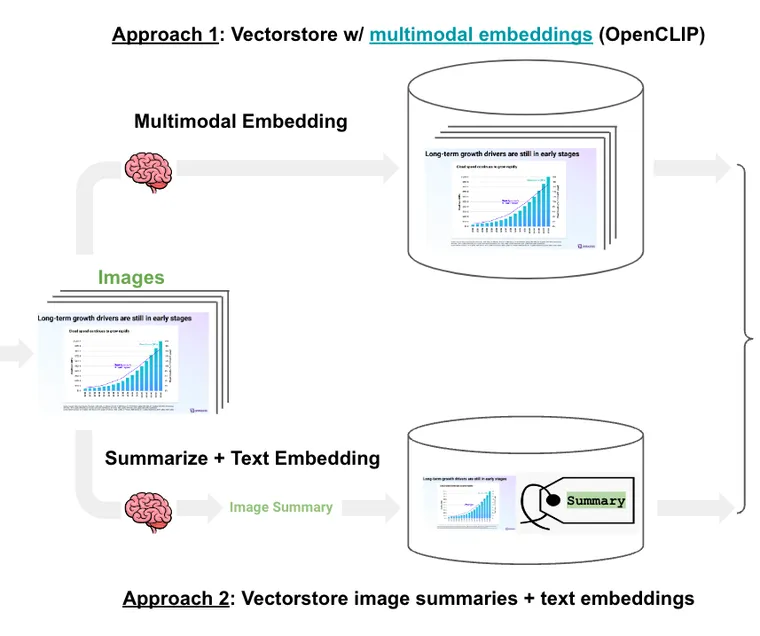
(1) Multi-modal embeddings: Extract the slides as images, use multi-model embeddings to embed each image, retrieve the relevant slide image(s) based upon the user input, and pass those images to GPT-4V for answer synthesis. We have previously released a cookbook for this with Chroma and OpenCLIP embeddings.
(2) Multi-vector retriever: Extract the slides as images, use GPT-4V to summarize each image, embed the image summaries with a link to the original images, retrieve relevant image based on similarity between the image summary and the user input, and finally pass those images to GPT-4V for answer synthesis. We have previously released a cookbook for this with the multi-vector retriever.
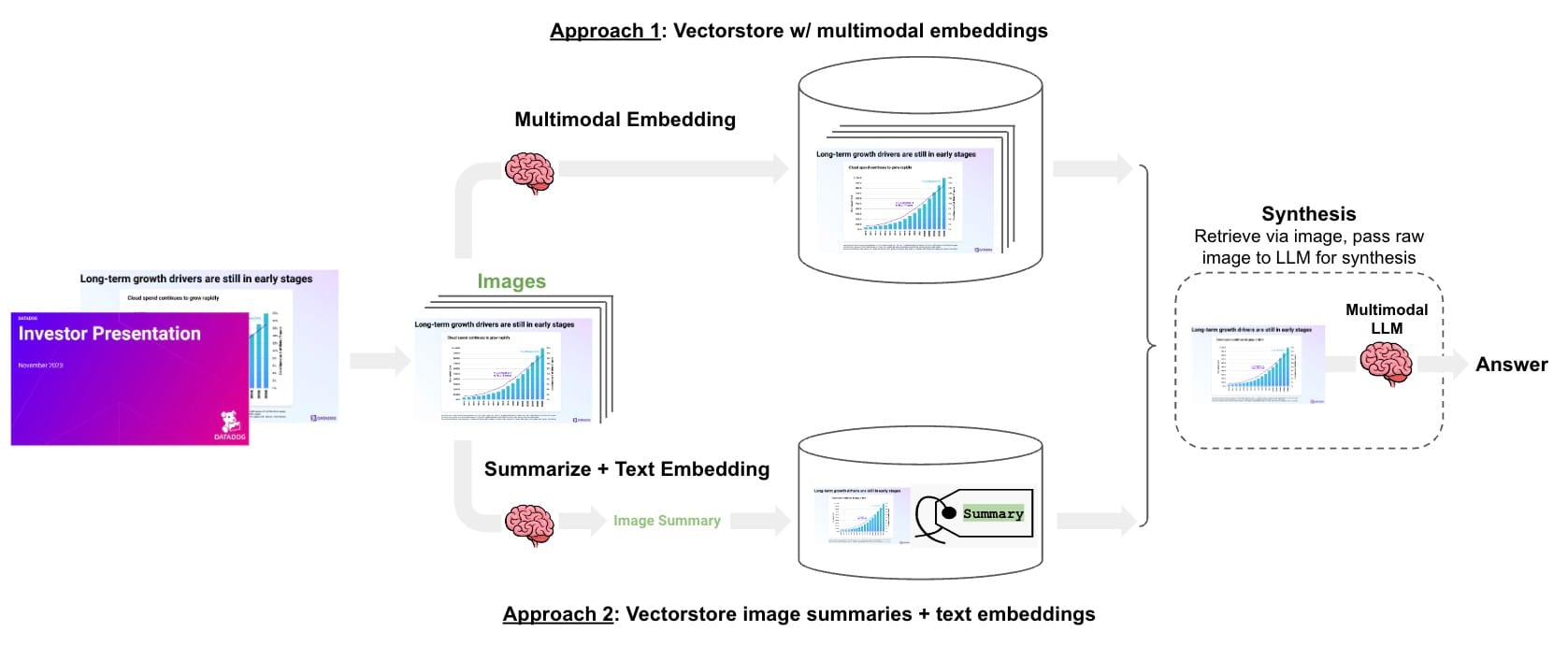
The trade-off between the approaches is straightforward: multi-modal embeddings are a simpler design, mirroring what we do with text-based RAG apps, but there are limited options and some questions about the ability to