
Editor's Note: This post was written by the Qdrant team and cross-posted from their blog. As more LLM applications move into production, speed, stability and costs are going to become even more important features of the LLM tech stack. And, as more LLM applications take advantage of RAG (and longterm memory), this becomes even more of a challenge. We're really excited about what Qdrant is doing to help with that–their async support is particularly helpful!
LangChain currently supports 40+ vector stores, each offering their own features and capabilities. When it comes to crafting a prototype, some truly stellar options are at your disposal. However, while some may outshine others in terms of performance and suitability, selecting the best option for your application’s production scenario requires careful consideration.
If you are looking to scale up and keep the same level of performance, Qdrant and LangChain are a rock-solid combination. Getting started with both is a breeze and the documentation covers a broad number of cases. However, the main strength of Qdrant is that it can consistently support the user way past the prototyping and launch phases. For example, you only need a maximum of 18GB RAM, and a minimum of 2GB to support 1 million OpenAI Vectors! This makes Qdrant the best vector store for maximizing resource usage and data connection.
At its core, Qdrant vector database excels at semantic search. When supported by LangChain, Qdrant can help you set up effective QA systems, detection systems and chatbots that leverage Retrieval Augmented Generation (RAG) to its full potential. Qdrant streamlines the process of retrieval augmentation, making it faster, easier to scale and efficient. Adding relevant context to LLMs can vastly improve user experience especially in most business cases, where LLMs haven’t accessed such data before. Vector search is better at sorting through relevant context, when the available data is vast, at times in hundreds or thousands of documents.
How Does Qdrant Work With LangChain?
Qdrant vector database functions as long-term memory for AI models. As a vector store, it manages the efficient storage and retrieval of vectors, which represent user data.
In terms of RAG, LangChain receives a query, dispatches it to a vector database such as Qdrant, retrieves relevant documents, and then sends both the query and the retrieved documents into the large language model to generate an answer.
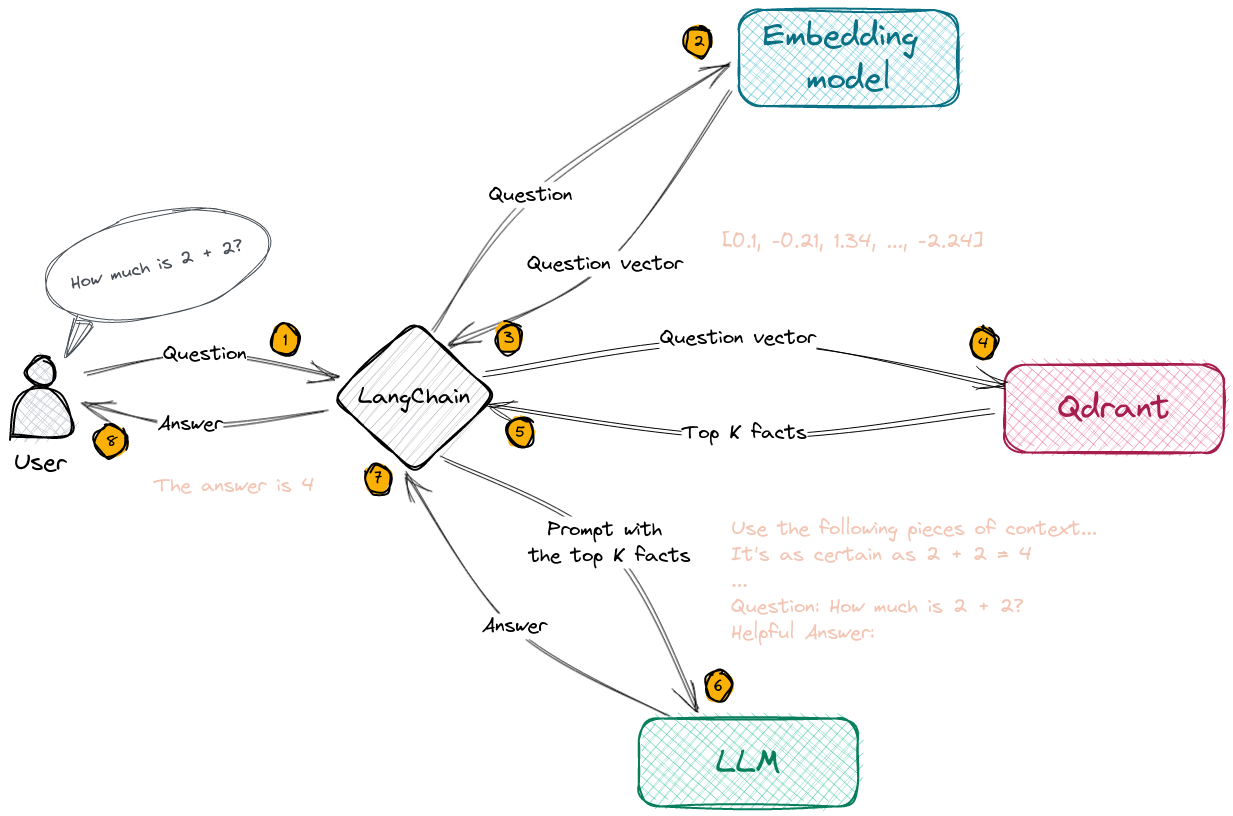
Augmenting your AI application with retrieval systems reduces hallucinations, a situation where AI models produce legitimate-sounding but made-up responses.
