
Editor's Note: Andrew Nguonly has been building one of the more impressive projects we've seen recently - an LLM co-pilot for browsing the web, powered by local LLMs. There are a lot of small architectural decisions made that contain a ton of nuance, and so we're super excited to post this blog by him going over one of them in detail.
Reintroducing Lumos! 🪄
I’ve written extensively about Lumos in the past so I’ll keep the reintroduction short and sweet. Lumos is an LLM co-pilot for browsing the web, powered by local LLMs. It’s a Chrome extension that scrapes the content on the current page and processes the parsed results in an online, in-memory RAG workflow, all in a single request context. Lumos is built on LangChain and powered by Ollama. It’s open-source and free to use.
Lumos is great for tasks that we know LLMs are strong at:
- summarizing news articles, threads, and chat histories
- asking questions about restaurant and product reviews
- extracting details from dense technical documentation
I’ve even found Lumos to be helpful with my Spanish studies. The ergonomics of the app are incredibly convenient. As I’m using the app more and more, I’m discovering new ways that LLMs in the browser can be handy.
Rebuilding the Calculator 🧮
For text-based tasks, LLMs are creative and clever. However, they are not designed to be deterministic. Andrej Karpathy once described LLMs as “dream machines.” An operation as simple as computing 456*4343 is not guaranteed by an LLM. For a complex equation with several operands and operators, even the top models don’t stand a chance.
What’s 456*4343 — 56/(443-11+4)?


LLMs need additional tools for certain work, such as executing code or solving math problems. Lumos is no exception. I don’t recall exactly why I needed a calculator in my browser (calculating taxes?), but I know I didn’t want to pull out my phone or open a new tab. I just wanted my LLM to answer the math problem correctly.
So, I decided to build a calculator into Lumos.
Prompt Classification with Ollama 🦙
I previously experimented with prompt classification using Ollama and deemed that the technique was very valuable. The output of a “classification prompt” could supercharge if-statements and branching logic if reliable.
Although Lumos is not implemented as a LangChain Agent, I wanted the experience of using it to be like that of interacting with one. It should execute tools independent of direct instruction. The app should just know when to use a calculator. Using Ollama to determine if a prompt needed the calculator tool was easy to implement.
const isArithmeticExpression = async (
baseURL: string,
model: string,
prompt: string,
): Promise<boolean> => {
// check for prefix trigger
if (prompt.trim().toLowerCase().startsWith("calculate:")) {
return new Promise((resolve) => resolve(true));
}
// otherwise, attempt to classify prompt
const ollama = new Ollama({ baseUrl: baseURL, model: model, temperature: 0, stop: [".", ","]});
const question = `Is the following prompt a math equation with numbers and operators? Answer with 'yes' or 'no'.\n\nPrompt: ${prompt}`;
return ollama.invoke(question).then((response) => {
console.log(`isArithmeticExpression classification response: ${response}`);
const answer = response.trim().split(" ")[0].toLowerCase();
return answer.includes("yes");
});
};Simply ask the LLM if the prompt was a math equation with numbers and operators and check if the response contained a “yes” or “no”. Dead simple. The implementation is even reliable without JSON mode or function calling. Prompting an LLM for a binary response contrasts with the approach of asking it to classify against an arbitrary number of potentially unrelated categories. This scenario arises when trying to match prompts with tools.
Llama2 and Mistral both performed well in my testing. Setting the model temperature to 0 and configuring stop sequences ([".", ","]) improved reliability and response latency even further. Relative to the average inference time experienced by a user for regular prompts (e.g. several seconds), the elapsed time for classification was only incremental. Admittedly, this added latency may not be sufficient for some use cases.
