
Written by Shreya Shankar (UC Berkeley) in collaboration with Haotian Li (HKUST), Will Fu-Hinthorn (LangChain), Harrison Chase (LangChain), J.D. Zamfirescu-Pereira (UC Berkeley), Yiming Lin (UC Berkeley), Sam Noyes (LangChain), Eugene Wu (Columbia University), Aditya Parameswaran (UC Berkeley)
- Use SPADE to discover evaluation suggestions for your prompts.
- Complete the interest form to connect with the Berkeley researchers.
- Try out LangSmith and Hub to build and version control your LLM applications.
Many organizations really want to use LLMs in automated pipelines, or chains, in production. When prompted well, LLMs can make sense of and generate data and code at scale, with applications in a variety of domains.
But evaluating LLM chains for custom tasks is really hard: prompt engineering is an ad-hoc, iterative process, and most people muddle their way to a deployed chain without a clear sense of progress and how well the chain might do in production. It’s difficult to scale up the “vibe checks” we’re assessing LLMs for when building chains around them. Research shows that powerful models such as GPT-4 can be useful evaluators when instructed what to evaluate, but coming up with the scorecard of metrics to evaluate (and corresponding prompts) isn’t easy.
At Berkeley, we’ve been thinking about how to automatically write useful evaluation functions for custom LLM chains. We realized that when people iterate on prompts, they often encode key evaluation criteria, guardrails, and constraints–all as parts of refinements, or changes, to their prompts. Understanding prompt version history—or, what we like to call prompt refinement analysis—has some obvious applications, such as automatically writing prompts or generating datasets for fine-tuning. But what if prompt refinement analysis could also identify useful evaluation functions? It may seem like a super hard task, but turns out that with some clever decomposition, we can use an LLM!
We’re building a tool to automatically recommend evals called SPADE ♠ ️, or System for Prompt Analysis and Delta-based Evaluation. We’re excited to be collaborating with LangChain on this project and releasing a prototype of SPADE. You can paste your prompt or link to your LangSmith prompt version history, and based on your prompt refinements, SPADE might suggest automatic evaluation functions in Python that you can run on all your chain input-output (i.e., prompt-response) pairs. Evaluation functions can range in complexity, from asserting that an LLM response follows a specific format (i.e., inclusion of certain keys in a JSON object or headers in a Markdown object) to verifying that an LLM response doesn’t hallucinate sources beyond what is provided in the prompt.
In this blog post, I’ll explain how the tool works.
Digging into LLM evals with SPADE ♠
Before I explain how SPADE works, I’ll describe a concrete application of LLM chains and evaluation challenges. I started learning about LLM chain deployment challenges in May when I started working with Alta, a startup building an AI-enabled personal stylist and shopping assistant, to help solve some MLOps problems. Alta uses an LLM chain to suggest an outfit (i.e., top, bottom, shoes, etc) to wear for a user-specified event, like a business meeting or work event.
For Alta’s LLM chain, while initial prompt engineering demonstrated impressive outfits, users found many errors during deployment. Sometimes the LLM would return two items of the same category in an outfit. Sometimes the LLM would return an incomplete outfit (e.g., no shoes), or an inappropriate outfit (like rain boots in a fancy outfit for a dry day). The fastest way to “fix” the bugs was to add new instructions to the prompt, like “don’t recommend rain boots when it’s not raining.” But these refinements eventually piled up and made the prompts large, and there was no real guarantee that the LLM was following every instruction.
Smarter monitoring of LLM responses–based on what developers implicitly encode in their refinements to prompts–will significantly improve LLM deployment reliability. SPADE sits on top of prompt version history, suggesting evaluation functions based on the very prompt refinements themselves. Here’s an example of how this is done at Alta. Consider V1 and V2 of a prompt:
V1: “Suggest 5 apparel items to wear to {event}. Return your answer as a Python list of strings”
V2: “A client ({client_genders}) wants to be styled for {event}. Suggest 5 apparel items for {client_pronoun} to wear. For wedding-related events, don’t suggest any white items unless the client explicitly states that they want to be styled for their wedding. Return your answer as a python list of strings”
SPADE first finds the diff between the versions, i.e., any new instructions that didn’t exist in v1. In this example, SPADE will find two new placeholders (genders and pronoun), and an instruction to exclude white items for wedding-related events. Then, SPADE uses an LLM to categorize this diff based on a taxonomy we created that describes how prompts change (Figure 1).
For each category identified, SPADE prompts an LLM to write a relevant Python evaluation function. SPADE’s suggested evaluation functions accept prompt and response pairs as arguments and return boolean values (i.e., True or False) so they can be aggregated and visualized across many chain runs. These functions can run without LLMs (e.g., check if a response can be parsed as JSON or have specific keys) or leverage a helper function that submits a yes-or-no question to an LLM or human expert.
