Important Links:
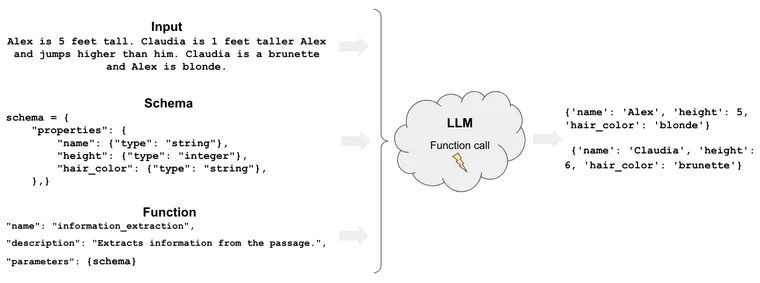
One of the biggest use cases for language models that we see is in extraction. This is where the language model is used to extract multiple pieces of structured information from unstructured documents. The biggest challenge developers faced here was in getting the language model to correctly output valid JSON.
OpenAI helped immensely with that when they introduced function calling in early 2023. At a high level, function calling encourages the model to respond in a structured format. This was mainly highlighted as a way for the language model to invoke functions correctly (when calling functions you need a response in the right format). However, there are many other places where having a properly structured response is useful - such as extraction. We recently did a DeepLearningAI class with Andrew Ng where we covered this in detail.
At OpenAI's developer day on 11/6 they released an updated way to invoke functions that allows for parallel function calling. This new ability allows for a language model to call multiple functions at the same time. For more context you can check out their release blog here.
Parallel function calling makes extraction significantly easier. In the rest of this blog post we'll dive into what extraction is, what looked like before with the old way of function calling, and what it looks like now with parallel function calling, why it is significantly easier and more powerful (although it does come with one downside).
What is Extraction
Extraction is the process of extracting structured data from unstructured data. A concrete example of this is entity extraction. As Sematext explains:
Entity extraction is, in the context of search, the process of figuring out which fields a query should target, as opposed to always hitting all fields. The reason we may want to involve entity extraction in search is to improve precision. For example: how do we tell that, when the user typed in Apple iPhone, the intent was to run company:Apple AND product:iPhone? And not bring back phone stickers in the shape of an apple?
Crucially, this involves extracting multiple pieces of information, potentially of different types.
Old Function Calling
With old function calling you could only get one function call back at a time. This made it so that if you wanted to extract multiple pieces of information at a time you had to do some hacks. For example, let's assume you wanted to extract the following pieces of information:
class Person(BaseModel):
name: str
age: int(Notice that I am representing this as a Pydantic class - this is just a convenience method for constructing the JSON that is eventually passed into the function call parameter)
If I just passed that directly as a function to the old OpenAI models, it would only ever return one piece of information! This is obviously not acceptable if I want to extract multiple pieces of information.
In order to extract multiple pieces of information, I would have to do a hack like:
class Information(BaseModel):
people: List[Person]This would construct a new object that had as a field a list of Person objects. This way, when the OpenAI model constructed the function invocation, it would construct one argument that was a list of people.
This made it possible to allow for extraction of multiple elements of the same type, but it comes at a downside as well. If we wanted to extract both Person and a different type of object (say Location) we would have to do some more and more complicated typing logic. For example, that would look like:
class Information(BaseModel):
info: List[Union[Person, Location]]This would also necessitate some more complicated parsing logic of the language model's responses.
Parallel Function Calling
So how does parallel function calling improve this?
It removes a LOT of the complexity and hacks we had to do. You no longer have to create that ugly, extraneous Information class - you can just pass in Person and Location directly as functions, and the model will output those as separate function calls. This is an improvement because it means:
- Less logic needed to create the LLM input (better developer experience)
- Less complicated function definitions to pass to the LLM (saves on tokens, less likely to confuse the LLM)
- Less complicated output the LLM needs to produce (smaller chance the LLM messes up and outputs incorrect json)
- Less logic needed to parse the LLM output (better developer experience)
We've put all this together into a simple extraction chain - you can check it out here. The full logic for the chain looks something like:
# Create a prompt telling the LLM to extract information
prompt = ChatPromptTemplate.from_messages({
("system", _EXTRACTION_TEMPLATE),
("user", "{input}")
})
# Convert Pydantic objects to the appropriate schema
tools = [convert_pydantic_to_openai_tool(p) for p in pydantic_schemas]
# Give the model access to these tools
model = llm.bind(tools=tools)
# Create an end to end chain
chain = prompt | model | PydanticToolsParser(tools=pydantic_schemas)Using this chain we can now do things like:
# Make sure to use a recent model that supports tools
model = ChatOpenAI(model="gpt-3.5-turbo-1106")
chain = create_extraction_chain_pydantic(Person, model)
chain.invoke({"input": "jane is 2 and bob is 3"})And get:
[Person(name='jane', age=2), Person(name='bob', age=3)]Conclusion
While most people are excited about function calling for creating agents, there is a very real (and very useful) use case around using it to structure outputs from LLMs more generically. One of these use cases is extraction, but with old function calling you had to do some hacks to get that to work. With parallel function calling it is significantly easier. Try it out!