retrieve graphs or tables that appear visually similar. In contrast, image summaries use mature text embedding models and can describe graphs or figures with considerable detail. But this design suffers from higher complexity and cost of image summarization.
Evaluation
To evaluate these methods, we chose a recent earnings presentation from Datadog as a realistic slide deck with a mixture of visual and qualitative elements. We create a small public LangChain benchmark for this slide deck with 10 questions: you can see documentation for evaluating on this benchmark here and here.
As a sanity check, we can see that it is possible to retrieve slides based upon a natural language description of the slide content (below, see code here).
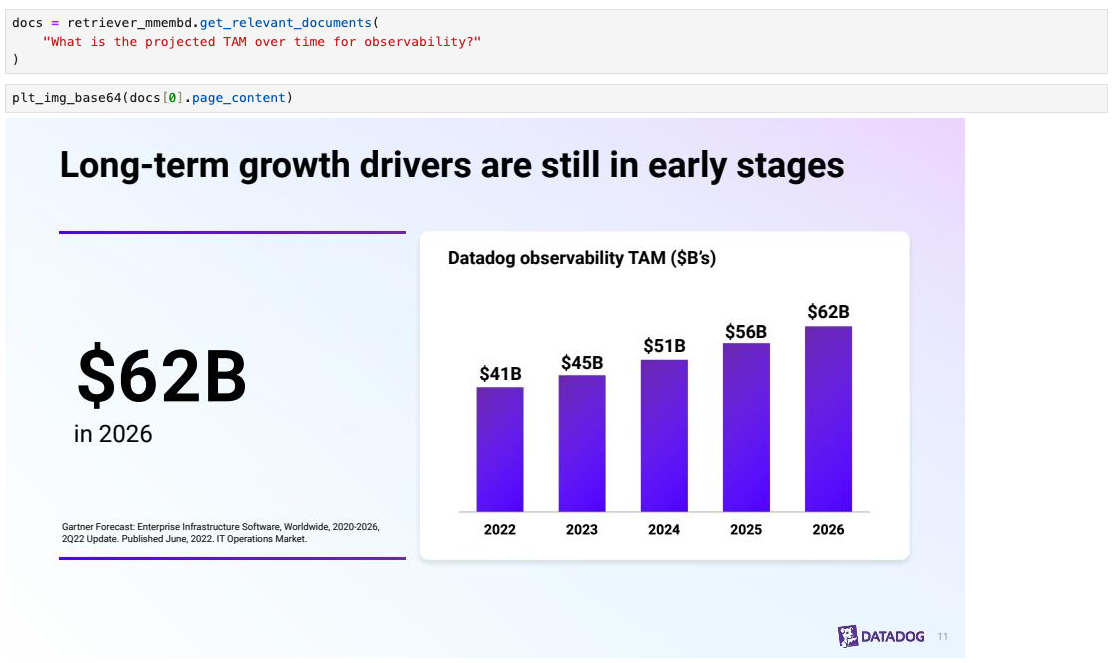
The question-answer pairs in our benchmark are based on the visual content of the slides. We evaluated the above two RAG methods with LangSmith and compare against RAG using text extraction (Top K RAG (text only)).
