
Key Links
Reflection is a prompting strategy used to improve the quality and success rate of agents and similar AI systems. It involves prompting an LLM to reflect on and critique its past actions, sometimes incorporating additional external information such as tool observations.
People like to talk about "System 1" and "System 2" thinking, where System 1 is reactive or instinctive and System 2 is more methodical and reflective. When applied correctly, reflection can help LLM systems break out of purely System 1 "thinking" patterns and closer to something exhibiting System 2-like behavior.
Reflection takes time! All the approaches in this post trade off a bit of extra compute for a shot at better output quality. While this may not be appropriate for low-latency applications, it is worthwhile for knowledge intensive tasks where response quality is more important than speed.
The three examples are outlined below:
Basic Reflection
This simple example composes two LLM calls: a generator and a reflector. The generator tries to respond directly to the user's requests. The reflector is prompted to role play as a teacher and offer constructive criticism for the initial response.
The loop proceeds a fixed number of times, and the final generated output is returned.
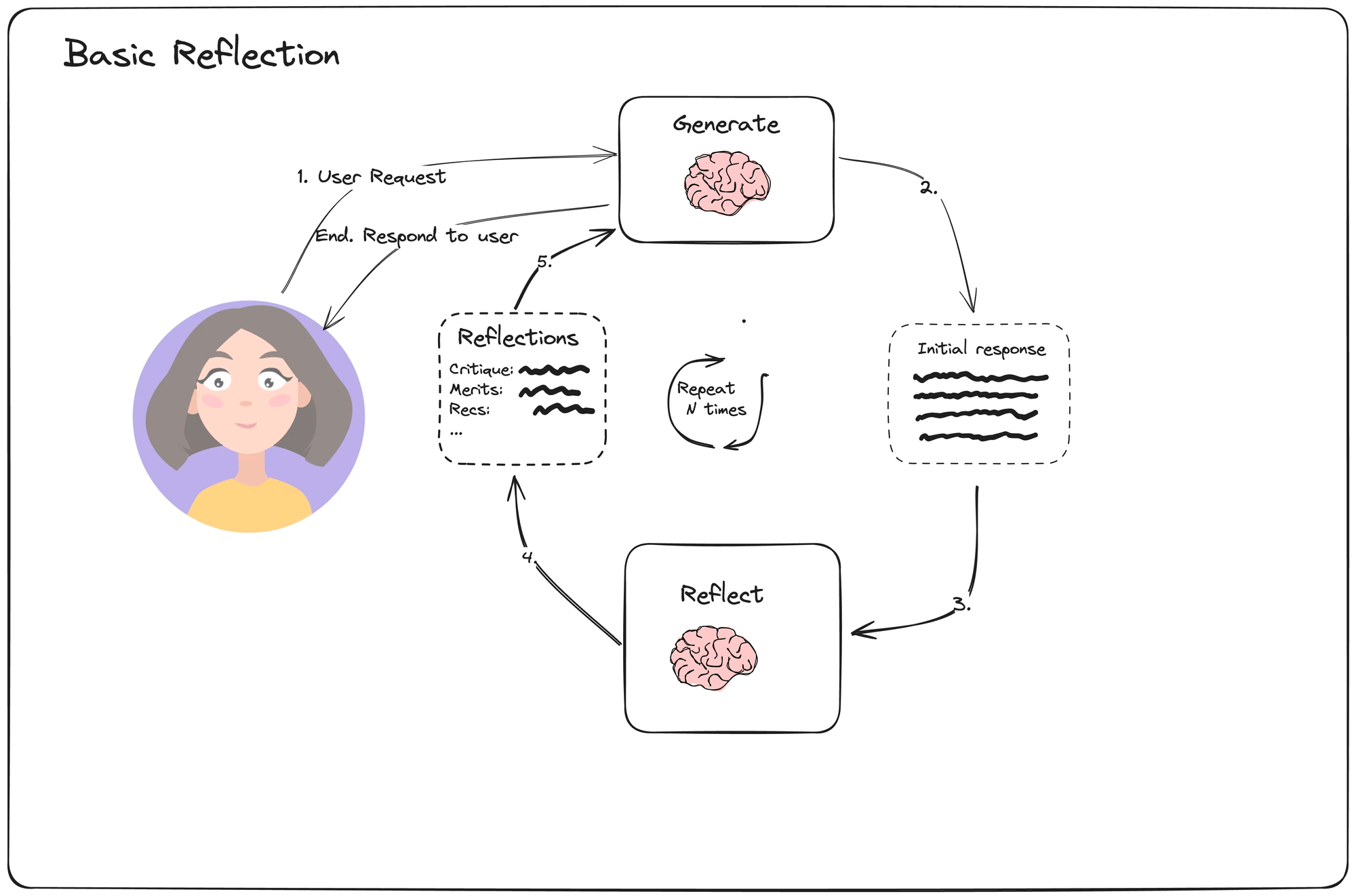
We can define the loop in LangGraph below:
from langgraph.graph import MessageGraph
builder = MessageGraph()
builder.add_node("generate", generation_node)
builder.add_node("reflect", reflection_node)
builder.set_entry_point("generate")
def should_continue(state: List[BaseMessage]):
if len(state) > 6:
return END
return "reflect"
builder.add_conditional_edges("generate", should_continue)
builder.add_edge("reflect", "generate")
graph = builder.compile()The MessageGraph represents a stateful graph, where the "state" is simply a list of messages. Each time the generator or reflector node is called, it appends a message to the end of the state. The final result is returned from the generator node.
