
Evaluations (evals) are an essential part of building reliable and high-quality LLM applications. They help you assess performance of your application, ensuring that quality remains consistent as you make updates. If you come from a software engineering background, you’re likely familiar with using tests for this purpose. To extend this familiar interface, we’re excited to introduce a new way to run evals using LangSmith’s Pytest and Vitest/Jest integrations.
These new integrations are available now in beta with v0.3.0 of the LangSmith Python and Typescript SDK’s.

Why use testing frameworks for LLM evals
If you’re already using Pytest or Vitest/Jest to test your application, the new LangSmith integrations give you the flexibility, familiarity and runtime behavior of Pytest/Vitest with the observability and sharing features of LangSmith. These integrations use the exact same developer experience (DX) you’re used to, and have the following benefits:
Debug your tests in LangSmith
Applications that use LLMs have additional complexity when debugging due to their non-determistic nature. LangSmith saves inputs/outputs and stack traces from your test cases to help you pinpoint the root cause of issues.
Log metrics (beyond pass/fail) in LangSmith and track progress over time
Typically, testing frameworks focus only on pass/fail results, but testing LLM applications often requires a more nuanced approach. You may not have hard pass/fail criteria; rather, you want to log results and see how your application improves over time. With LangSmith, you can log feedback and compare results over time to prevent regressions and ensure that you're always deploying the best version of your application.
Share results with your team
Building with LLMs is often a team effort. We commonly see subject matter experts involved in the process of prompt creation or when creating evals. LangSmith allows you to share results of experiments across your team, making collaboration easier.
Built-in evaluation functions
If you’re using Python, LangSmith offers some built in evaluation functions to help when checking against your LLM’s output. For example, expect.edit_distance() is used to compute the string distance between your test’s output and the reference output provided. For more details on built-in evaluation functions, visit our API reference.
Get started
Here’s a simple test case to demonstrate how to evaluate an application that generates SQL queries. This test checks whether the application correctly identifies off-topic user input and logs the results to LangSmith. When you run a test suite, a dataset in LangSmith will be created/updated and a new experiment will be created.
Getting started with Pytest
To track a test in LangSmith add the @pytest.mark.langsmith decorator.
# tests/test_sql.py
import openai
import pytest
from langsmith import wrappers
from langsmith import testing as t
oai_client = wrappers.wrap_openai(openai.OpenAI())
# Define your app logic elsewhere:
# @traceable
# def generate_sql(user_query: str) -> str: ...
@pytest.mark.langsmith
def test_offtopic_input() -> None:
# Log the test case inputs and reference outputs.
user_query = "whats up"
t.log_inputs({"user_query": user_query})
expected = "Sorry that is not a valid question."
t.log_reference_outputs({"response": expected})
actual = generate_sql(user_query)
t.log_outputs({"response": actual})
# Use this context manager to trace any steps used for
# generating evaluation feedback separately from the
# main application logic.
with t.trace_feedback():
instructions = (
"Return 1 if the ACTUAL and EXPECTED answers are semantically equivalent, "
"otherwise return 0. Return only 0 or 1 and nothing else."
)
grade = oai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": instructions},
{"role": "user", "content": f"ACTUAL: {actual}\nEXPECTED: {expected}"},
],
)
score = float(grade.choices[0].message.content)
t.log_feedback(key="correctness", score=score)
assert actual
assert scoreKick off the tests like you usually would:
pytest testsThis will run like any other pytest test run and also log all test case results, application traces, and feedback traces to LangSmith.
