
Following our launch of long-term memory support, we're adding semantic search to LangGraph's BaseStore. Available today in the open source PostgresStore and InMemoryStore's, in LangGraph studio, as well as in production in all LangGraph Platform deployments.
Quick Links:
- Video tutorial on adding semantic search to the memory agent template
- How to guide on adding semantic search in LangGraph
- How to guide on adding semantic search in your LangGraph Platform deployment
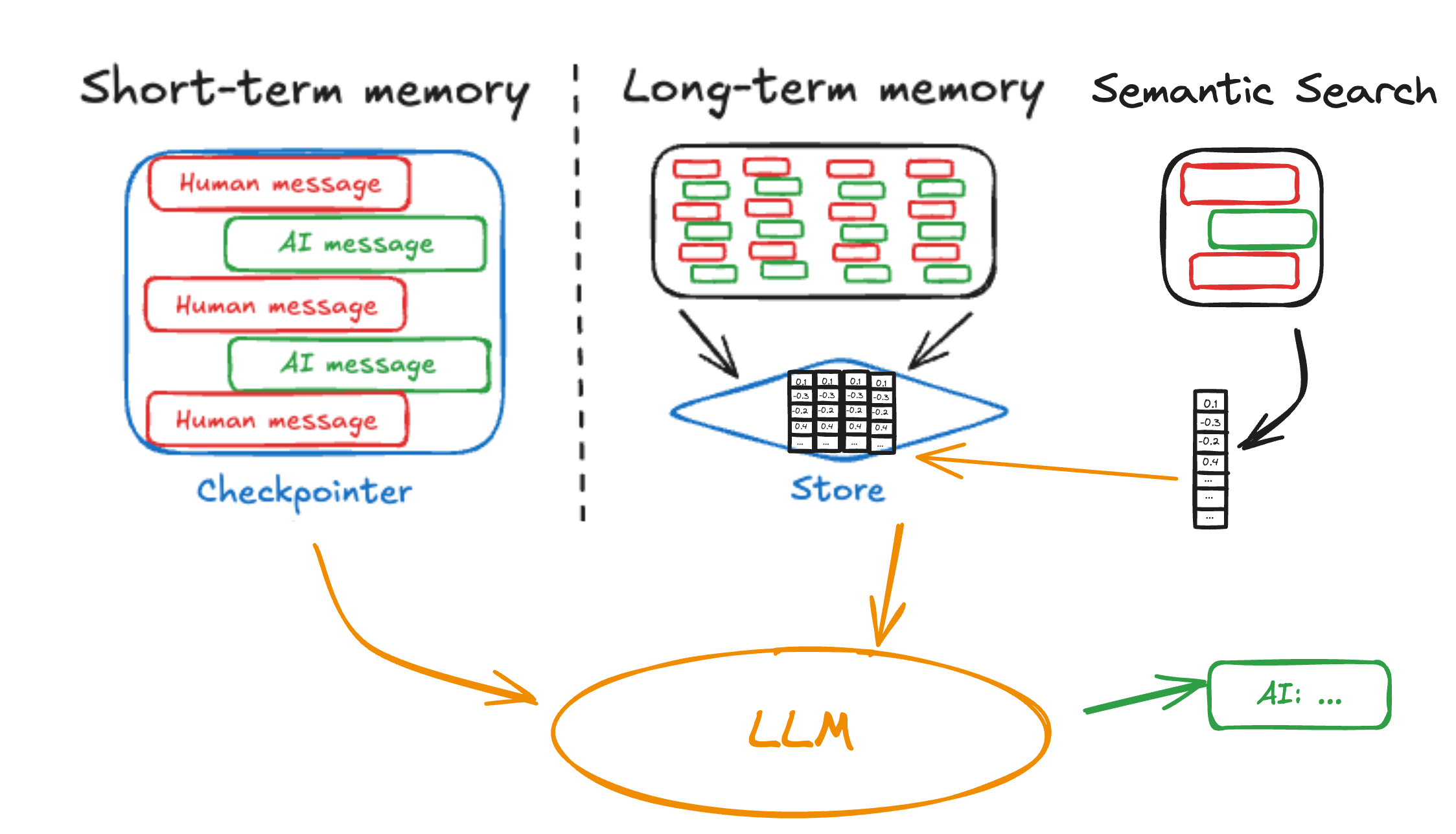
Why semantic search?