This simple type of reflection can sometimes improve performance by giving the LLM multiple attempts at refining its output and by letting the reflection node adopt a different persona while critiquing the output.
However, since the reflection step isn't grounded in any external process, the final result may not be significantly better than the original. Let's explore some other techniques that can ameliorate that.
Reflexion
Reflexion by Shinn, et. al., is an architecture designed to learn through verbal feedback and self-reflection. Within reflexion, the actor agent explicitly critiques each response and grounds its criticism in external data. It is forced to generate citations and explicitly enumerate superfluous and missing aspects of the generated response. This makes the content of the reflections more constructive and better steers the generator in responding to the feedback.
In the linked example, we stop after a fixed number of steps, though you can also offload this decision to the reflection LLM call.
An overview of the agent loop is shown below:
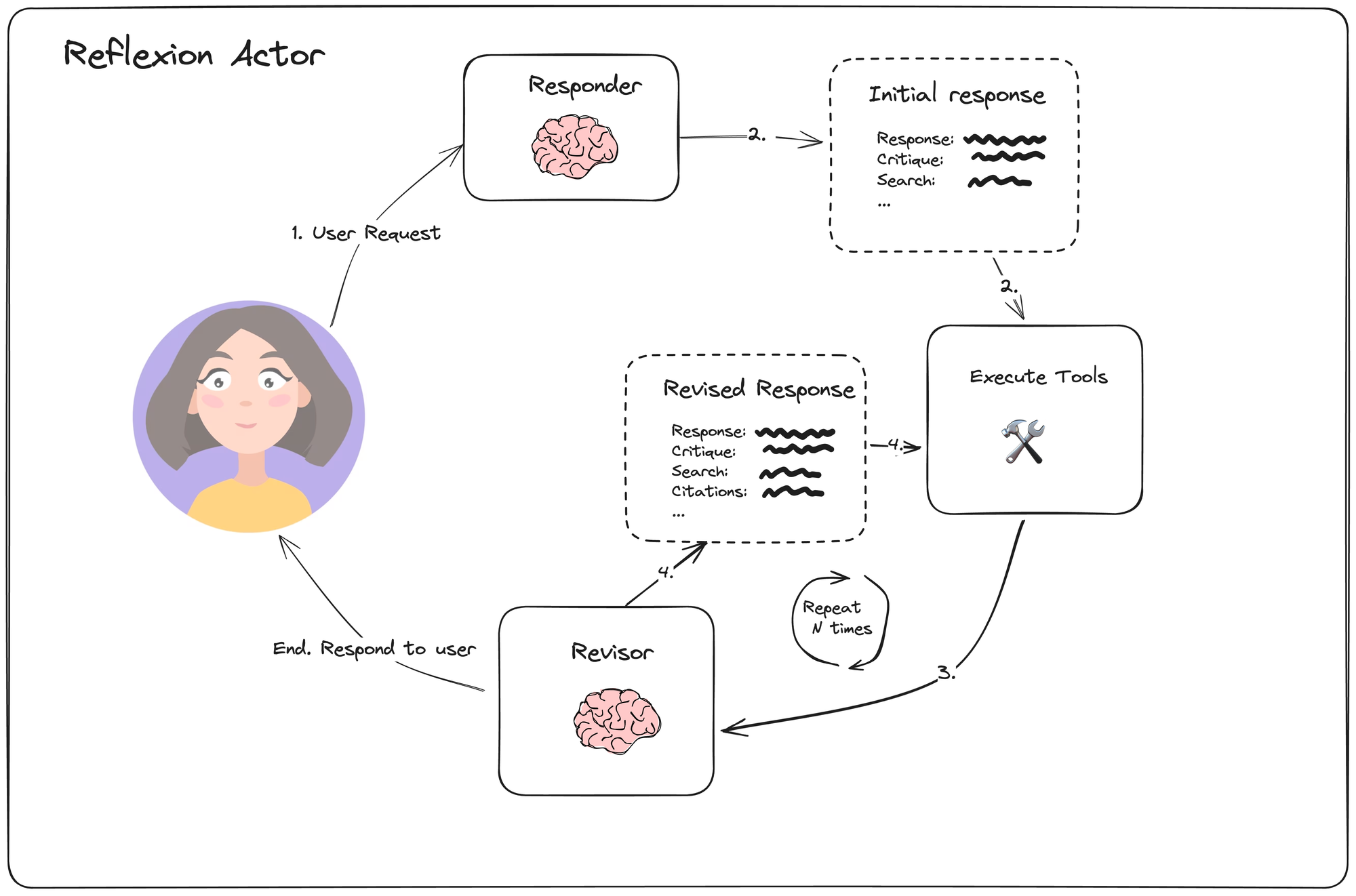
For each step, the responder is tasked with generating a response, along with additional actions in the form of search queries. Then the revisor is prompted to reflect on the current state. The logic can be defined in LangGraph as follows:
from langgraph.graph import END, MessageGraph
MAX_ITERATIONS = 5
builder = MessageGraph()
builder.add_node("draft", first_responder.respond)
builder.add_node("execute_tools", execute_tools)
builder.add_node("revise", revisor.respond)
# draft -> execute_tools
builder.add_edge("draft", "execute_tools")