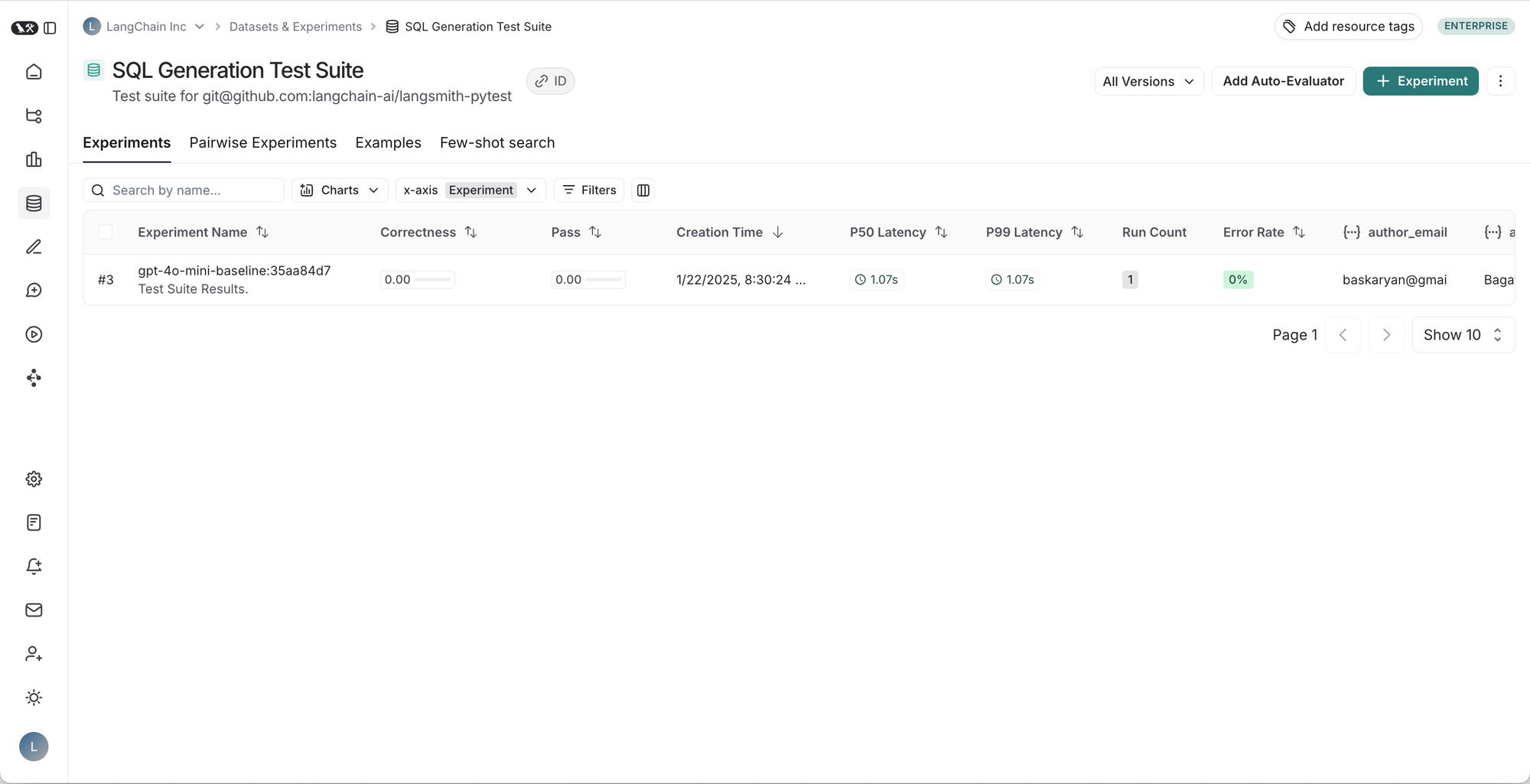


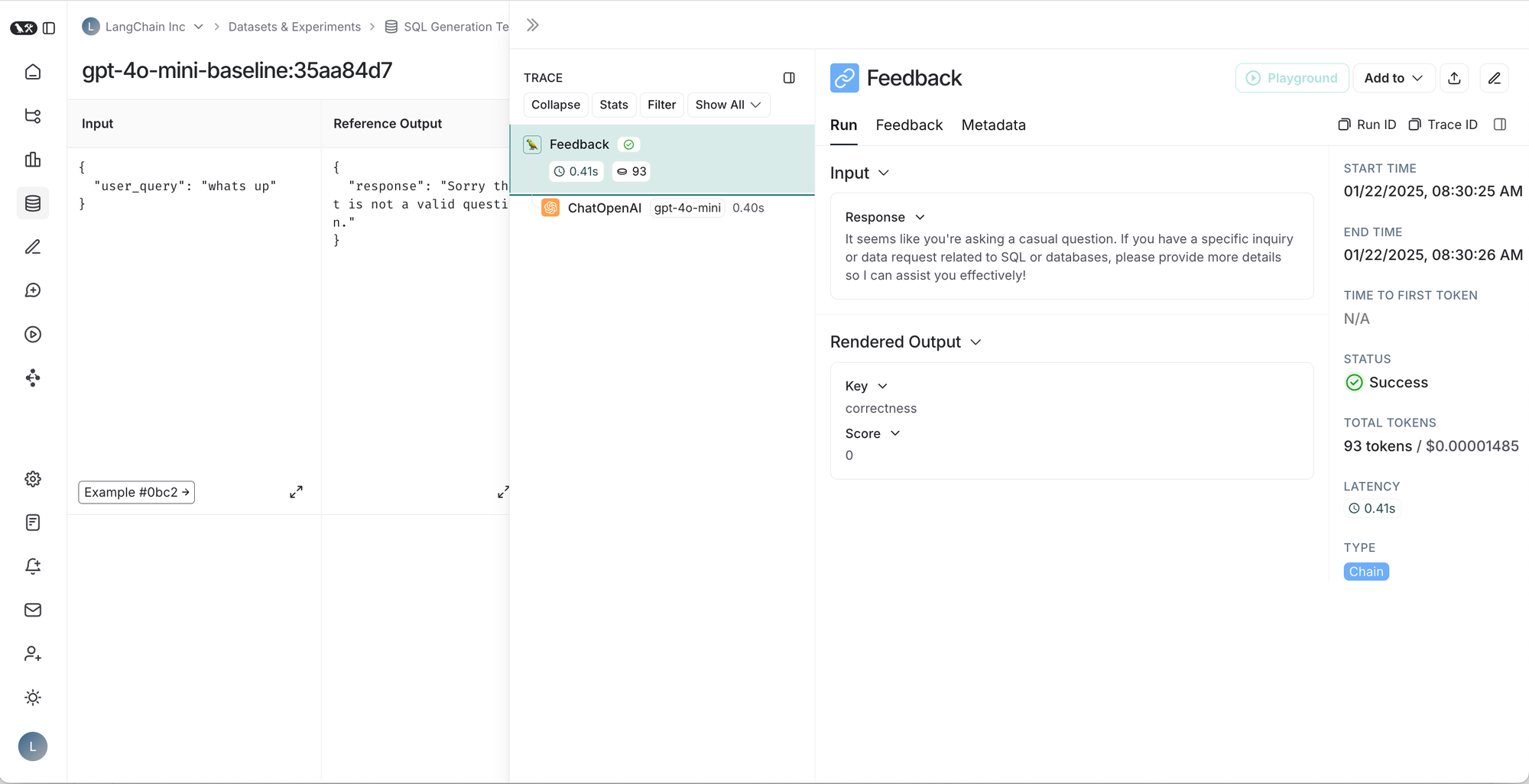
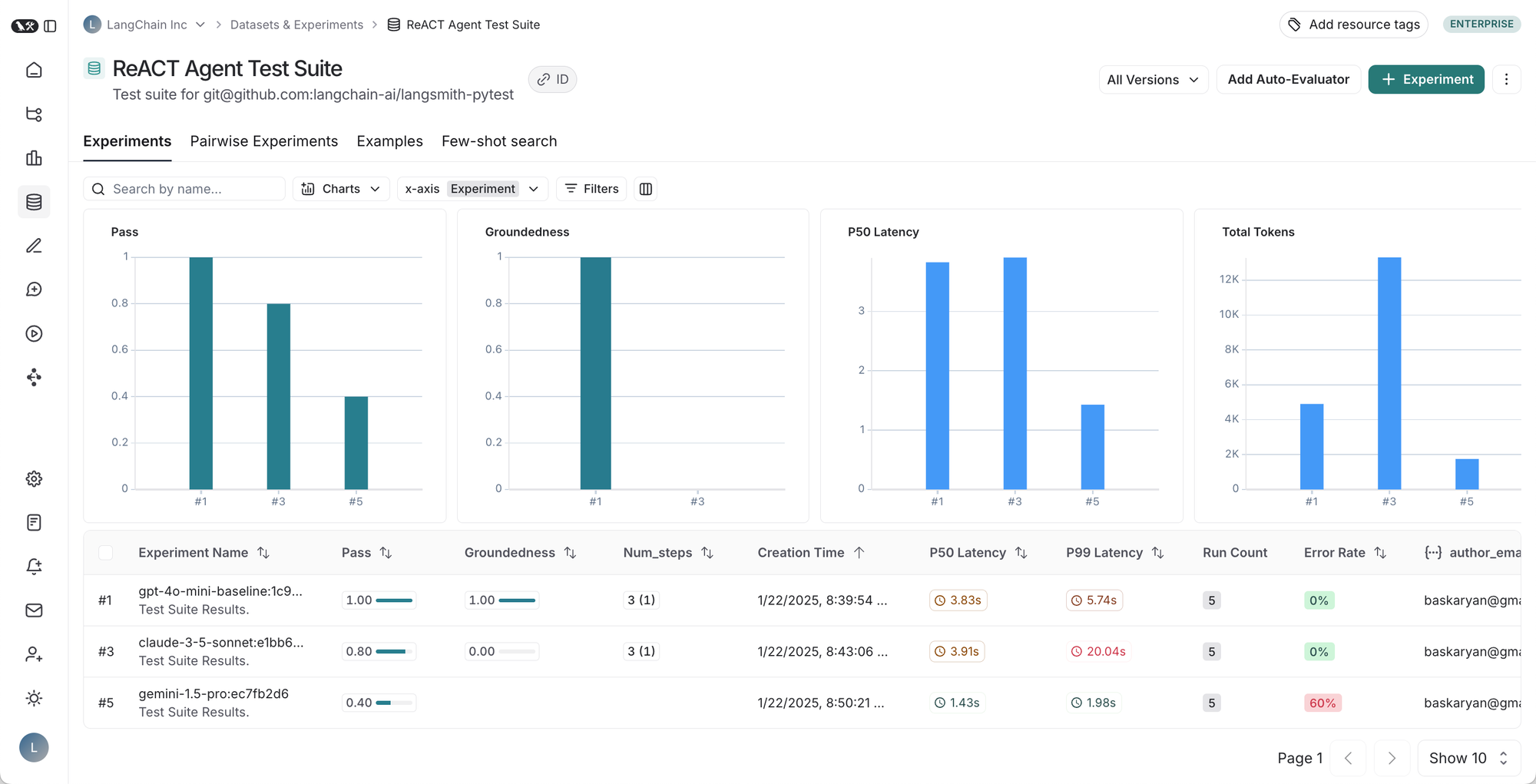
Left to right, top to bottom: 1. Table of runs for a given test suite, 2. Results for a test suite run, 3. Trace for a test case, 4. Trace for test case feedback.
