The goal of LangChain has always been to make it as easy as possible to develop context-aware reasoning applications with LLMs. LangChain started as a side project, and purely as a Python package. Over the past year it has grown tremendously. This growth has been a forcing function to rethink the architecture of the package. We’ve been listening to the community and are announcing a re-architecture of the package into multiple packages (done in a completely backwards compatible way), a path towards a stable 0.1 release, and also taking the opportunity to highlight the ecosystem that has emerged around LangChain.
TL;DR:
We've split the old langchain package into three separate packages to improve developer experience
langchain-core contains simple, core abstractions that have emerged as a standard, as well as LangChain Expression Language as a way to compose these components together. This package is now at version 0.1 and all breaking changes will be accompanied by a minor version bump.
langchain-community contains all third party integrations. We will work with partners on splitting key integrations out into standalone packages over the next month.
langchain contains higher-level and use-case specific chains, agents, and retrieval algorithms that are at the core of your application's cognitive architecture. We are targeting a launch of a stable 0.1 release for langchain in early January.
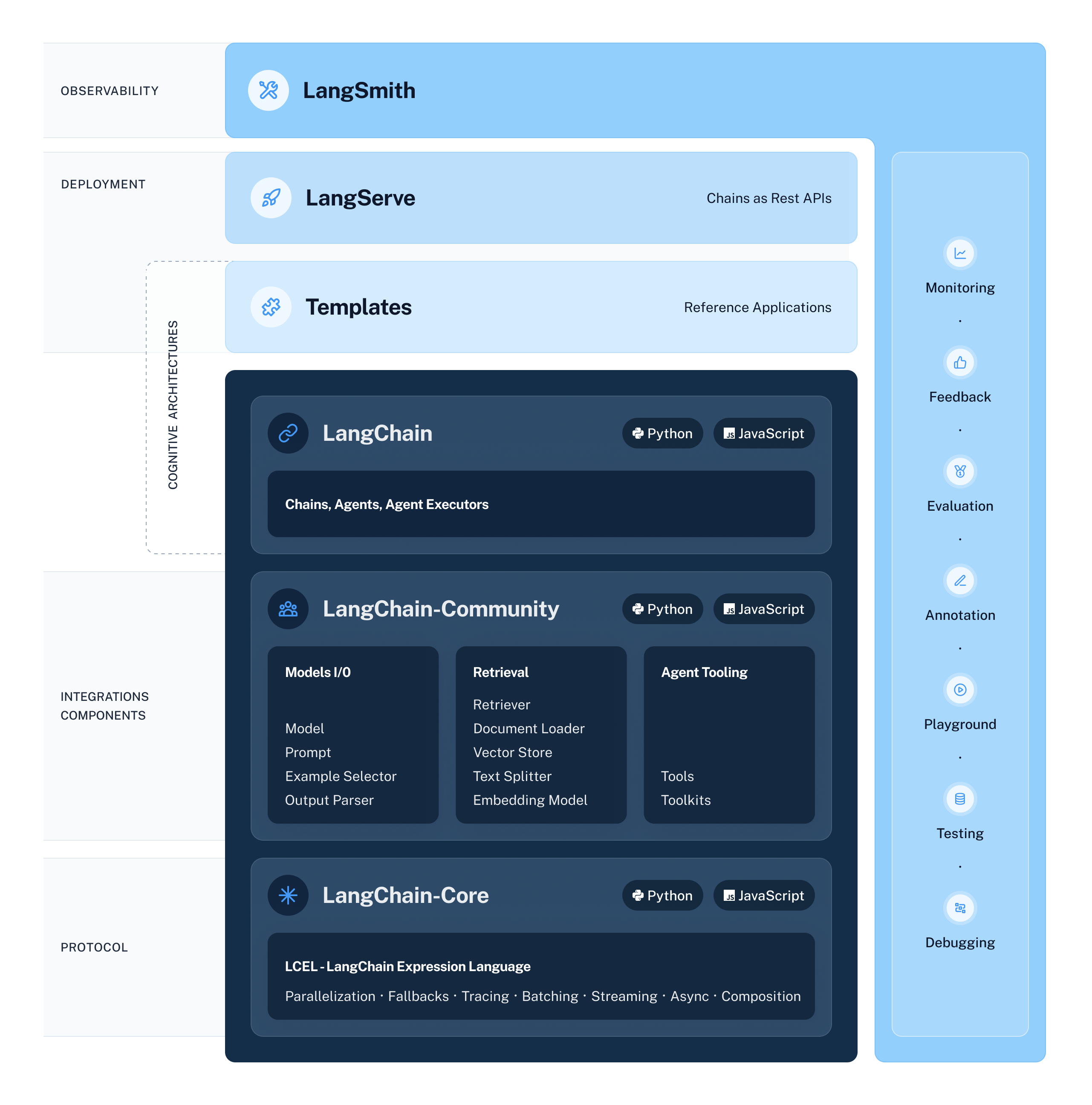
This is done to support a burgeoning ecosystem around langchain: LangChain Templates, LangServe, LangSmith, other packages built on top.
All done in a backwards compatible way.