# execute_tools -> revise
builder.add_edge("execute_tools", "revise")
# Define looping logic:
def event_loop(state: List[BaseMessage]) -> str:
# in our case, we'll just stop after N plans
num_iterations = _get_num_iterations(state)
if num_iterations > MAX_ITERATIONS:
return END
return "execute_tools"
# revise -> execute_tools OR end
builder.add_conditional_edges("revise", event_loop)
builder.set_entry_point("draft")
graph = builder.compile()This agent can effectively use explicit reflections and web-based citations to improve the quality of the final response. It only pursues one fixed trajectory, however, so if it makes a misstep, that error can impact subsequent decisions.
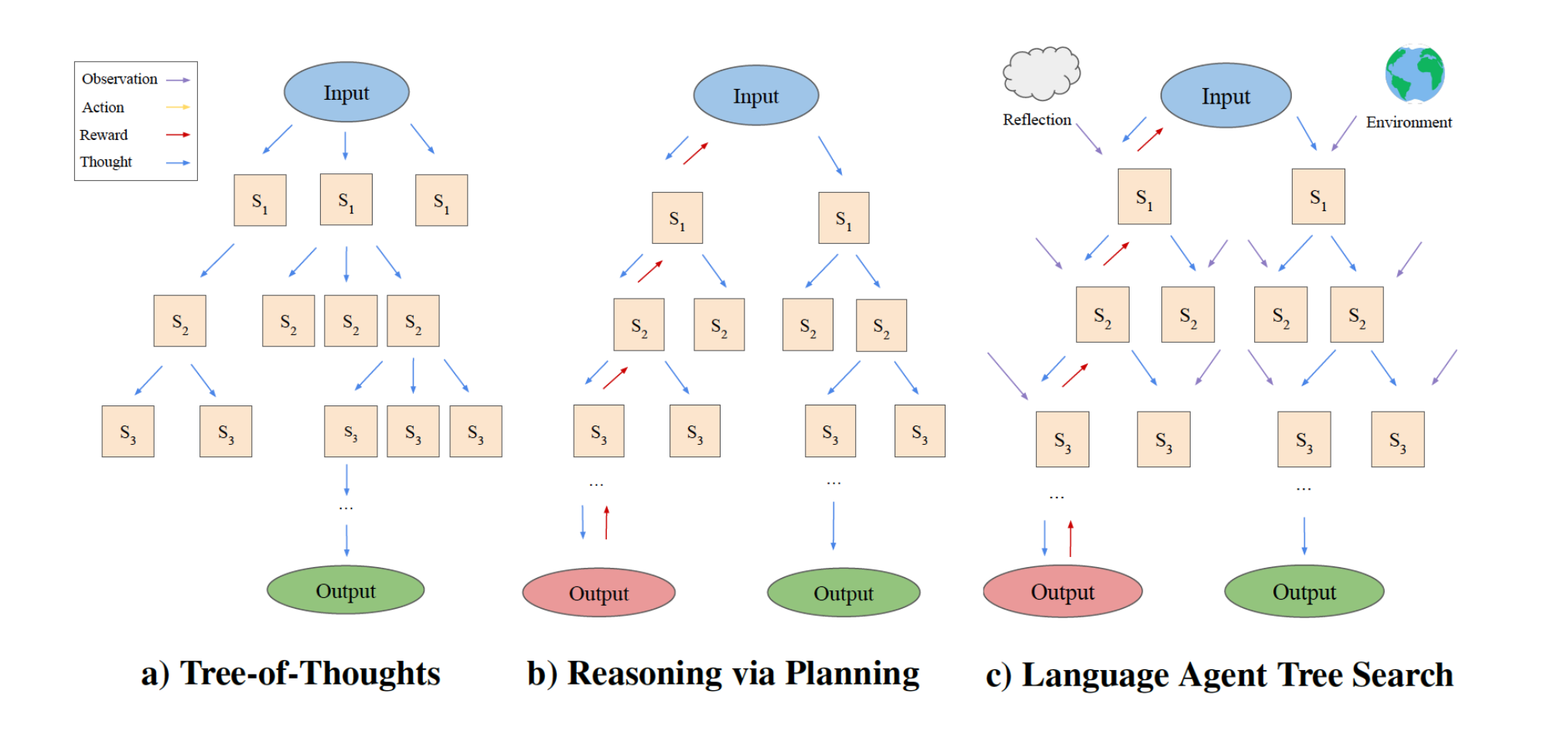
Language Agent Tree Search
Language Agent Tree Search (LATS), by Zhou, et. al, is a general LLM agent search algorithm that combines reflection/evaluation and search (specifically Monte-Carlo trees search) to achieve better overall task performance compared to similar techniques like ReACT, Reflexion, or even Tree of Thoughts. It adopts a standard reinforcement learning (RL) task framing, replacing the RL agents, value functions, and optimizer all with calls to an LLM. This is meant to help the agent adapt and problem solve for complex tasks, avoiding getting stuck in repetitive loops.
The search process is outlined in the diagram below:
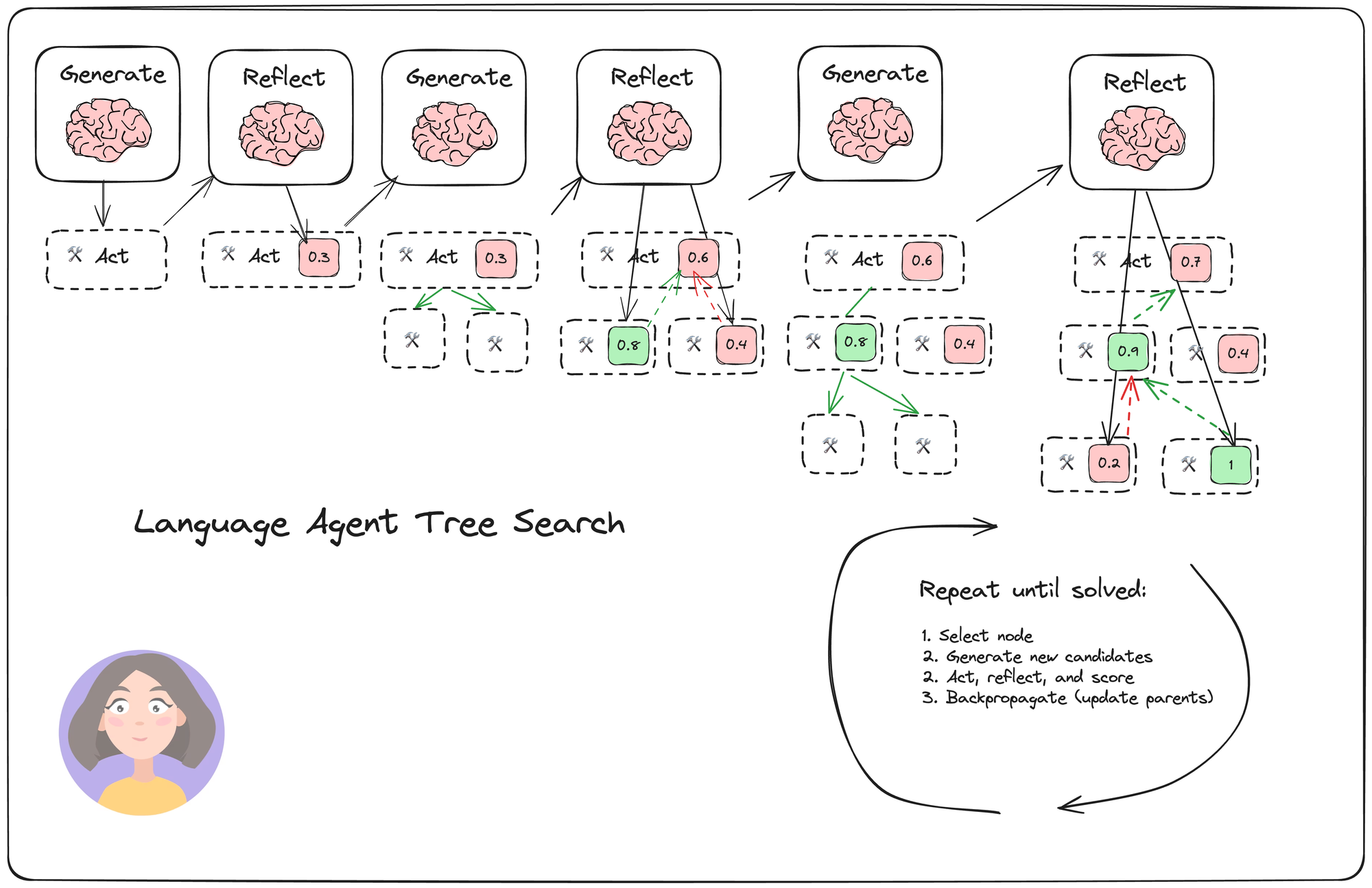
The search has four main steps:
- Select: pick the best next actions based on the aggregate rewards from step (2) below. Either respond (if a solution is found or the max search depth is reached) or continue searching.
- Expand and simulate: generate N (5 in our case) potential actions to take and execute them in parallel.