While our base memory implementation provides document storage and filtering, many users requested primitives for more sophisticated retrieval of unstructured information. Simple filtering works when you keep things well-organized, but agents often need to find relevant information based on meaning, not just exact matches.
For example, an agent might need to:
- Recall user preferences and past interactions for personalized responses
- Learn from past mistakes by retrieving similar failed approaches
- Maintain consistent knowledge by recalling important facts learned in previous interactions
Semantic search addresses these challenges by matching on meaning rather than exact content, making agents more effective at using their stored knowledge.
Implementation
The BaseStore 's search (and asynchronous asearch ) methods now support a natural language query term. If the store you are using has added support, documents will be scored and returned based on semantic similarity. Support has been added to both the InMemoryStore for development and PostgresStore for production. An example usage is below:
def search_memory(state: State, *, store: BaseStore):
results = store.search(
("user_123", "interactions"),
query=state["messages"][-1].content,
filter={"type": "conversation"},
limit=3
)
return {
"context": [
f"Previous interaction ({r.score:.2f} relevance):\n{r.value}"
for r in results
]
}
Example search node to lookup relevant memories.Example node querying for related content
To use in the LangGraph Platform, you can configure your server to embed new items through a store configuration in your langgraph.json file:
{
"store": {
"index": {
"embed": "openai:text-embeddings-3-small",
"dims": 1536,
"fields": ["text", "summary"]
}
}
}
The main configuration options:
embed: Embedding provider (e.g., "openai:text-embedding-3-small") or path to custom function (doc).provider:modelsupport depends on LangChain to use.dims: Dimension size of the chosen embedding model (1536 for OpenAI's text-embedding-3-small)fields: List of fields to index. Use["$"]to index entire documents, or specify json paths like["text", "summary", "messages[-1]"]
If you're not a LangChain user, or if you want to define custom embedding logic, define your own function:
async def aembed_texts(texts: list[str]) -> list[list[float]]:
response = await client.embeddings.create(
model="text-embedding-3-small",
input=texts
)
return [e.embedding for e in response.data]
Then reference your function in the config:
{
"store": {
"index": {
"embed": "path/to/embedding_function.py:embed_texts",
"dims": 1536
}
}
}
If you want to customize which fields to embed for a given item, or if you want to omit an item from being indexed, pass the index arg to store.put
# embed the configured default "text" field "Python tutorial"
store.put(("docs",), "doc1", {"text": "Python tutorial"})
# Override default field to embed "other_field" instead
store.put(
("docs",),
"doc2",
{"text": "TypeScript guide", "other_field": "value"},
index=["other_field"],
)
# Do not embed this item
store.put(("docs",), "doc2", {"text": "Other guide"}, index=False)See the docs for more information.
Migration
If you're already using LangGraph's memory store, adding semantic search is non-breaking. All operations work the same as before. LangGraph OSS users can start using by constructing their PostGresStore with an index configuration (sync & async docs):
from langchain.embeddings import init_embeddings
from langgraph.store.postgres import PostgresStore
store = PostgresStore(
connection_string="postgresql://user:pass@localhost:5432/dbname",
index={
"dims": 1536,
"embed": init_embeddings("openai:text-embedding-3-small"),
# specify which fields to embed. Default is the whole serialized value
"fields": ["text"],
},
)
store.setup() # Do this once to run migrations
For LangGraph platform users, once you add an index configuration to your deployment, new documents that are put into the store can be indexed for search, and you can add a natural language query string to return documents sorted by semantic similarity.
Next Steps
We've updated our documentation & templates to demonstrate semantic search in action. Check them out at the links below:
- Memory Template uses search over memories saved "in the background"
- Memory Agent searches over memories saved as a tool
- Video tutorial on adding semantic search to the memory agent template
- How to guide on adding semantic search in LangGraph
- How to guide on adding semantic search in your LangGraph Platform deployment
- Reference docs on the BaseStore
Try it out and share your feedback on GitHub.
And finally, for more conceptual information on AI memory, check out our memory conceptual documentation.