Editor's Note: we're EXTREMELY excited to highlight this research from Ankush Garg and Shreya Shankar from Berkeley. At LangChain, two of the biggest problems we think about are evals and agents, and this research sits right at the intersection. You can try it out today in their Python package.
TLDR: It helps you find underperforming nodes in LLM chains.
The problem it solves
Building LLM-powered applications is challenging, and the complexity multiplies with LLM chains that can have multiple LLM calls per query.

While assessing the final outputs is critical in ensuring AI applications are working as designed, assessing intermediate outputs is largely ignored. This is most likely due to resource constraints applications developers may have.
A single node in an LLM chain can cause the entire chain to malfunction, causing a ripple effect, making it difficult to debug and fix.
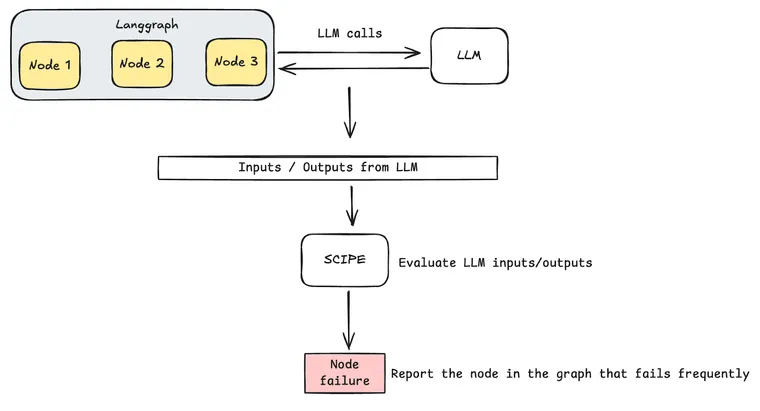
In this post, we introduce SCIPE, a lightweight, yet powerful tool that conducts error analysis on LLM chains. This tool can benefit anyone creating applications that rely on LLMs for making decisions and carrying out tasks.
SCIPE works by analyzing inputs and outputs for each node in the LLM chain and identifying the most important node to fix–the node that, if accuracy is improved, will most improve the final or downstream output accuracy.
You can try out SCIPE in our Colab Notebook.
Technical Details - How it works
SCIPE works by analyzing the failure probabilities of nodes in your application graph to identify the most impactful source of failures. Importantly, it requires no labeled data or ground truth examples to perform this analysis. The core problem it addresses is:
What node’s failures have the biggest impact on the most downstream node’s failures?
For each node in the application graph, SCIPE models two distinct types of failures that can occur:
- Independent Failures: These occur when the node itself (or the LLM processing it) may be the primary cause of the failure (i.e., the node fails even though its upstream dependencies are correct).
- Dependent Failures: These happen when a node fails while one or more of its upstream dependencies have failed.
To detect these failures without requiring ground truth data, SCIPE uses an LLM as a judge to evaluate each node in the graph.
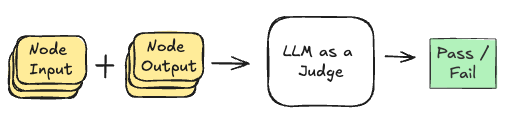
This evaluation process creates a pass/fail score for each node, for each of its input and output pairs. The LLM judge then determines whether each node's output is valid given its input, generating a comprehensive dataset of node evaluations across multiple samples. This dataset is used to calculate conditional and independent failure probabilities to find problematic nodes.
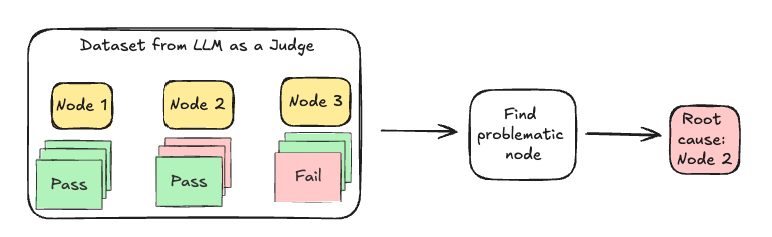
Starting from the most downstream node, SCIPE computes conditional failure probabilities to understand how each node's failures relate to its dependencies' failures. Conditional failure probability is the node failure rate while its dependency (parent node) is also failing.
If a node has no dependencies or its independent failure probability is highest among its local neighborhood, it's identified as a potential root cause, ending the analysis. Otherwise, the analysis continues recursively traversing upstream through the graph until the true root cause is identified–the node whose failures are most likely independent (originating from itself rather than being propagated from its dependencies).