- Reflect + evaluate: observe the outcomes of these actions and score the decisions based on reflection (and possibly external feedback)
- Backpropagate: update the scores of the root trajectories based on the outcomes.
If the agent has a tight feedback loop (through high quality environment rewards or reliable reflection scores), the search is able to accurately distinguish between different action trajectories and pick the best path. The final trajectory can then be saved to external memory (or used for model fine-tuning) to improve the model in the future.
The "selection" step picks the node with the highest upper confidence bound (UCT), which just balances the expected reward (the first term) with an incentive to explore new paths (the second term).
\( UCT = \frac{\text{value}}{\text{visits}} + c \sqrt{\frac{\ln(\text{parent.visits})}{\text{visits}}}\)
Check out the code to see how it's implemented. In our LangGraph implementation, we put generation + reflection steps in a single node each, and check the tree state on each loop to see if the task is solved. The (abbreviated) graph definition looks something like below:
from langgraph.graph import END, StateGraph
class Node:
def __init__(
self,
messages: List[BaseMessage],
reflection: Reflection,
parent: Optional[Node] = None,
):
self.messages = messages
self.parent = parent
self.children = []
self.value = 0
self.visits = 0
# Additional methods are defined here. Check the code for more!
class TreeState(TypedDict):
# The full tree
root: Node
# The original input
input: str
def should_loop(state: TreeState):
"""Determine whether to continue the tree search."""
root = state["root"]