Approach | Score (CoT accuracy) |
Top k RAG (text only) | 20% |
Multi-modal embeddings | 60% |
Multi-vector retriever w/ image summary | 90% |
LangSmith offers a comparison view where we can review the results of each experiment side-by-side. Here is a public page where the evaluation runs can be compared in detail. The image below shows the run comparison view.
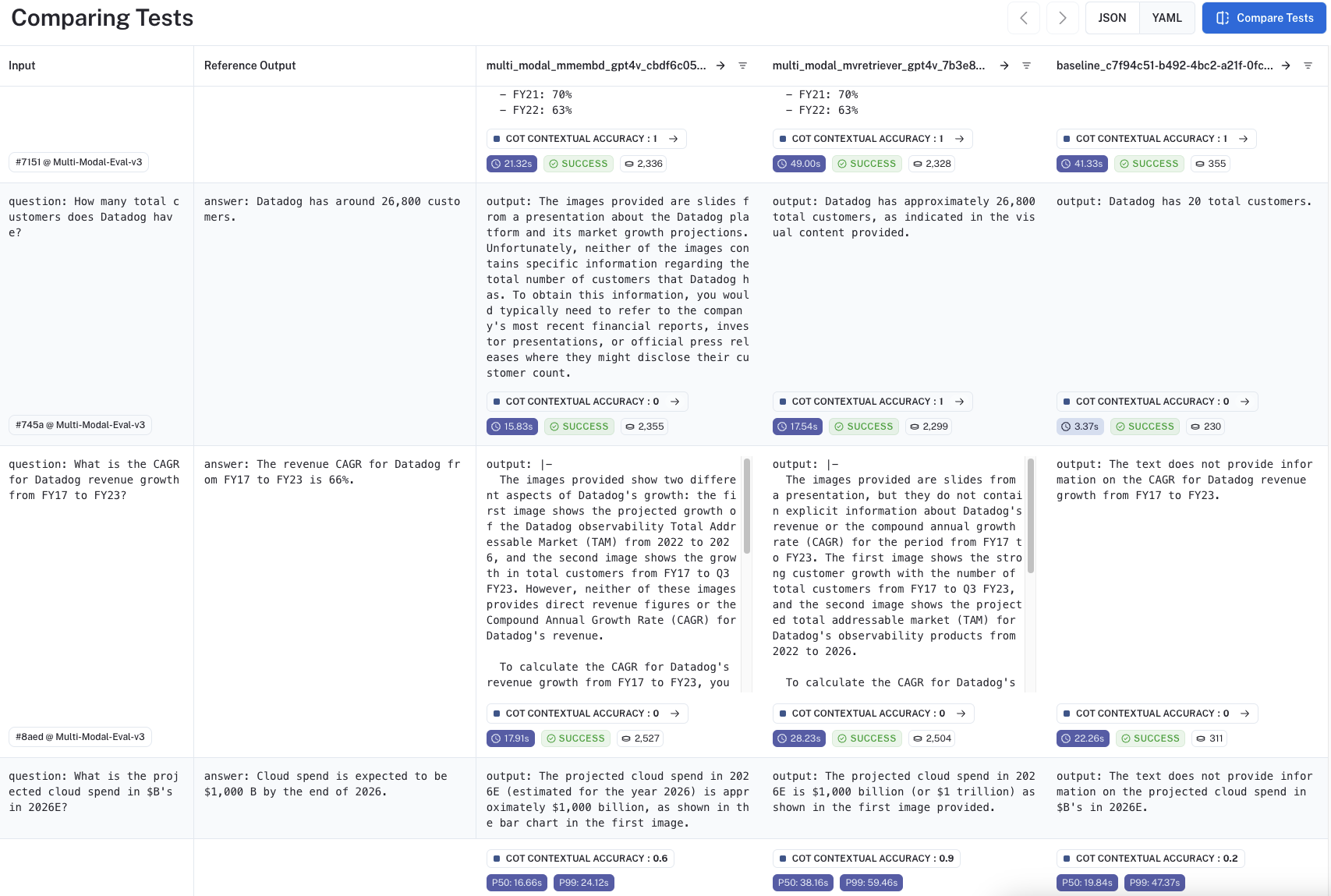
Using the above comparative analysis, we can compare the retrieved content for each question. These slides provide a deep dive of every question - answer pair in the evaluation set along with the associated LangSmith traces.
