Key Links
Overview
Interest in long context LLMs is surging as context windows expand to 1M tokens. One of the most popular and cited benchmarks for long context LLM retrieval is Greg Kamradt's Needle in A Haystack: a fact (needle) is injected into a (haystack) of context (e.g., Paul Graham essays) and the LLM is asked a question related to this fact. This explores retrieval across context length and document placement.
But, this isn't fully reflective of many retrieval augmented generation (RAG) applications; RAG is often focused on retrieving multiple facts (from an index) and then reasoning over them. We present a new benchmark that tests exactly this. In our Multi-Needle + Reasoning benchmark we show two new results:
- Performance degrades as you ask LLMs to retrieve more facts
- Performance degrades when the LLM has to reason about retrieved facts
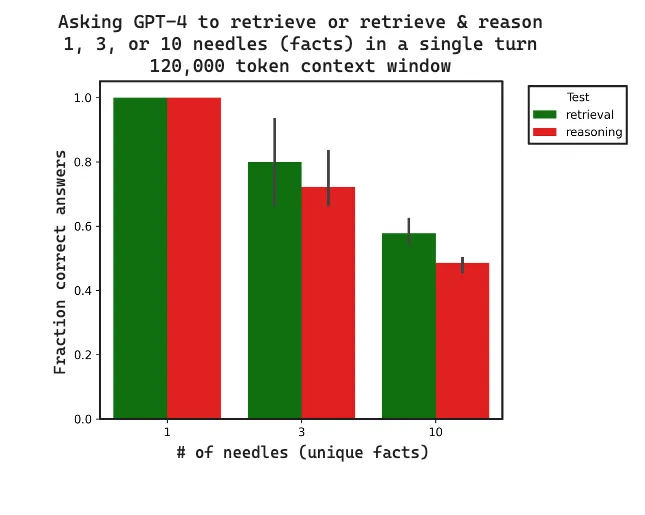
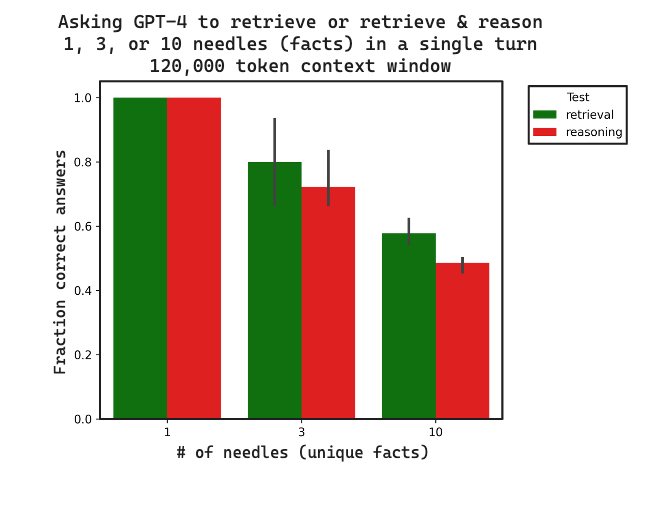
See below plot for a summary of the results: as the number of needles increases, retrieval decreases; and reasoning over those needles is worse than just retrieval.