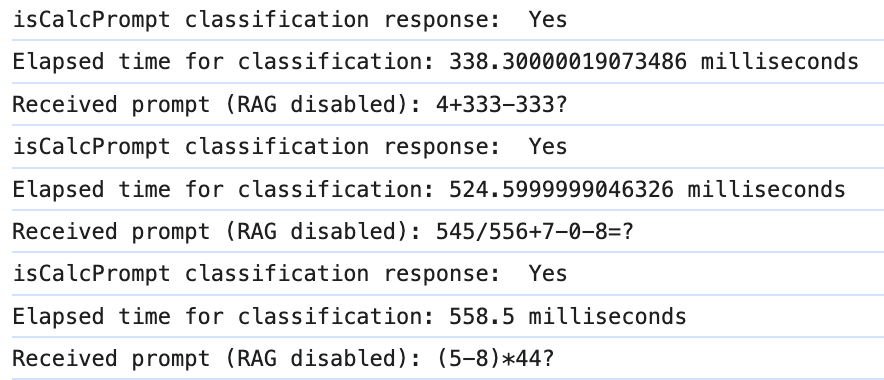
It’s also important to reiterate that leveraging local LLMs makes this operation effectively free. The utility of Ollama truly shines for this use case. To give users maximum control, the mechanism also includes functionality for a trigger, a prefix that the user can include in the prompt to guarantee that a tool will be executed. This is similar to ChatGPT’s @ reference to invoke specific GPTs.
456 x 4343 = 1980408 🔢
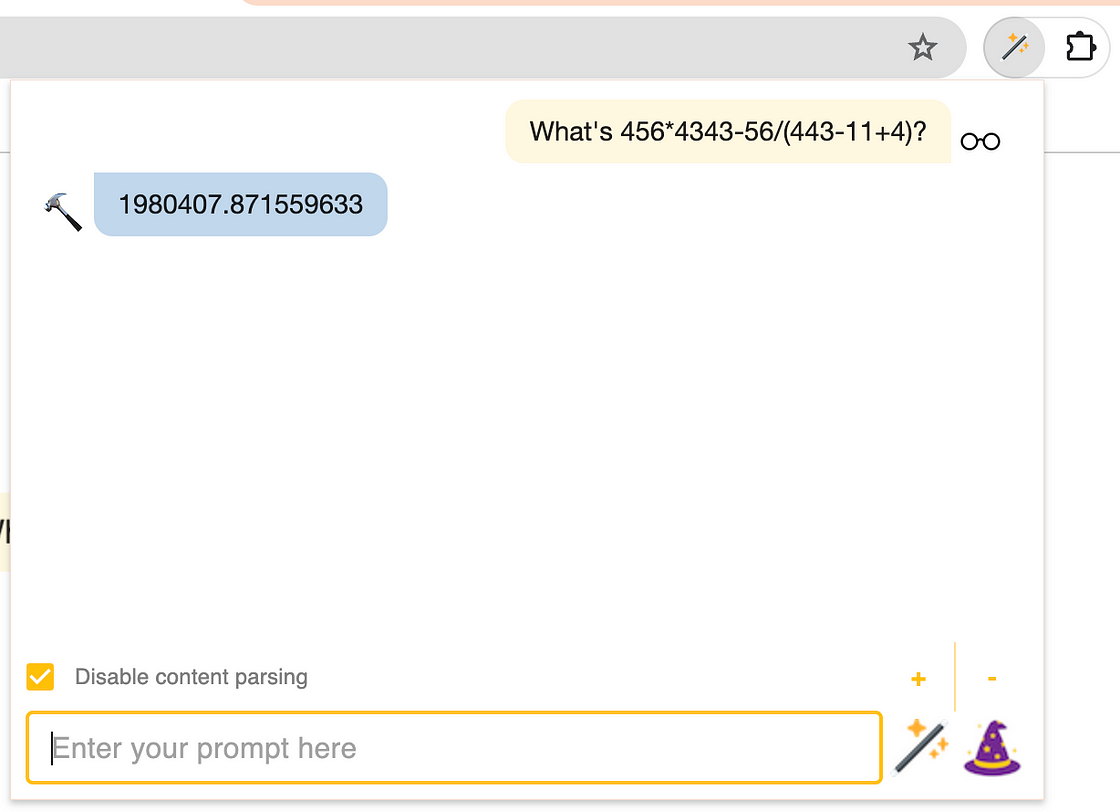
The implementation of Lumos’s calculator is straightforward. It’s built as a LangChain Tool to preserve future portability of the app into a robust Agent. For custom tools, LangChain suggests building a DynamicTool or DynamicStructuredTool, but it’s easy to subclass the base Tool class as well.