When it comes to long-term memory storage for LLM applications, developers can easily add relevant documents, chat history memory & rich user data to LLM app prompts. Qdrant takes care of document and chat history storage, embedding, enrichment, and more.
Optimizing Resource Use
Retrieval Augmented Generation is not without its challenges and limitations. One of the main setbacks for app developers is managing the complexity of the model. The integration of a retriever and a generator into a single model can lead to a raised level of complexity, thus increasing the computational resources required.
Qdrant’s is completely optimized for performance and continually adds new features that reduce the computational load required to run your application. In particular, Qdrant is the only vector store offered by LangChain that supports asynchronous operations. Qdrant supports full async API based on GRPC protocol.
This functionality is available with our open source Qdrant vector database as well as the Qdrant Cloud SaaS product. This causes performance benefits as applications maximize compute use and don't waste time waiting for responses from external services.
Vector stores run as separate services, which makes them I/O bound from the perspective of an LLM-based application. Using `async` lets you utilize the resources better, primarily if the LangChain is combined with an `async` framework, such as FastAPI. Using async API is easy - all the methods have their counterpart async definitions (similarity_search -> asimilarity_search, etc.). FastAPI describes asynchronous operations quite well in their documentation.
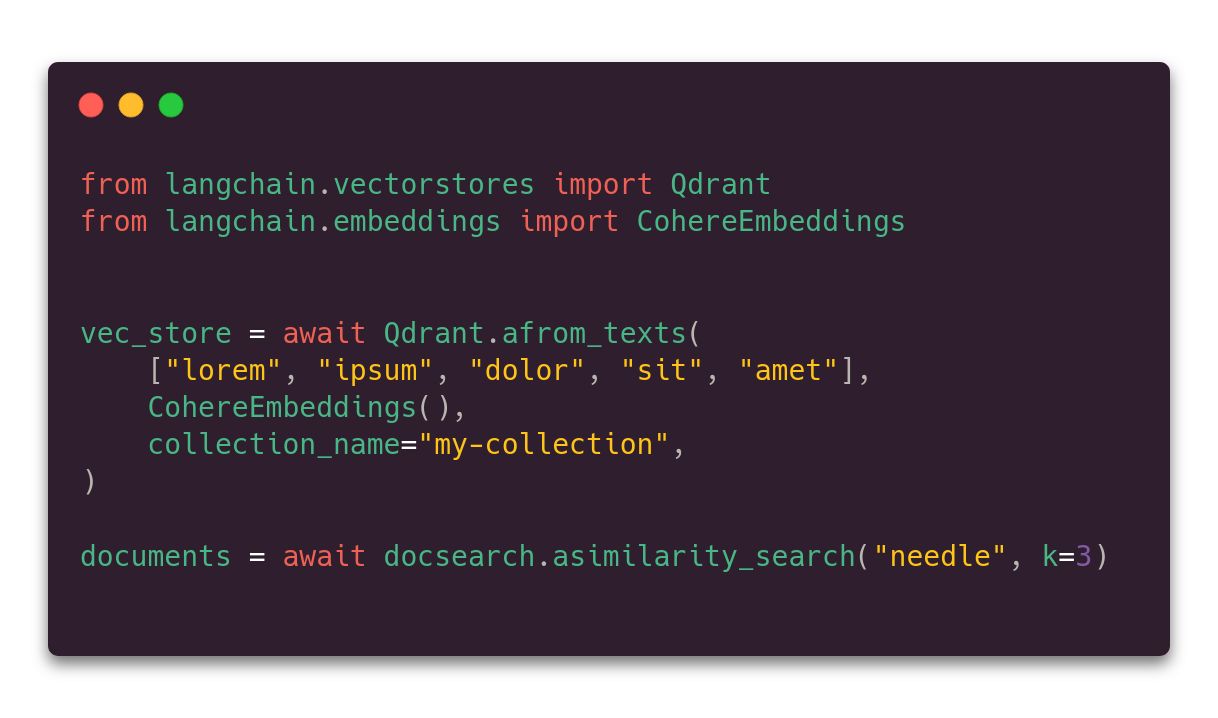
The application doesn't wait for I/O operations and that pays off when applications interact with external systems, such as any database. In this way, compute power does not sit idle and is used to its fullest potential.
The implementation of io_uring is a testament to Qdrant’s focus on performance and resource usage. One of the great optimizations Qdrant offers is quantization (either scalar or product-based). Uring complements these by mitigating the use of disk IO, via improved async throughput wherever the OS syscall overhead gets too high, which tends to occur in situations where software becomes IO bound.
What is Your Endgame?
The wise adage of "trying before buying" holds true in the realm of vector store selection. With numerous options available on LangChain, it's imperative to try whether this option fits your use case the best.
The best way to get started is to sign up for our Qdrant Cloud Free Tier. Join the official Discord community for tech support and integration advice.
“We are all-in on performance and reliability. Every release we make Qdrant faster, more stable and cost-effective for the user. When others focus on prototyping, we are already ready for production. Very soon, our users will build successful products and go to market. At this point, I anticipate a great need for a reliable vector store. Qdrant is there for LangChain and the entire community.” ––David Myriel, Director of Product Education, Qdrant
Relevant Links:
- Qdrant is open source and you can quickstart in local mode, install it via Docker, or to Kubernetes. SDKs are available for Python, TypeScript, Rust and GoLang.
- A free-tier of Qdrant Cloud is also recommended for prototyping and testing.
- For more info, check out the official Qdrant documentation.
- For best integration with LangChain, check the official LangChain documentation as well as LangChain’s API specification for the Qdrant vector store.