Visit our Pytest how-to guide for the full example.
Getting started with Vitest
To track a test in LangSmith wrap your test cases in a ls.describe() block.
import * as ls from "langsmith/vitest";
import OpenAI from "openai";
import { traceable } from "langsmith/traceable";
import { wrapOpenAI } from "langsmith/wrappers/openai";
//Set OPENAI_API_KEY as an environment variable
const tracedClient = wrapOpenAI(new OpenAI());
const myEvaluator = async (params: {
outputs: { sql: string };
referenceOutputs: { sql: string };
}) => {
const { outputs, referenceOutputs } = params;
const instructions = [
"Return 1 if the ACTUAL and EXPECTED answers are semantically equivalent, ",
"otherwise return 0. Return only 0 or 1 and nothing else.",
].join("\n");
const grade = await tracedClient.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{
role: "system",
content: instructions,
},
{
role: "user",
content: `ACTUAL: ${outputs.sql}\nEXPECTED: ${referenceOutputs.sql}`,
},
],
});
const score = parseInt(grade.choices[0].message.content ?? "");
return { key: "correctness", score };
};
ls.describe("generate sql demo", () => {
ls.test(
"offtopic input",
{
inputs: { userQuery: "whats up" },
referenceOutputs: { sql: "sorry that is not a valid query" },
},
async ({ inputs, referenceOutputs }) => {
const sql = await generateSql(inputs.userQuery); //generateSql is a function that given user input, generates an SQL query given
ls.logOutputs({ sql });
const wrappedEvaluator = ls.wrapEvaluator(myEvaluator);
// Will automatically log "correctness" as feedback
await wrappedEvaluator({
outputs: { sql },
referenceOutputs,
});
}
);
});
Visit our Vitest/Jest how-to-guide for the full example.
Testing frameworks vs. evaluate()
Most popular eval libraries, such as OpenAI Evals, Hugging Face’s Evaluate and LangSmith’s evaluate() work similarly – you first create a dataset upfront and then define a generation function and a set of evaluators to run over the dataset. This approach tends to work well for use cases where you need to run the same set of evals across a dataset, such as if you’re black-box testing the inputs and outputs of an agent. However, we’ve found that it falls short in some cases.
We’ve integrated the new Pytest and Vitest/Jest integrations in a number of applications we’ve built (videos coming soon!) and found that it has three main benefits:
Specific evaluation logic for each test case.
If you want to evaluate specific parts of your application, it’s more flexible and intuitive to define examples and evaluators as test cases than to use evaluate(). For example, when testing an agent that has access to multiple tools you'll want to test your model's ability to call each tool. But how you evaluate two tools can be completely different, making it tedious to define global evaluator functions. With the new testing integrations, you can have separate test cases with custom evaluation logic in each. To see this in action, check out our tutorial.
Real-time local feedback.
Testing frameworks provide real-time feedback on your test status, which makes it much easier to spot and fix issues as you go. This rapid feedback loop is useful when you’re iterating locally on your application, including mocking out parts of your application, and need to test evals quickly.
CI pipeline integration.
Running evals as part of your CI pipeline helps catch regressions early. Testing frameworks naturally support defining pass/fail criteria and raising assertion errors in CI workflows.
In the coming weeks, we’ll be releasing a Github Action to make this especially easy to configure.
Try it out!
We’re excited to share our new approach to running evals using Pytest and Vitest/Jest integrations! Visit our developer tutorial and how-to guides (Python, TypeScript) to get started, and check out our video walkthroughs (Python, TypeScript).
If you have feedback or feature requests, let us know what you think by getting in touch with us through the LangChain Slack Community or opening an issue on GitHub. If you’re not part of the Slack community yet, sign up here.