Insights
- Multi-modal approaches far exceed the performance of text-only RAG. We saw notable improvement with multi-modal approaches (60% and 90%) over the RAG that loads only the text (20%), an expected result given the importance of retaining visual context for reasoning about the slide content.
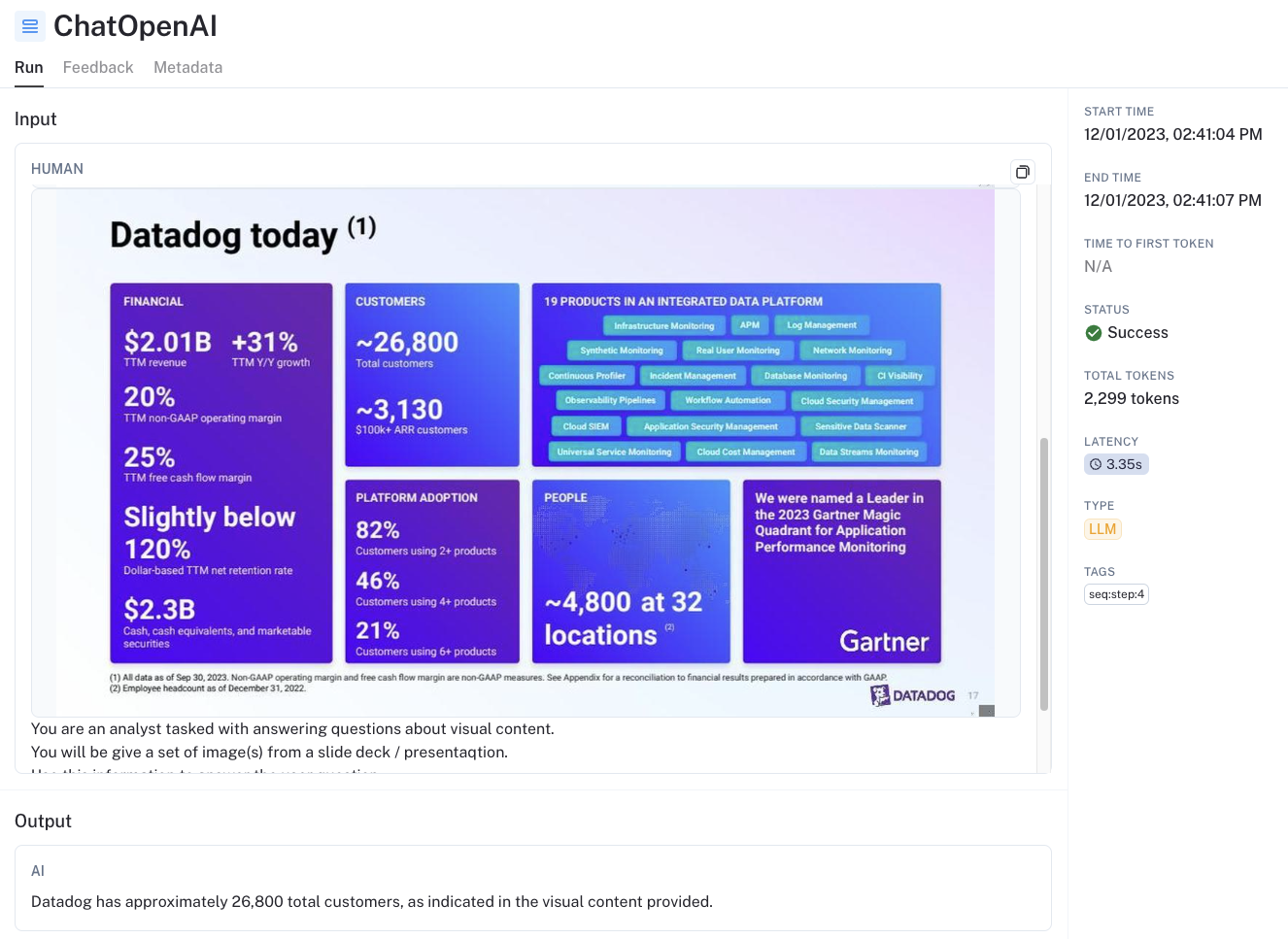
- GPT-4V is powerful for structured data extraction from images. For example, see this trace. The question asks for the count of customers, which can only be retrieved from a slide that contains a broad mix of visual content. GPT-4V is able to correctly extract this information from the slide
- Retrieval of the correct image is the central challenge. As noted in the slides and mentioned above, if the correct image was retrieved then GPT-4V was typically able to answer the question correctly. However, image retrieval was the central challenge. We found that image summarization does improve retrieval significantly over multi-modal embeddings but comes with higher complexity and cost to pre-compute the summaries. The central need is for multi-modal embeddings that can differentiate between visually similar slides. OpenCLIP has a wide variety of different models that are worth experimenting with; they can be easily configured as shown here.
