Most complex and knowledge-intensive LLM applications require runtime data retrieval for Retrieval Augmented Generation (RAG). A core component of the typical RAG stack is a vector store, which is used to power document retrieval.
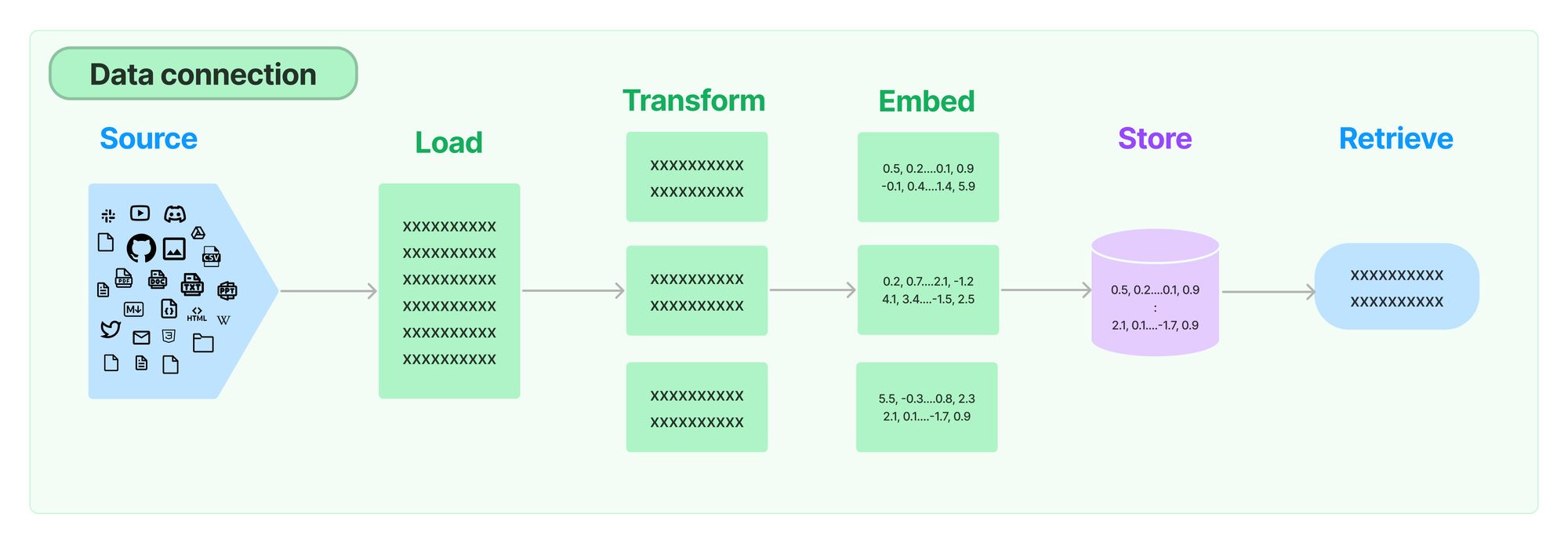
Using a vector store requires setting up an indexing pipeline to load data from sources (a website, a file, etc.), transform the data into documents, embed those documents, and insert the embeddings and documents into the vector store.
If your data sources or processing steps change, the data needs to be re-indexed. If this happens regularly, and the changes are incremental, it becomes valuable to de-duplicate the content being indexed with the content already in the vector store. This avoids spending time and money on redundant work. It also becomes important to set up vector store cleanup processes to remove stale data from your vector store.
LangChain Indexing API
The new LangChain Indexing API makes it easy to load and keep in sync documents from any source into a vector store. Specifically, it helps:
- Avoid writing duplicated content into the vector store
- Avoid re-writing unchanged content
- Avoid re-computing embeddings over unchanged content
Crucially, the indexing API will work even with documents that have gone through several transformation steps (e.g., via text chunking) with respect to the original source documents.
How it works
LangChain indexing makes use of a record manager (RecordManager) that keeps track of document writes into a vector store.
