
Key Links:
A little over two months ago, on the heels of OpenAI dev day, we launched OpenGPTs: a take on what an open-source GPT store may look like. It was powered by an early version of LangGraph - an extension of LangChain aimed at building agents as graphs. At the time, we did not highlight this new package much, as we had not publicly launched it and were still figuring out the interface. We finally got around to launching LangGraph two weeks ago, and over the past weekend we updated OpenGPTs to fully use LangGraph (as well as added some new features). We figure now is as good of time as any to do a technical deep-dive on OpenGPTs and what powers it.
In this blog, we will talk about:
- MessageGraph: A particular type of graph that OpenGPTs runs on
- Cognitive architectures: What the 3 different types of cognitive architectures OpenGPTs supports are, and how they differ
- Persistence: How persistence is baked in OpenGPTs via LangGraph checkpoints.
- Configuration: How we use LangChain primitives to configure all these different bots.
- New models: what new models we support
- New tools: what new tools we support
astream_events: How we are using this new method to stream tokens and intermediate steps
If a YouTube video is more your style, we also did a video walkthrough!
MessageGraph
OpenGPTs runs on MessageGraph, a particular type of Graph we introduced in LangGraph. This graph is special in that each node takes in a list of messages and returns messages to append to the list of messages. We think this “message passing” is interesting for several reasons:
- It is closely related to the I/O of new “chat completion” models, which take in a list of messages and return a message
- Message passing is a common method for communication in distributed systems
- It makes visualization of the work being done easier, as each unit of work is now of a common type
- It is closely related to Assistants API introduced by OpenAI (where messages are appended to threads)
- It conceptually seems extensible to multi-agent systems (where each agent just appends messages to the list of messages)
By using MessageGraph we are making assumptions about the input and output of the agents we create, but notably we are NOT making any assumptions about the cognitive architecture of those agents. As we see below, this can support a wide variety of cognitive architectures.
Cognitive Architectures
As part of this update to OpenGPTs, we’ve added three different cognitive architectures to let users choose from when creating bots.
- Assistants: These can be equipped with arbitrary amount of tools and use an LLM to decide when to use them
- RAG: These are equipped with a single retriever, and they ALWAYS use it.
- ChatBot: These are just parameterized by a custom system message.
Assistants
Assistants can be equipped with arbitrary amount of tools and use an LLM to decide when to use them. This makes them the most flexible choice, but they work well with fewer models and can be less reliable.
When creating an assistant, you specify a few things.
First, you choose the language model to use. Only a few language models can be used reliably well: GPT-3.5, GPT-4, Claude, and Gemini.
Second, you choose the tools to use. These can be predefined tools OR a retriever constructed from uploaded files. You can choose however many you want.
The cognitive architecture can then be thought of as a loop. First, the LLM is called to determine what (if any) actions to take. If it decides to take actions, then those actions are executed and it loops back. If no actions are decided to take, then the response of the LLM is the final response, and it finishes the loop.
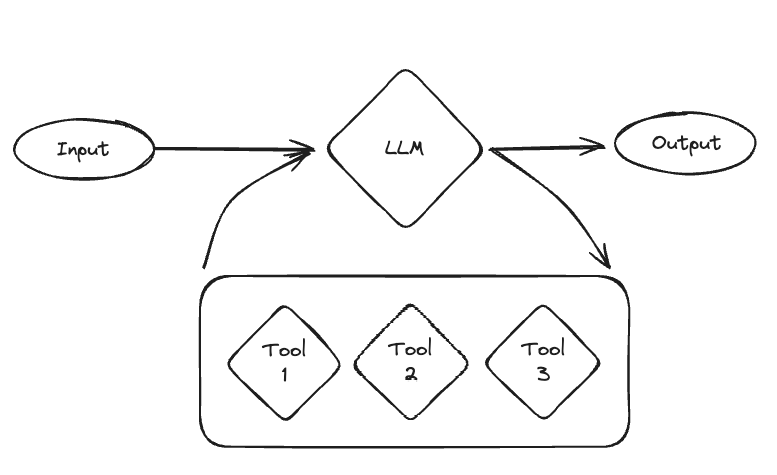
This can be a really powerful and flexible architecture. This is probably closest to how us humans operate. However, these also can be not super reliable, and generally only work with the more performant models (and even then they can mess up). Therefore, we introduced a few simpler architectures.
RAG
One of the big use cases of the GPT store is uploading files and giving the bot knowledge of those files. What would it mean to make an architecture more focused on that use case?
We added a RAG bot - a retrieval-focused GPT with a straightforward architecture. First, a set of documents are retrieved. Then, those documents are passed in the system message to a separate call to the language model so it can respond.
Compared to assistants, it is more structured (but less powerful). It ALWAYS looks up something - which is good if you know you want to look things up, but potentially wasteful if the user is just trying to have a normal conversation. Also importantly, this only looks up things once - so if it doesn’t find the right results then it will yield a bad result (compared to an assistant, which could decide to look things up again).