To illustrate, here's high-level pseudocode on how SCIPE finds problematic nodes.
function find_root_cause(node, data, graph):
calculate probabilities for node (overall, independent, and dependent)
if node has no dependencies or independent failure probability is highest:
mark node as root cause
return node
else:
find dependency with highest conditional failure probability
recursively call find_root_cause on that dependency
function find_problematic_node(data, graph):
identify the most downstream node in the graph
root_cause = find_root_cause(downstream_node, data, graph)
calculate probabilities for all nodes in the graph
construct debug trace from downstream node to root cause
return EvaluationResult(root_cause, debug_path, node_results)
Getting Started: Prerequisites
If you are using SCIPE on your own application, you’ll need the following:
Graph
A compiled graph from Langgraph. We need to access the internal graph structure to run SCIPE.
Application Responses
We need prompts and LLM responses for all the nodes in our application as a dataframe. We need this to run validations on and to identify nodes that fail at the highest rate.
Each row of the application responses dataframe is a single user query that cascades through the entire LLM Graph. Here are a couple of example rows of the applications' input/output responses dataframe.

In this example, we have two rows of the dataframe with 3 LLM calls, each responsible for a single step.
- Redact PII
- Extract useful information
- Summarize the chat
Configs
- PATH_TO_SAVE_VALIDATIONS - Path for saving the LLM as a judge responses
- MODEL_NAME - Model to be used here. We support all the models supported by LiteLLM
- node_input_output_mappings - This creates the relationship between the application graph and the application responses.
Once we have application responses, a compiled graph, and have set up our configuration file, we’re ready to run validations and find the nodes with a high failure rate.
Example: How to use SCIPE
SCIPE uses a compiled StateGraph from LangGraph , which we’ll convert into a lightweight format by using convert_edges_to_dag function.
from scipe.middleware import convert_edges_to_dag
# Convert a compiled langgraph into a lightweight dag
converted_graph = convert_edges_to_dag(graph=graph)Define configs for the evaluator.
config = {
PATH_TO_SAVE_VALIDATIONS’: ‘validations.csv’,
‘MODEL_NAME’: ‘claude-3-5-sonnet-20240620’,
# Input and Output mappings for SCIPE
‘node_input_output_mappings’: {
‘pii_agent’: [‘pii_agent_input’, ‘pii_agent_output’],
‘extractor’:[‘extractor_input’, ‘extractor_output’],
‘Summarizer’: [‘summarizer_input’, ‘summarizer_output’]
}
}
We can then import LLMEvaluator from scipe and instantiate an object by passing in config, responses (application responses), and the graph we converted.
from scipe import LLMEvaluator
evaluator = LLMEvaluator(
config=config,
responses=application_responses, # DataFrame input/output pairs
graph=converted_graph # Converted Langgraph
)LLMEvaluator simplifies managing/running LLM-based evaluations on the application responses, and then finding problematic nodes in the application graph. First, it constructs input and output pairs from application responses based on the node_input_output_mappings in configs. Then, it runs validations using an LLM as Judge and saves the validations to the PATH_TO_SAVE_VALIDATIONS in the config.
results = evaluator.run_validation(
special_instructions=None
).find_problematic_node()
Note: The run_validation method can take in special_instructions, that we might want to pass to the LLM judge. These instructions will be appended to the LLM judge prompt that SCIPE uses internally.
The find_problematic_node() method traverses through the graph to figure out which node has the highest failure rate. Once it finds the problematic node, the algorithm stops and returns the result.
The output is an EvaluationResult which contains the root cause, the debug path (from terminal node backwards), and the failure rate for each node.
You can look at the results of the algorithm by converting the results to JSON.
results.to_json()Output:
{'root_cause': 'pii_agent',
'debug_path': ['summarizer', 'extractor', 'pii_agent'],
'node_results': {'summarizer': {'overall_failure_probability': 1.0,
'independent_failure_probability': 0.0,
'conditional_failure_probabilities': {'extractor': 1.0},
'dependencies': ['extractor'],
'is_root_cause': False},
'extractor': {'overall_failure_probability': 1.0,
'independent_failure_probability': 0.0,
'conditional_failure_probabilities': {'pii_agent': 1.0},
'dependencies': ['pii_agent'],
'is_root_cause': False},
'pii_agent': {'overall_failure_probability': 1.0,
'independent_failure_probability': 1.0,
'conditional_failure_probabilities': {},
'dependencies': [],
'is_root_cause': True}}}
Application developers can use the failure probabilities of problematic nodes up the LLM chain to further explore what’s causing this node to fail and what can be done to fix it. The results output here tell us that the pii_agent node is the root cause, failing independently at a higher rate compared to other nodes and should be fixed/improved upon.
Conclusion
In conclusion, SCIPE analyzes independent and dependent failure probabilities to identify the most impactful problematic node in the system. This helps developers pinpoint and fix issues in their LLM-based application graph, improving overall performance and reliability.
We're actively developing SCIPE and would love to hear from you! If you're interested in participating in our user study, have feedback on the tool, or want to stay updated on future developments, please email us at ankush-garg@berkeley.edu.