When indexing content, hashes are computed for each document, and the following information is stored in the record manager:
- the document hash (hash of both page content and metadata)
- write time
- the source id -- each document should include information in its metadata to allow us to determine the ultimate source of this document
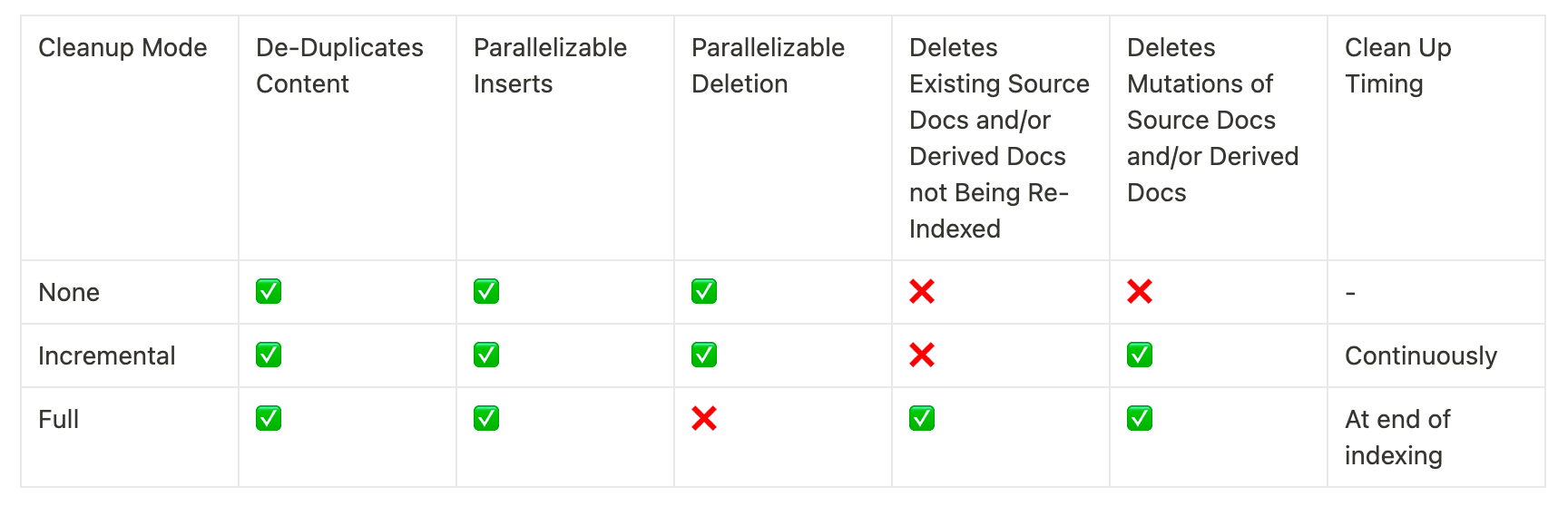
Cleanup modes
When re-indexing documents into a vector store, it's possible that some existing documents in the vector store should be deleted. If you’ve made changes to how documents are processed before insertion or source documents have changed, you’ll want to remove any existing documents that come from the same source as the new documents being indexed. If some source documents have been deleted, you’ll want to delete all existing documents in the vector store and replace them with the re-indexed documents.
The indexing API cleanup modes let you pick the behavior you want:
For more detailed documentation of the API and its limitations, check out the docs: https://python.langchain.com/docs/modules/data_connection/indexing
Seeing it in action
First let’s initialize our vector store. We’ll demo with the ElasticsearchStore, since it satisfies the pre-requisites of supporting insertion and deletion. See the Requirements docs section for more on vector store requirements.
# !pip install openai elasticsearch
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import ElasticsearchStore
collection_name = "test_index"
# Set env var OPENAI_API_KEY
embedding = OpenAIEmbeddings()
# Run an Elasticsearch instance locally:
# !docker run -p 9200:9200 -e "discovery.type=single-node" -e "xpack.security.enabled=false" -e "xpack.security.http.ssl.enabled=false" docker.elastic.co/elasticsearch/elasticsearch:8.9.0
vector_store = ElasticsearchStore(
collection_name,
es_url="<http://localhost:9200>",
embedding=embedding
)
And now we’ll initialize and create a schema for our record manager, for which we’ll just use a SQLite table:
from langchain.indexes import SQLRecordManager
namespace = f"elasticsearch/{collection_name}"
record_manager = SQLRecordManager(
namespace, db_url="sqlite:///record_manager_cache.sql"
)
record_manager.create_schema()
Suppose we want to index the reuters.com front page. We can load and split the url contents with:
# !pip install beautifulsoup4 tiktoken
import bs4
from langchain.document_loaders import RecursiveUrlLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
raw_docs = RecursiveUrlLoader(
"<https://www.reuters.com>",
max_depth=0,
extractor=lambda x: BeautifulSoup(x, "lxml").text
).load()
processed_docs = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=200
).split_documents(raw_docs)
And now we’re ready to index! Suppose when we first index only the first 10 documents are on the front page:
from langchain.indexes import index
index(
processed_docs[:10],
record_manager,
vector_store,
cleanup="full",
source_id_key="source"
)
{'num_added': 10, 'num_updated': 0, 'num_skipped': 0, 'num_deleted': 0}
And if we index an hour later, maybe 2 of the documents have changed:
index(
process_docs[2:10] + processed_docs[-2:],
record_manager,
vector_store,
cleanup="full",
source_id_key="source",
)
{'num_added': 2, 'num_updated': 0, 'num_skipped': 8, 'num_deleted': 2}
Looking at the output, we can see that while 10 documents were indexed the actual work we did was 2 additions and 2 deletions — we added the new documents, removed the old ones and skipped all the duplicate ones.