if root.is_solved:
return END
if root.height > 5:
return END
return "expand"
builder = StateGraph(TreeState)
builder.add_node("start", generate_initial_response)
builder.add_node("expand", expand)
builder.set_entry_point("start")
builder.add_conditional_edges(
"start",
# Either expand/rollout or finish
should_loop,
)
builder.add_conditional_edges(
"expand",
# Either continue to rollout or finish
should_loop,
)
graph = builder.compile()LATS Graph
Once you've created the basic outline, it's easy to expand to other tasks! For instance, this technique would suit code generation tasks well, where you the agent can write explicit unit tests and score trajectories based on test quality.
LATS unifies the reasoning, planning, and reflection components of other agent architectures, such as Reflexion, Tree of Thoughts, and plan-and-execute agents. LATS also from the backpropagation of reflective and environment-based feedback for an improved search process. While it can be sensitive to the reward scores, the general algorithm can be flexibly applied to a variety of tasks.
Video Tutorial
Conclusion
Thanks for reading! All of these examples can be found in the LangGraph repository, and we will port these to LangGraphJS soon (maybe by the time you read this post).
All of the techniques above leverage additional LLM inference to increase the likelihood of generating a higher quality output, or of responding correctly to a more complex reasoning task. While this takes extra time, it can be appropriate when output quality matters more than response time, and if you save the trajectories to memory (or as fine-tuning data), you can update the model to avoid repeat mistakes in the future.