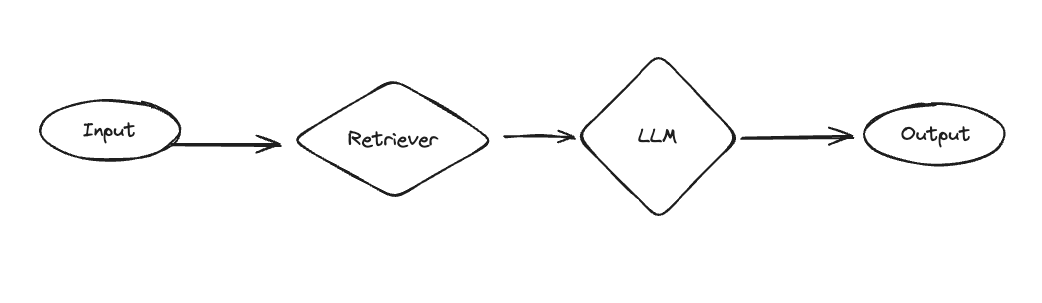
Despite this being a more simple architecture, it is good for a few reasons. First, because it is simpler it can work pretty well with a wider variety of models (including lots of open source models). Second, if you have a use case where you don’t NEED the flexibility of an assistant (eg you know users will be looking up information every time) then it can be more focused. And third, compared to the final architecture below it can use external knowledge.
ChatBot
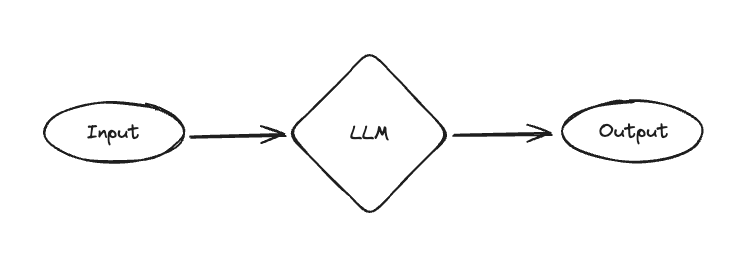
The final architecture is dead simple - just a call to a language model, parameterized by a system message. This allows the GPT to take on different personas and characters. This is clearly far less powerful than Assistants or RAGBots (which have access to external sources of data/computation) - but it’s still valuable! A lot of popular GPTs are just system messages at the end of the day, and CharacterAI is crushing it despite largely just being system messages as well.
Persistence
A requirement for OpenGPTs from the beginning was persistence, specifically persistence of chat messages. Rather than build a bespoke solution for this, we decided to add functionality for this as part of LangGraph. Specifically, when creating a graph you can pass a CheckPoint object. This checkpoint object will then save the current state of the graph after calling each node.
For OpenGPTs, we created a RedisCheckPointer, which saves the results to Redis. Right now, this persistence is just being used to surface messages of past conversations, but we will use this persistence in more advanced ways shortly 🙂
Configuration
Another requirement for OpenGPTs was configuration. We need users to be able to choose what LLM, what system message, what tools, etc. We also need to save that configuration so they could use that chatbot again in the future.
One of the under-highlighted features of LangChain is the ability to mark certain fields as configurable. You can do this for any field of a chain, and then pass in configuration options during run time.
This allowed us to easily accomplish configurability in a modular and consistent way. First, we marked different fields as configurable, and then to support different architectures we even gave the whole chain configurable alternatives. Then, when a user created a GPT we would save the configuration. Finally, when chatting with that GPT, we would invoke the chain with the saved configuration.
Check out the OpenGPT source code for some advanced examples of how to do this, but remember that it’s doable with all LangChain objects!
New Models
We wanted to introduce a few new models as part of this update. First, we integrated Google’s Gemini model. This model is pretty performant and supports function calling, so we added it as an option for the assistants.
We tried hard to get an open-source model to be reliable enough to be used an assistant, but failed. Even with Mixtral it was still a little unreliable. We would love community assistance in getting one to work reliably!
In the absence of getting it to work for the Assistant architecture, we added Mixtral (via Fireworks) as an option for the ChatBot and the RAGBot. It works very well with these simpler architectures!
We also updated the OpenAI agents to use tool calling instead of function calling.
New Tools
We also introduced a new tool - Robocorp’s Action Server. Robocorp’s action server is an easy way to define - and run - arbitrary Python functions as tools. Therefore, even though this is a single tool, it’s possible to use to this define many different tools!
Be on the lookout for a deeper dive into this later on in the week
astream_events
It’s worth calling out that we’re using our new astream_eventsmethod to easily stream back all events (new tokens, as well as function calls and function results) and surface them to the user. We do some filtering of this stream to get relevant messages or message chunks, and then render them nicely in the UI. If you aren’t familiar with astream_events, it is definitely worth checking it out in more detail here.
Conclusion
We hope this provides a more proper technical deep dive in OpenGPTs. There are several areas that could benefit from community assistance:
- Prompting strategies to get the Assistant architecture to work reliably with open source models
- Support for other tools (including arbitrary OpenAPI specs)
Everything behind OpenGPTs is also exposed via API endpoints, so feel free to fork it and use only the backend.
If you are an enterprise looking to deploy OpenGPTs internally, please reach out to gtm@langchain.dev.