For more in-depth examples, head to: https://python.langchain.com/docs/modules/data_connection/indexing
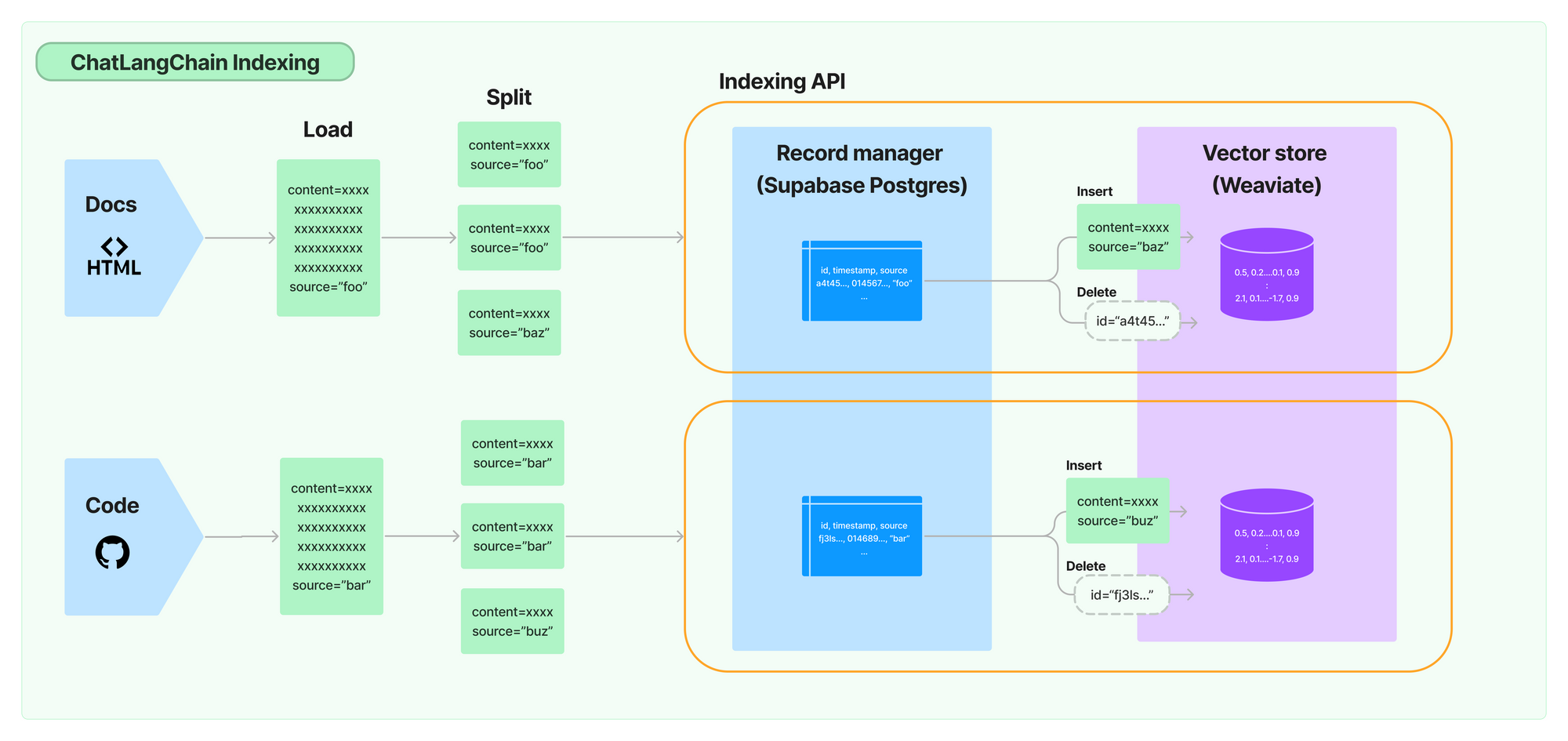
ChatLangChain + Indexing API
We’ve recently revamped the https://github.com/langchain-ai/chat-langchain chatbot for questions about LangChain. As part of the revamp, we revived the hosted version https://chat.langchain.com and set up a daily indexing job using the new API to make sure the chatbot is up to date with the latest LangChain developments.
Doing this was very straightforward — all we had to do was:
- Set up a Supabase Postgres database to be used as a record manager,
- Update our ingestion script to use the indexing API instead of inserting documents to the vector store directly,
- Set up a scheduled Github Action to run the ingestion script daily. You can check out the GHA workflow here.
Conclusion
As you move your apps from prototype to production, be able to re-indexing efficiently and keep documents in your vector in sync with their source becomes very important. LangChain's new indexing API provides a clean and scalable way to do this.
Try it out and let us know what you think!