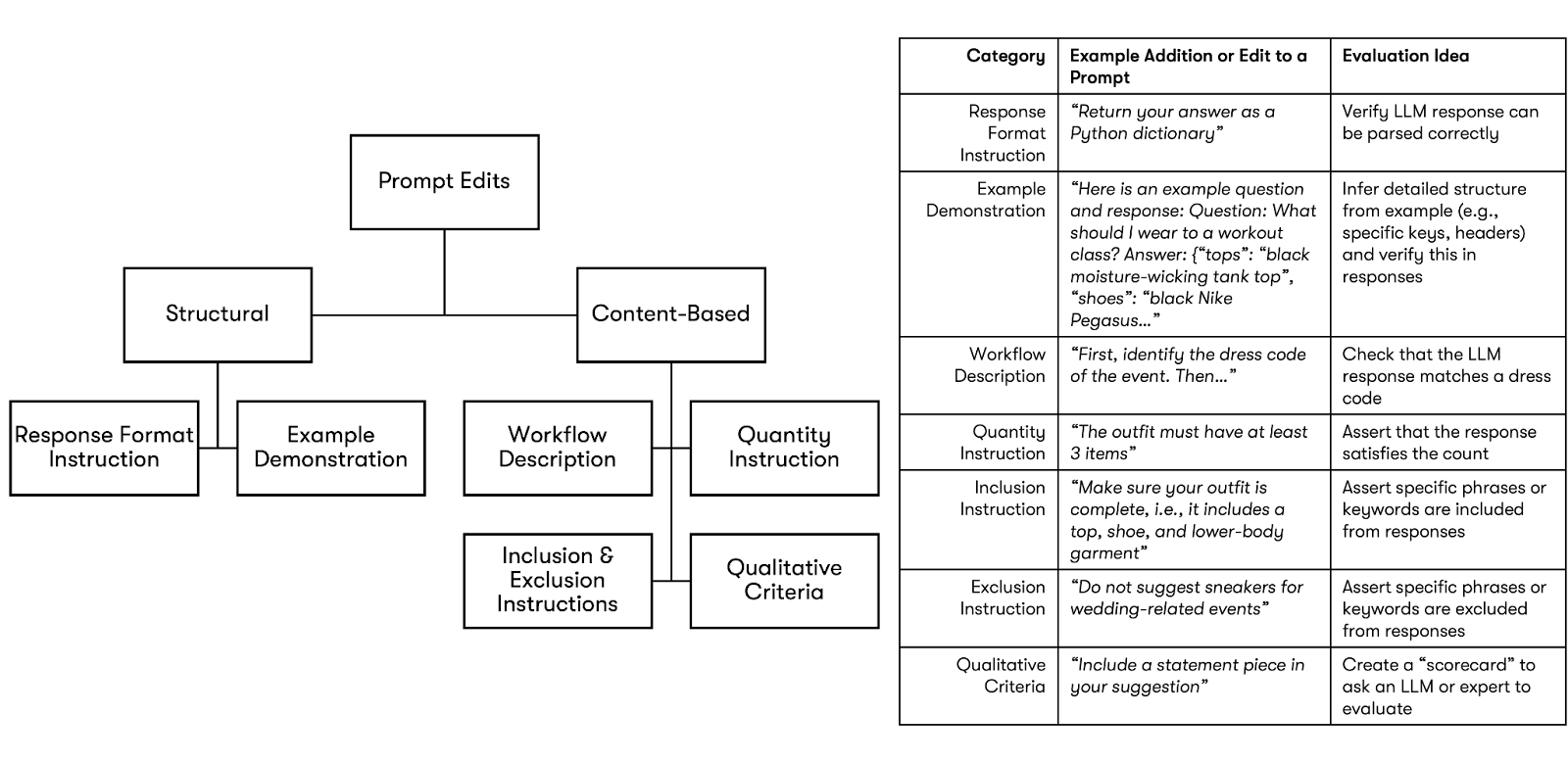
Putting this all together, for our example, SPADE would tag the diff with Data Integration and Exclusion Instruction categories. Since only the Exclusion Instruction category implies a new evaluation function in our taxonomy, SPADE would only suggest one eval: a function that checks whether the prompt contains an event related to a wedding, and if so, checks that the color “white” is not included in the response.
# Needs LLM: False
def check_excludes_white_wedding(prompt: str, response: str) -> bool:
"""
This function checks if the response does not include white items for wedding-related events,
unless explicitly stated by the client.
"""
# Check if event is wedding-related
if "wedding" in prompt.lower() and "my wedding" not in prompt.lower():
# Check if the response includes the word "white"
return "white" not in response.lower()
else:
return True
Example Evaluation Function
Current prototype and feedback
The current prototype of SPADE suggests evaluation functions for you to run on your chain’s inputs and outputs. In the app, you can either paste your prompt template that you want to generate evaluations for (we assume V0 of a prompt is an empty string), or you can point to your LangSmith prompt template (which automatically contains your prompt version history via commits). We show you all the categories of how your prompt changed between versions and suggest specific evaluation functions for your chain based on these categories.