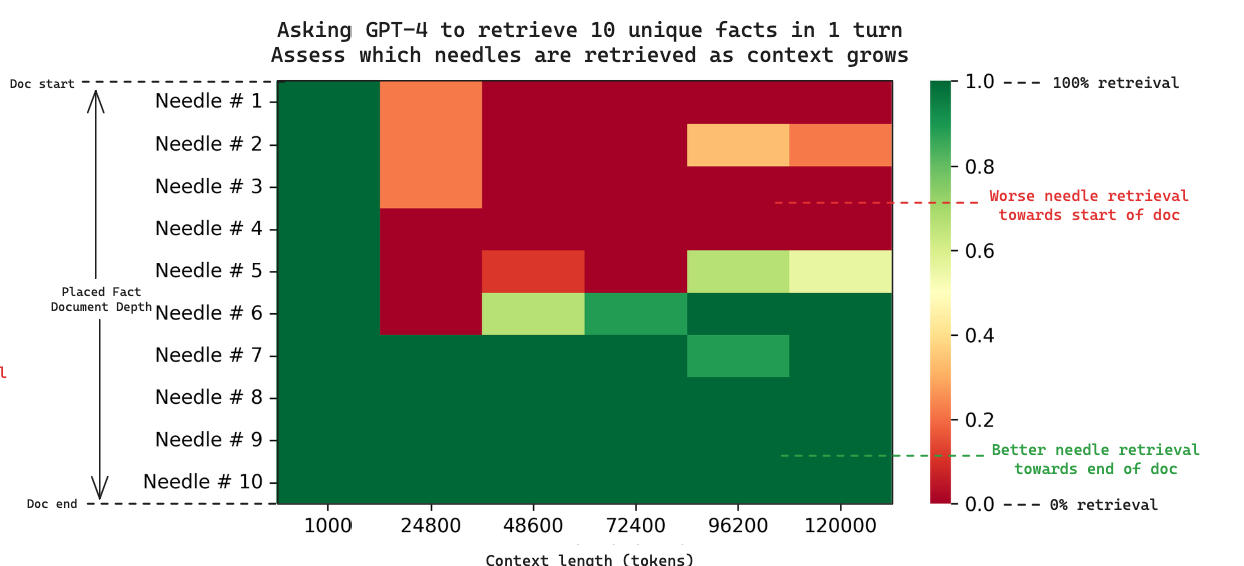
We also show (similar to previous benchmarks) that performance decreases as more and more context is passed in. However, we additionally investigate not just overall performance but why performance drops when retrieving multiple needles. Looking at the heatmap of results below, we can see that when retrieving multiple needles GPT-4 consistently retrieves needles towards the end while ignoring needles at the beginning, similar to the single needle studies.
Below we'll walk through benchmark usage and discuss results on GPT-4.
Usage
To perform a Multi-Needle + Reasoning evaluation, a user only needs three things: (1) A question that requires multiple needles to answer, (2) an answer derived from the needles, and (3) list of needles to be inserted into the context.
We extended Greg Kamradt's LLMTest_NeedleInAHaystack repo to support multi-needle evaluation and LangSmith as an valuator. Using LangSmith for evaluation, we create a LangSmith eval set with items (1) question and (2) answer above.
As an example, lets use this case study where the needle was a combination of pizza ingredients. We create a new LangSmith eval set (here) named multi-needle-eval-pizza-3 with our question and answer:
question:
What are the secret ingredients needed to build the perfect pizza?
answer:
The secret ingredients needed to build the perfect pizza are figs, prosciutto, and goat cheese.Question, Answer pairs for LangSmith multi-needle-eval-pizza-3 eval set
Once we've created a dataset, we with few flags:
document_depth_percent_min- the depth of the first needle. The remaining needles are inserted at roughly equally spaced intervals after the first.multi_needle- flag to run multi-needle evaluationneedles- the full list of needles to inject into the contextevaluator- chooselangsmitheval_set- choose the eval set we createdmulti-needle-eval-pizza-3context_lengths_num_intervals- number of context lengths to testcontext_lengths_min(and max) - context length bounds to test
We can run this to execute the evaluation:
python main.py --evaluator langsmith --context_lengths_num_intervals 6 --document_depth_percent_min 5 --document_depth_percent_intervals 1 --provider openai --model_name "gpt-4-0125-preview" --multi_needle True --eval_set multi-needle-eval-pizza-3 --needles '[ " Figs are one of the secret ingredients needed to build the perfect pizza. ", " Prosciutto is one of the secret ingredients needed to build the perfect pizza. ", " Goat cheese is one of the secret ingredients needed to build the perfect pizza. "]' --context_lengths_min 1000 --context_lengths_max 120000 Command to run multi-needle evaluation using LangSmith
This will kick off a workflow below. It will insert the needles into the haystack, prompt the LLM to generate a response to the question using the context with the inserted needles, and evaluate whether the generation correctly retrieved the needles using the ground truth answer and the logged needles that were inserted.