Deployment
To ease testing of multi-modal RAG application for this use-case, we are releasing a template that uses both Chroma and OpenCLIP multi-modal embeddings. This makes it extremely easy to get started: simply upload a presentation and follow the README (just two command to build the vectorstore and run the playground). Below we can see the interactive chat playground (left) on the Datadog earnings presentation with the LangSmith trace (right) showing retrieval of the right slide.
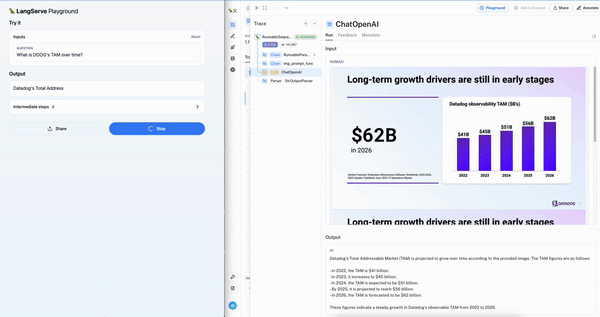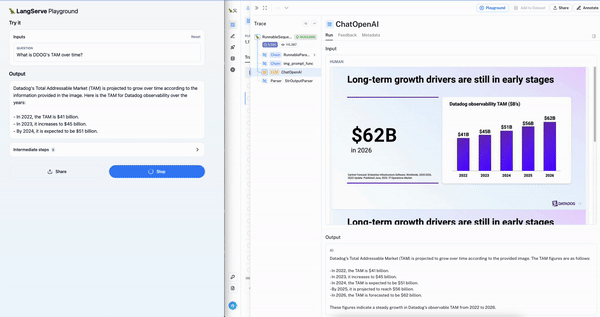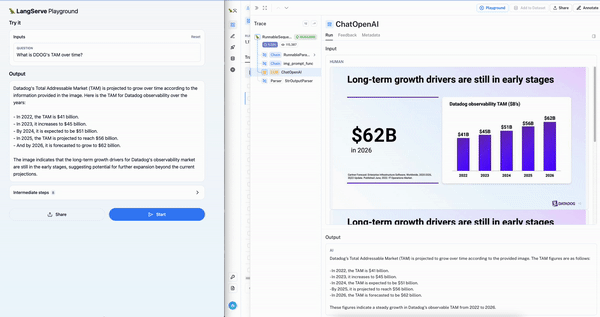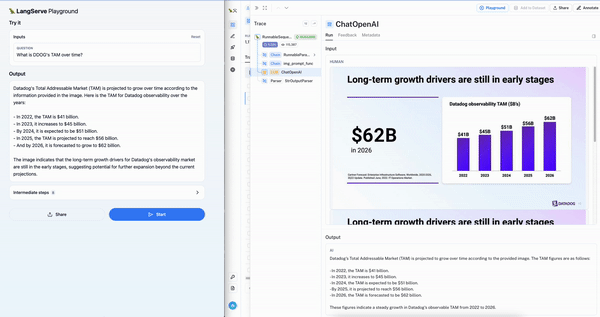
Conclusion
Multi-modal LLMs have potential to unlock the visual content in slide decks for RAG applications. We build a public benchmark evaluation set of question-answer pairs on an investor presentation slide deck for Datadog (here). We tested multi-modal RAG using two approaches on this benchmark. We found that both exceed the performance of text-only RAG. We identified trade-offs between approaches for multi-modal RAG: text summarization of each slide can improve retrieval but comes at the cost of pre-generating summaries of each slide. Multi-model are likely to have a higher performance ceiling, but current options are somewhat limited and, in our test, under-perform text summarization. To aid in the testing and deployment of multi-modal RAG apps, we also are releasing a template.