
Editor's Note. This blog post was written by Ryan Brandt, the CTO and Cofounder of ChatOpenSource, a business specializing in enterprise AI chat that runs entirely within an orgs network, no third party needed. He covers how he uses LangSmith, LangChain's platform for getting LLM applications to production. Sign up for access here.
Open source models are increasingly capable for use in applications. The trend is only accelerating with recent releases like Mistral 7b and the Llama2 family. The future seems to be in the ability to quickly swap better models in and out of your application like cartridges in an old game console. Fine tuning different versions of a model only increases the number of possible cartridges a developer will need to compare.
So that begs the question, how can we productionize the evaluation of our models so we can can choose the best tool for the job? LangSmith offers us a way out of python script hell with a handy UI and API for creating evaluation datasets. With these datasets we can run tests on multiple models and directly compare their performance on multiple axis’.
It’s easy to upload data to LangSmith via python or the user interface. For our example notebook scroll to the end.

The Process
Here’s the way we organized the study:
- Initiation: The task began with a goal to fine-tune the Llama2-7b and Llama2-13b model using the sql-create-context dataset on Hugging Face.
- Data Conversion: The dataset from Hugging Face, originally in JSON, was transformed to .jsonl for chat fine-tuning.
- Data Sampling with GPT-4: GPT-4's Code Interpreter was used to select 10,000 rows from the dataset.
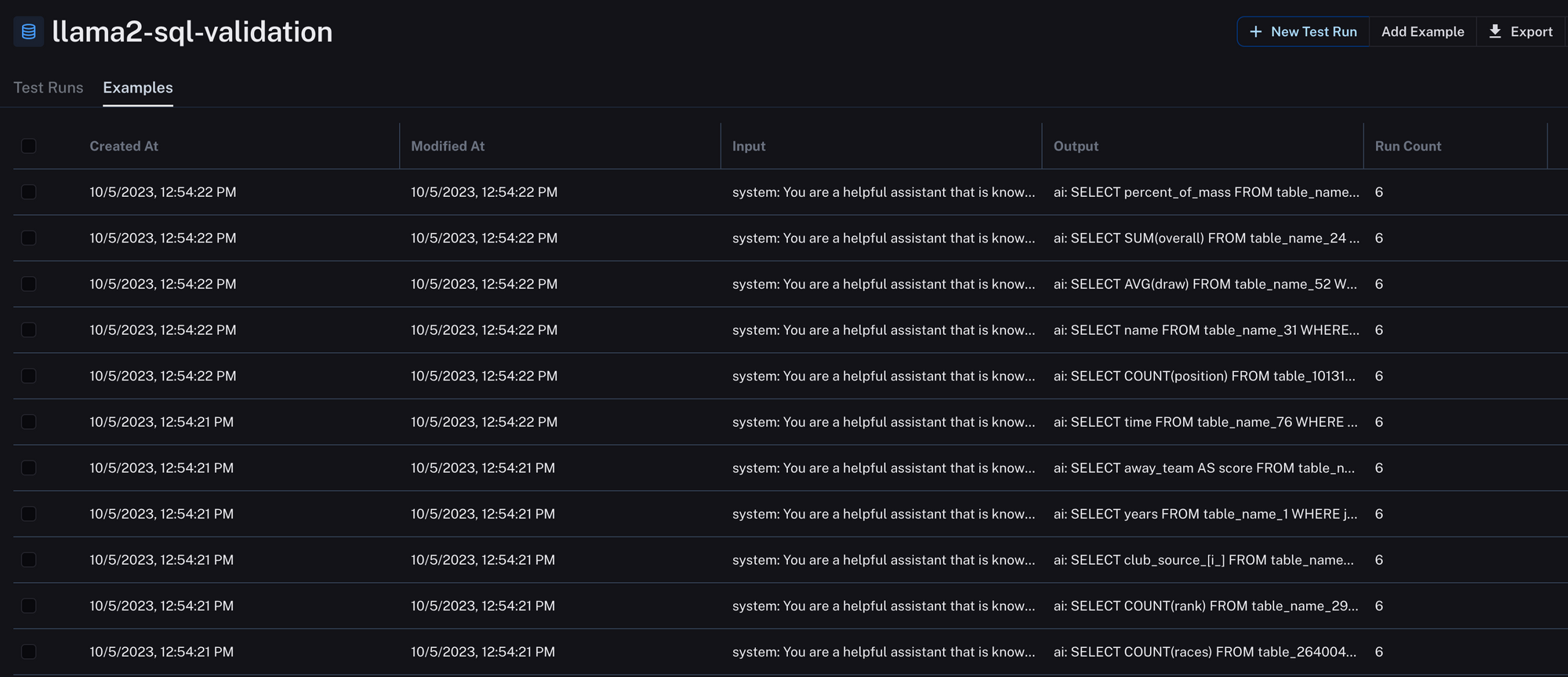
- Validation Set Creation: 1000 unique sql rows were chosen as a validation set, ensuring no overlap with the training data. We uploaded those testing rows to LangSmith so we could automate our evaluations.