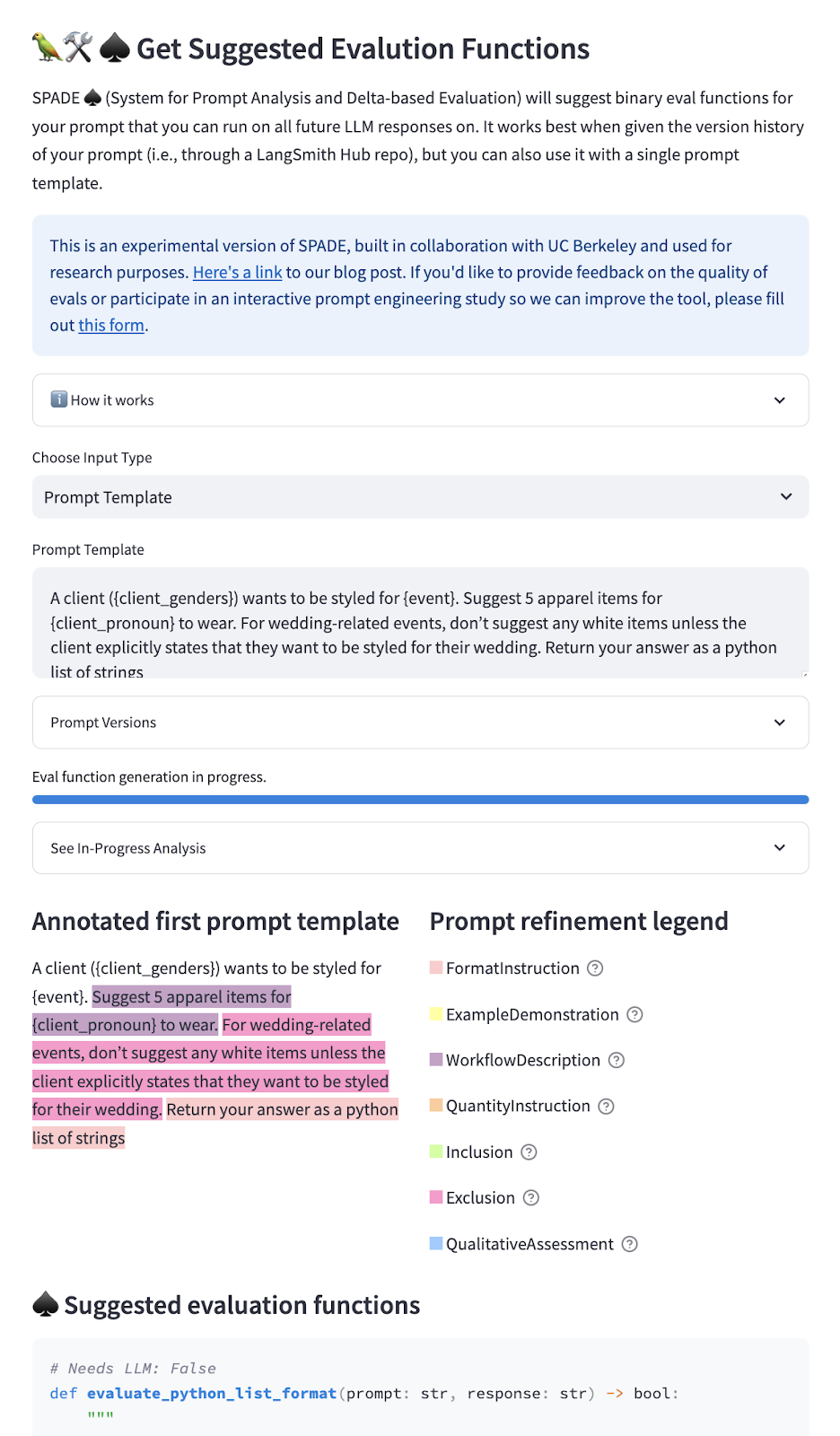
The current prototype of SPADE is a very preliminary research prototype—there’s lots of room for improvement! It identifies all possible prompt refinement categories (from our taxonomy) and generates a Python function for each category that indicates a relevant evaluation. As such, the number of suggested functions can explode with a large number of prompt versions. We’re separately working on reducing the number of suggested functions while still covering failure modes, but with the current prototype, we’re interested if any of the suggested functions are useful for developers at all–even if the meaning of the function is useful, but the function’s syntax is a little bit wrong.
While you can give explicit feedback on the functions generated for you, if you’re interested in this area of research more broadly or if you want to deploy these evaluation functions in an observability tool, please fill out this Google Form and we’ll be in touch. Otherwise, we’re grateful for any tool usage and feedback. Check it out and let us know what you think!
The code for SPADE is freely available at the linked GitHub repo.