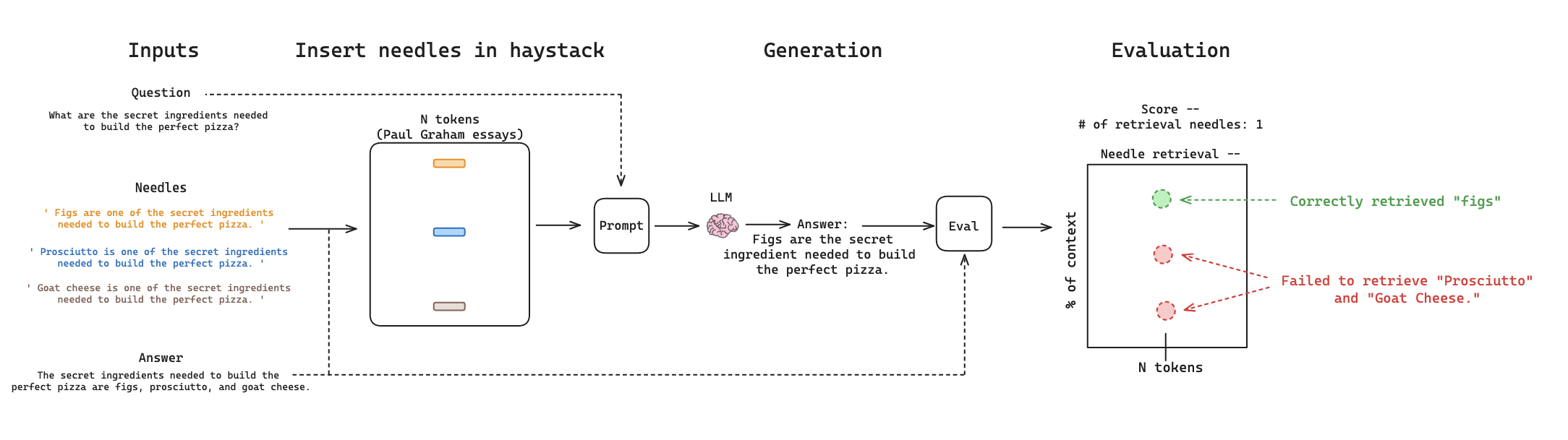
Multi-Needle + Reasoning evaluationGPT-4 Retrieval Results
To test multi-needle retrieval for GPT-4, we built three LangSmith eval sets:
multi-needle-eval-pizza-1here - Insert a single needlemulti-needle-eval-pizza-3here - Insert three needlesmulti-needle-eval-pizza-10here - Insert ten needles
We evaluate the ability of GPT4 (128k token context length) to retrieve 1, 3, or 10 needles in a single turn for small (1000 token) and large (120,000 token) context lengths. All commands run are here. All resulting generations with public links to LangSmith traces are here. Here is a summary figure of our results:
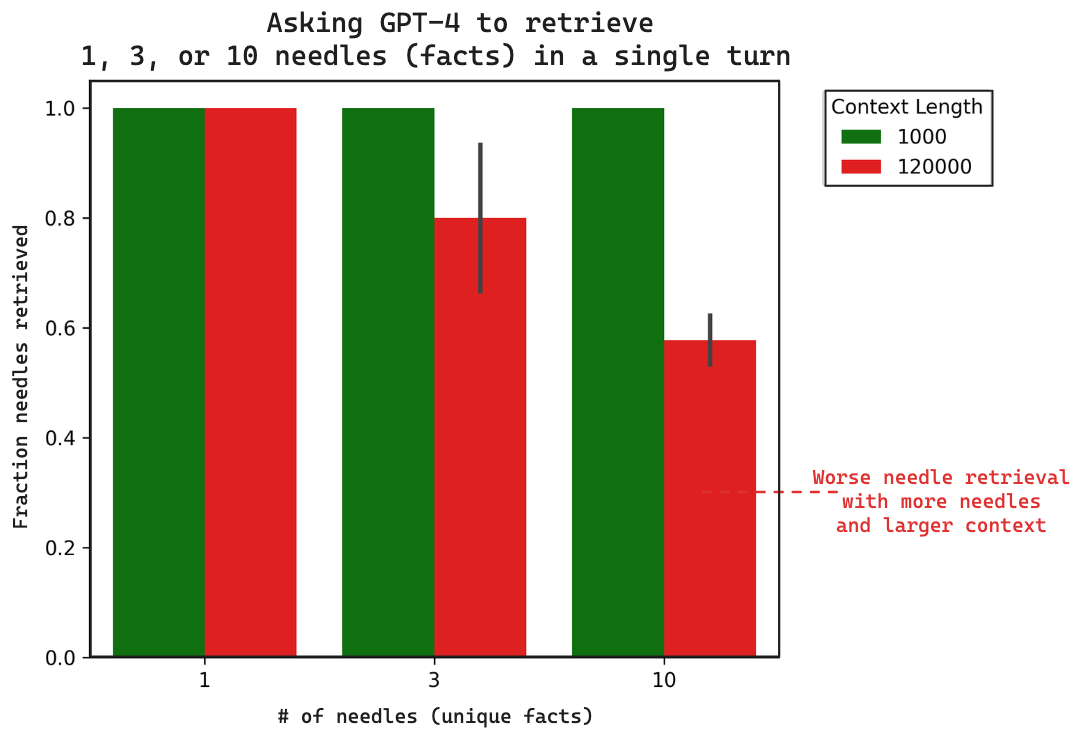
There are clear observations:
- Performance degrades at the number of needles increases from 1 to 10
- Performance degrades as the context increases from 1000 to 120,000 tokens
To explore and validate these results, we can drill into LangSmith traces: here is one LangSmith trace where we inserted 10 needles. Here is the GPT-4 generation:
The secret ingredients needed to build the perfect pizza include espresso-soaked dates, gorgonzola dolce, candied walnuts, and pear slices.GPT-4 generation for replicate 1 for 10 needles, 24,800 token context
Only four of the secret ingredients are in the generation. Based on the trace, we verify that all 10 needles are in the context and we log the inserted needle order:
* Figs
* Prosciutto
* Smoked applewood bacon
* Lemon
* Goat cheese
* Truffle honey
* Pear slices
* Espresso-soaked dates
* Gorgonzola dolce
* Candied walnuts Order of the 10 needles placed in the context
From this we can confirm that the four secret ingredients in the generation are the last four needles placed in our context. This provokes an interesting point about where retrieval fails. Greg's single needle analysis showed GPT-4 retrieval failure when the needle is place towards the start of the document.
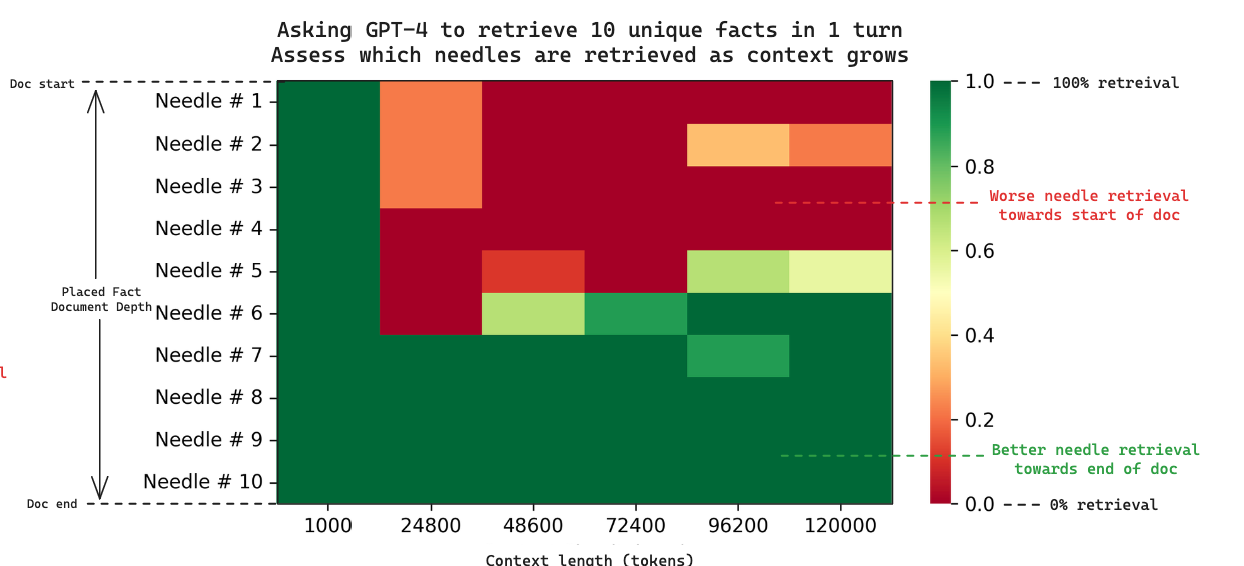
Because we log the placement of each needle, we can explore this too: the below heatmap shows 10 needle retrieval with respect to context length. Each column is a single experiment when we ask GPT-4 to retrieve 10 needles in the context.