from langsmith import Client
def create_dataset(dataset_name=None):
"""adds an example run with inputs and outputs to an existing dataset"""
client = Client()
dataset_name = dataset_name
client.create_dataset(dataset_name=dataset_name)
return dataset_name
def add_to_dataset(dataset_name, validation_file_path):
client = Client()
dataset = client.read_dataset(dataset_name=dataset_name)
# Open and process the validation file
with open(validation_file_path, 'r') as f:
for line in f:
data = json.loads(line)
example = data['prompt']
assistant_content = data['completion']
# Add to dataset using client API
client.create_chat_example(
messages=[
{"type": "system", "data": {"content": "You are a helpful assistant that is knowledgeable about sql. Only output the SQL."}},
{"type": "human", "data": {"content": example}}
],
generations={"type": "ai", "data": {"content": assistant_content}},
dataset_id=dataset.id
)
5. Fine-tuning and Assessment: The main goal was to improve Llama2-7b-chat and Llama2-13b-chat for specific SQL output. We fine tuned Llama2-7b-chat with 78k rows of sql data, and Llama2-13b-chat with 10k rows to control for cost. Both fine tuning and inference were done on an 8xA40 cluster. We did full parameter tuning, not LoRA. To do this we used Replicate, a platform for model hosting and fine tuning. You can learn more about them here.
import replicate
training = replicate.trainings.create(
version="meta/llama-2-13b-chat:f4e2de70d66816a838a89eeeb621910adffb0dd0baba3976c96980970978018d",
input={
"train_data": "https://storage.googleapis.com/chatopensource-replicate-demo/selected_sql_create_context_v4.jsonl",
"num_train_epochs": 3
},
destination="papermoose/test"
)6. LangSmith Evaluation: We used LangSmith to test the 1000 prompts on each model. We compared their result to the known correct answer to determine whether the model’s output was correct or not. We used GPT-4 to do the evals itself. LangSmith made the process extremely simple, as shown below.
import replicate
async def evaluate_dataset(dataset_name=None, num_repetitions=1, model="gpt-4-0613", project_name=None):
"""runs the model you want to evaluate against the assumed to be correct examples in your dataset, grading the evaluated model output correct or incorrect."""
from langchain.smith import run_on_dataset, RunEvalConfig, arun_on_dataset
from langchain.chat_models import ChatOpenAI
# The chat model you want to test, in our case replicate
model_to_test = Replicate(
model=model,
model_kwargs={"temperature": 0.75, "max_length": 500, "top_p": 1},
)
client = Client()
"""runs a question/answer evaluation, where the eval llm (gpt-4) will determine
if model_to_test's outputs are correct based on the example_dataset we uploaded in the previous set.
the example_dataset is treated by the eval as a correct answer for the given input."""
eval_config = RunEvalConfig(
evaluators=[
"cot_qa"
],
)
chain_results = await arun_on_dataset(
client,
dataset_name=dataset_name,
llm_or_chain_factory=model_to_test,
evaluation=eval_config,
num_repetitions=num_repetitions,
project_name=project_name
)The LangSmith platform itself allows you to view the results of our eval, in this case the chain of thought question answer builtin eval. You can also write your own if desired as shown here!