import { Tool } from "@langchain/core/tools";
export class Calculator extends Tool {
name = "calculator";
description = "A tool for evaluating arithmetic expressions";
constructor() {
super();
}
protected _call = (expression: string): Promise<string> => {
const tokens = this._extractTokens(expression);
let answer;
try {
answer = this._evaluateExpression(tokens);
} catch (error) {
if (error instanceof Error) {
answer = `Error: ${error.message}`;
} else {
answer = "Error: Unable to execute calculator tool.";
}
}
return Promise.resolve(answer.toString());
};
_extractTokens = (expression: string): string[] => { ... };
_evaluateExpression = (tokens: string[]): number => { ... };
}When Lumos receives a prompt that resembles a math equation, simple or complex, it simply knows to invoke the calculator.
Scaling Classification For Complex Conditionals 🌲
The classification technique is replicated again for Lumos’s multimodal functionality. If a user asks about an image, the app should know to download the image from the page. Otherwise, it should skip the download for obvious efficiency reasons. I decided to generalize the approach and make a configurable function.
const classifyPrompt = async (
baseURL: string,
model: string,
type: string,
originalPrompt: string,
classifcationPrompt: string,
prefixTrigger?: string,
): Promise<boolean> => {
// check for prefix trigger
if (prefixTrigger) {
if (originalPrompt.trim().toLowerCase().startsWith(prefixTrigger)) {
return new Promise((resolve) => resolve(true));
}
}
// otherwise, attempt to classify prompt
const ollama = new Ollama({
baseUrl: baseURL,
model: model,
temperature: 0,
stop: [".", ","],
});
const finalPrompt = `${classifcationPrompt} Answer with 'yes' or 'no'.\n\nPrompt: ${originalPrompt}`;
return ollama.invoke(finalPrompt).then((response) => {
console.log(`${type} classification response: ${response}`);
const answer = response.trim().split(" ")[0].toLowerCase();
return answer.includes("yes");
});
};Now, classifyPrompt() accepts a “classification prompt” and a trigger parameter. The function can be reused throughout the application code.
The decision to download an image is also predicated on the availability of a multimodal model (e.g. LLaVA). A user must have downloaded one before issuing a prompt to describe an image. In Lumos, user configuration is also checked as part of the download decision.
import { getLumosOptions, isMultimodal } from "../pages/Options";
const CLS_IMG_TYPE = "isImagePrompt";
const CLS_IMG_PROMPT = "Is the following prompt referring to an image or asking to describe an image?";
const CLS_IMG_TRIGGER = "based on the image";
const options = await getLumosOptions();
if (
isMultimodal(options.ollamaModel) &&
(await classifyPrompt(
options.ollamaHost,
options.ollamaModel,
CLS_IMG_TYPE,
prompt,
CLS_IMG_PROMPT,
CLS_IMG_TRIGGER,
))
) {
// download images
...
}Including the classification result in an if-statement expression felt natural, simple, and effective. With this method, a developer has full control over the execution of an application. To some degree, code branches that depend on LLMs potentially become testable!
For Lumos to determine whether an image is downloaded or not, the classification result is combined with the user’s configuration state. Moreover, consistent decision-making based on combining complex application states (e.g. user configuration, access controls, cache state, etc) and classification results may be more challenging for LLMs to accomplish at scale.
A/B testing several LLM features at once may benefit from this approach. For sensitive use cases such as permissioned tool execution or privileged data access for RAG, this design may be attractive. No decision can be left to chance.
What’s Next For Lumos? 🔮
In the short term, I’ll continue to explore integrating more tools into Lumos. I’ll evaluate the benefits of migrating to an Agent architecture and chip away at some of the known efficiency and speed challenges with running local LLM apps.
In the long term, however, there is a bigger opportunity to consider. A Chrome extension is powerful, but it is still very limited in its capability. As I’m thinking through new use cases for LLMs in the browser, it’s worth examining whether or not a new browser is needed altogether. For now, these are just ideas. In the meantime, I’ll just enjoy the rollercoaster that is building LLM apps at this early and exciting time. LangChain and Ollama make the ride a little bit smoother. 😎