As the context length grows, we also see retrieval failure towards the start of the document. The effect appears to start earlier in the multi-needle case (around 25k tokens) than the single needle case (which started around 73k tokens for GPT-4).
GPT-4 Retrieval & Reasoning
RAG is often focused on retrieving multiple facts (from an indexed corpus of documents) and then reasoning over them. To test this, we build 3 datasets that build on the above by asking for the first letter of all secret ingredients. This requires retrieval of ingredients and reasoning about them to answer the question.
multi-needle-eval-pizza-reasoning-1- heremulti-needle-eval-pizza-reasoning-3- heremulti-needle-eval-pizza-reasoning-10- here
Note that this is an extremely simple form of reasoning. For future benchmarks, we want to include different levels of reasoning.
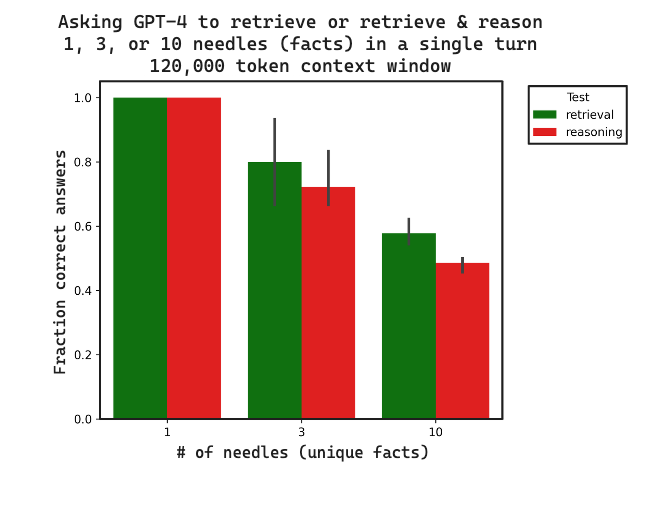
We compared the fraction of correct answers for 3 replicates between retrieval and retrieval + reasoning. All data with traces is here. Retrieval and reasoning both degrade as the context length increases, reasoning lags retrieval. This suggests that retrieval may set an upper bound on reasoning performance, as expected.
Conclusion
The emergence of long context LLMs is extremely promising. In order to use them with or in place of external retrieval systems, it is critical to understand their limitations. The Multi-Needle + Reasoning benchmark can characterize the performance of long context retrieval relative to using a traditional RAG approach.
We can draw a few general insights, but further testing is needed:
No retrieval guarantees- Multiple facts are not guaranteed to be retrieved, especially as the number of needles and context size increases.Different patterns of retrieval failure- GPT-4 fails to retrieve needles towards the start of documents as context length increases.Prompting matters- Following insights mentioned here and here, specific prompt formulations may be needed to improve recall with certain LLMs.-
Retrieval vs reasoning- Performance degrades when the LLM is asked to reason about the retrieved facts.