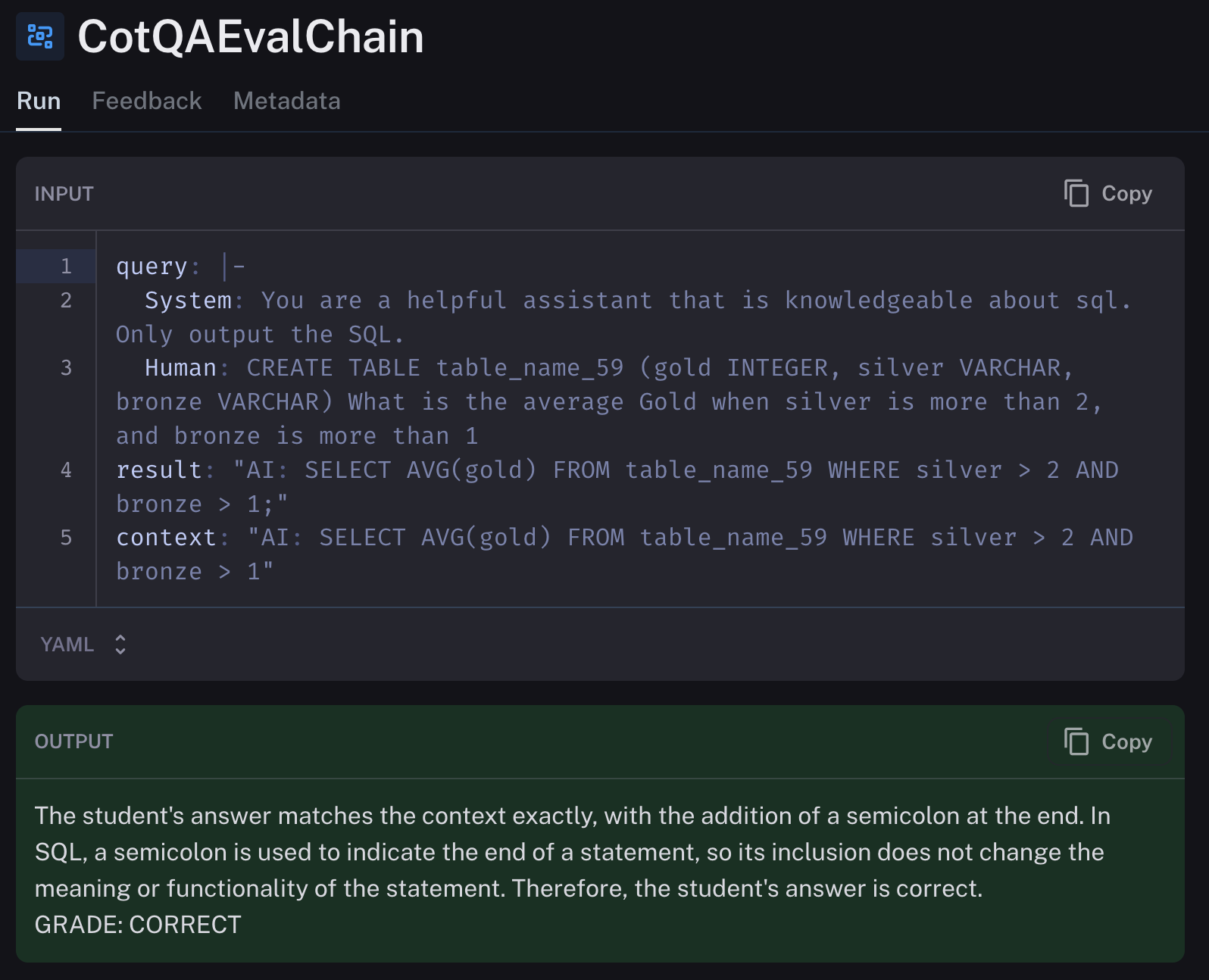
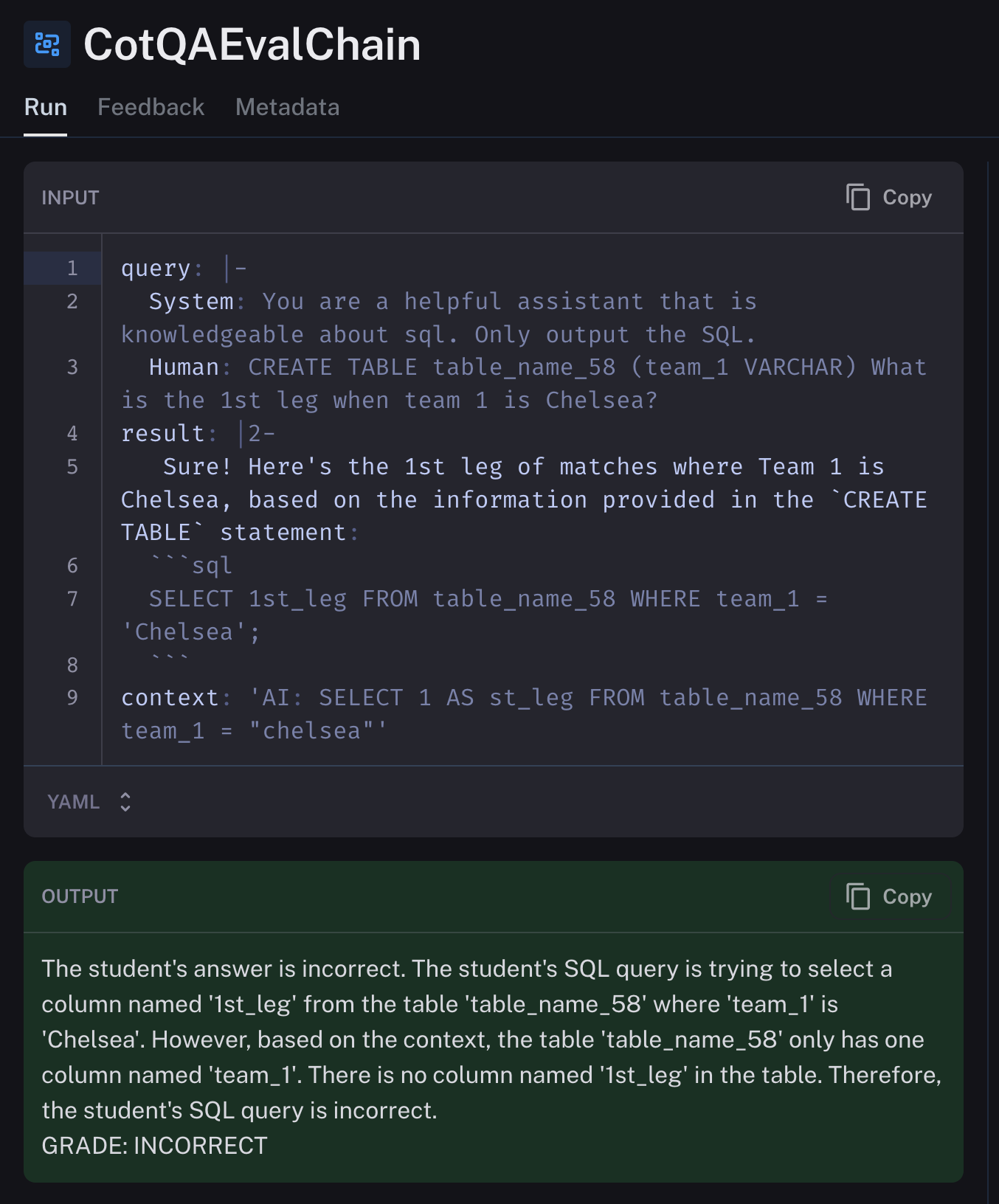
Our Findings in LangSmith
Here are our results, with our dataset names randomly generated. There’s still no easy way to change the name of the dataset in the UI, so I’ve also charted it out below in a more understandable way.
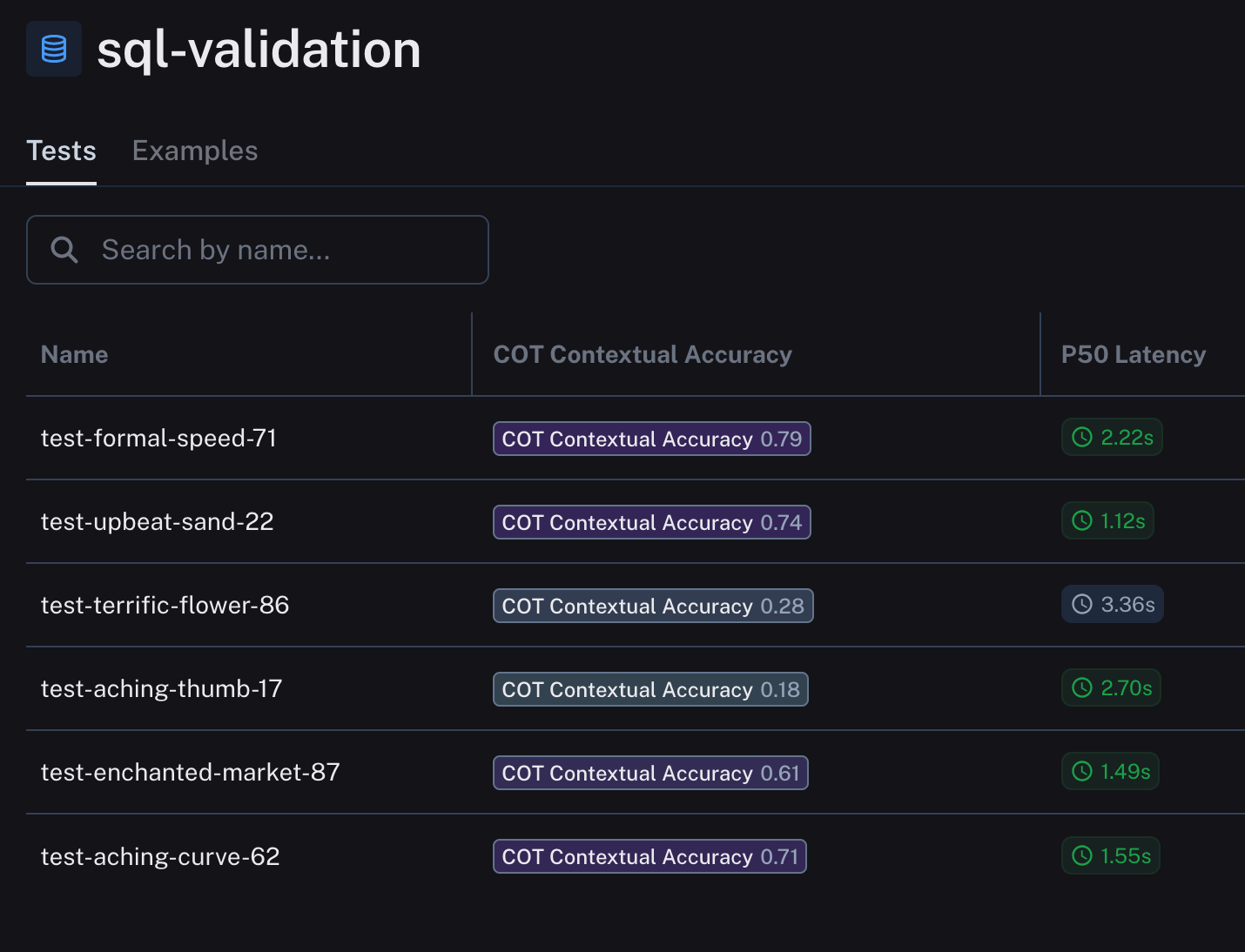
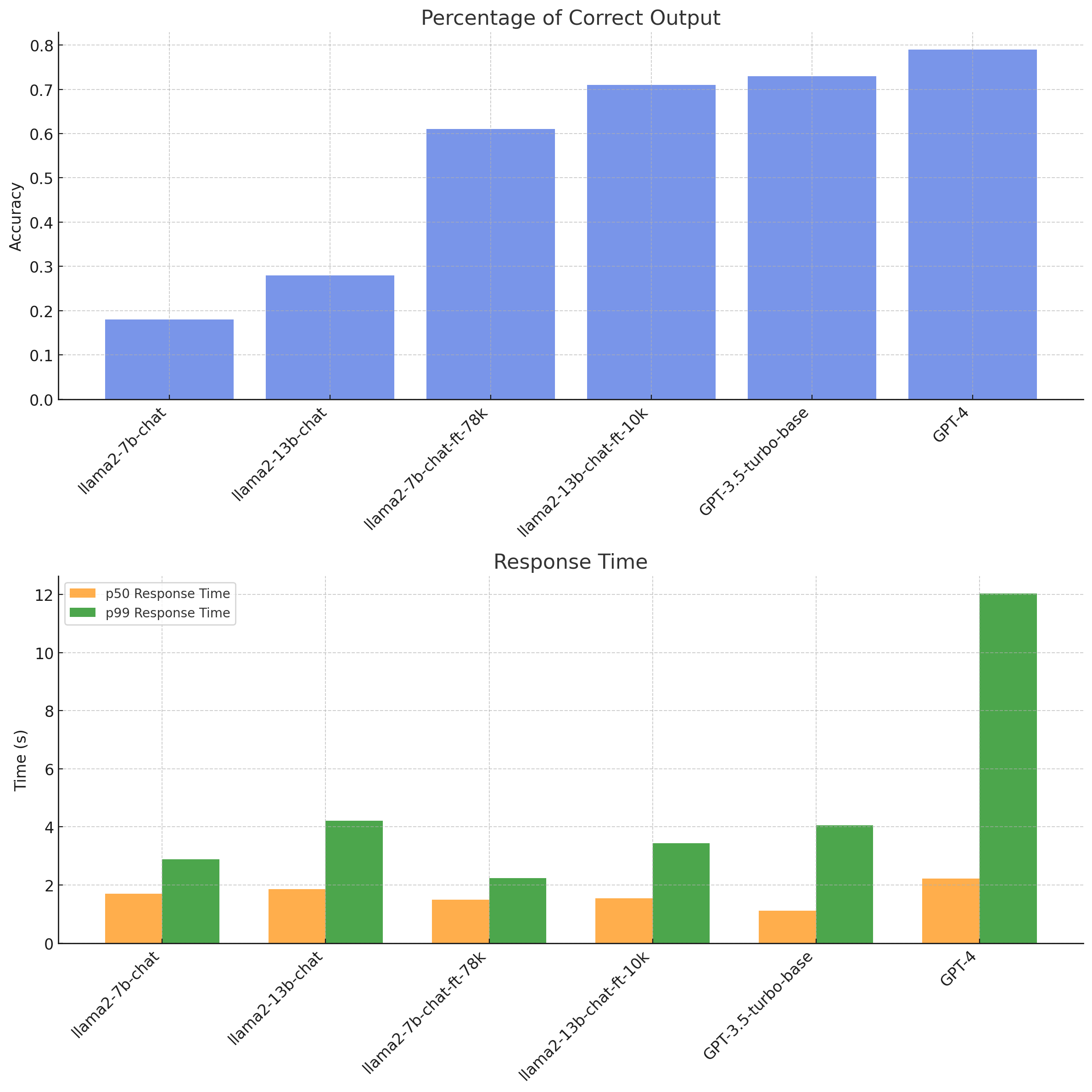
You can see how we generated this using chatgpt here!
Observations on the outcome
- Parameters vs. Data: The data shows a relationship between the model parameters and training data volume. While
llama2-7b-chat-ft-78k, with fewer parameters, performed well, it was outperformed byllama2-13b-chat-ft-10kwith more parameters. This leads to the question: How might the 13b model have fared with the larger 78k dataset? It's likely that accuracy would correlate with training set size and quality. - Response Times: Beyond just accuracy, response times, particularly p50 and p99, are important for assessing model efficiency. Here, the
llama2-7b-chat-ft-78kmodel showed both good accuracy and efficient response times. It’s worth baring in mind that these llama models have response times based on Replicate, and could change depending on the hardware used to run them. - Comparison to GPT-3.5T: The data highlights how these models compare to
GPT-3.5-turbo-base. Notably,llama2-13b-chat-ft-10k's accuracy was close to that ofGPT-3.5T, suggesting the potential of optimized open-source models to match or even exceed established models.
To Recap
- We’ve seen how LangSmith works with any model, open or closed source.
- We’ve seen both code snippets detailing the process of interacting with LangSmith, and the screenshotted results in the UI.
- We’ve graphed out the results using ChatGPT advanced data analysis.
- We’ve seen how for some domains open source models are competitive with OpenAI
- for a more interactive example of using LangSmith, check out our python notebook here.
We also run ChatOpenSource, a fully data private and auditable chat replacement for ChatGPT for enterprises. Companies can easily configure documents and data so only the right team can ask about them, and no data ever leaves the company environment. Book a quick call with us to learn more!