The LangChain SDKs
The LangChain Python and JavaScript SDKs have three main parts:
- A base set of interfaces for common components needed in building LLM applications and a way to join those components together
- Integrations and/or implementations for those components
- Preconfigured ways to compose those components together to accomplish a particular use case
Previously, these three parts were all part of the same library. While this worked at the start, as the number of integrations and use cases has grown over time the complexity has become unsustainable. A main part of the re-architecture is to separate these out into distinct packages: langchain-core, langchain-community, and langchain. At the same time, we want to be conscious of the large LangChain user base and try to do so in a backwards compatible way.
LangChain Core
langchain-core consists of core abstractions and a runtime to join those components together (LangChain Expression Language).
Simple and Modular Abstractions
The base abstractions of LangChain are designed to be as modular and simple as possible. Examples of these abstractions include those for language models, document loaders, embedding models, vectorstores, retrievers, and more. The benefit of having these abstractions is that any provider can implement the required interface and then easily be used in the rest of LangChain.
These are NOT high level or end-to-end abstractions. They simply represent common interfaces for the necessary components. For example: LLMs are just text in, text out. Retrievers are text in, documents out.
Many frameworks AND applications are either built on top or are interoperable with these abstractions. This includes frameworks like funcchain, langchain-decorators, gpt-researcher, gpt-engineer, llama-index, pandas-ai, and CrewAI. Having a LangChain integration is the most effective way to make sure your tool is compatible with a large part of the ecosystem. In addition, over 30k applications are built on top of LangChain. Some of these need to implement custom components. By making our abstractions simple and modular we have made this easy and painless to do.
LangChain Expression Language
The initial LangChain release didn’t really have a common way to join these fundamental components together. Although the tagline was “building LLM applications through composability”, the original LangChain was actually not that composable.
This runtime allows users to compose arbitrary sequences together and get several benefits that are important when building LLM applications. We call these sequences “runnables”.
All runnables expose the same interface with single, batch, streaming and async methods. This design is useful because when building an LLM application it is not enough to have a single sync interface. Batch is needed for efficient processing of many inputs. Streaming (and streaming of intermediate steps) is needed to show the user that progress is being made. Async interfaces are nice when moving into production. Rather than having to write multiple implementations for all of those, LangChain Expression Language allows you to write a runnable once and invoke it in many different ways.
We have also written runnables to do orchestration of common (but annoying) tasks. All runnables expose a .map method, which applies that runnable to all elements of a list in parallel. All runnables also expose a .with_fallbacks method that allows you to define fallbacks in case the runnable errors. These are orchestration tasks that are common and helpful when building LLM applications.
These runnables are also far more inspectable and customizable than previous “chains”. Previous chains were largely custom classes in the langchain source code. This made it very difficult to understand what was happening inside them (including what prompts were used) and even more difficult to change the behavior of the change (without completely rewriting them). We’ve rewritten several chains (and will rewrite more in the future) using runnables. Runnables are defined in a declarative way, which makes it easier to understand the logic and modify parts.
Finally, runnables have best-in-class observability through a seamless integration with LangSmith. LLM applications are incredibly tricky to debug. Understanding what the exact sequence of steps is, what exactly the inputs are, and what exactly the outputs are can greatly increase your prompt velocity. We built LangSmith to greatly facilitate that - more on that later.
Benefits of separate package
These abstractions and runtime are pretty stable, and whenever we do make changes, we have largely done so in a backwards compatible way. Still, because these are so crucial to the LangChain ecosystem we want to be especially careful and communicative around changes to these abstractions. As of today these abstractions are part of langchain-core which just released a 0.1 version. Now that langchain-core is 0.1, any future breaking changes will be accompanied by a minor version bump. This creates stability for these core abstractions which will allow others to have confidence in building on top of them.
LangChain Community
A huge part of LangChain is our partners. We have nearly 700 integrations, from document loaders to LLMs to vectorstores to toolkits. In all cases, we have strived to make it as easy to add integrations as possible, and thank the community and our partners for working with us.
As empowering for developers as this large selection of integrations is, it does not come without its downsides. With so many integrations we’ve made all dependencies optional (to make LangChain lightweight). This unfortunately makes it confusing to know which dependencies are needed for a given integration. Having so many integrations in the same package also makes it next to impossible to properly version them. The underlying integrations are themselves changing at a rapid rate (a necessary reality given the rate-of-change of the field). This has contributed to instability for these integrations, as it’s hard to know when one may have changed. Since these integrations were bundled in with other parts of LangChain, they contributed to instability of the overall package. With so many integrations, there is naturally a wide spectrum of reliability and robustness of these integrations. If they are all in one package there is no way for developers to reliably know which integrations are well-supported and well-tested.
We’re excited to announce some changes to the architecture of LangChain that will address these issues.
First, in the recent release we have moved all integrations into a separate langchain-community package. This will help separate and distinguish integration code - which often requires different setup, different testing practices, and different maintenance. Again, this is done in a completely backwards compatible way.
Integration-Specific Packages
Over the next few weeks we will work on splitting out integrations with some of the largest audiences and most critical functionalities. These will exist in standalone packages for their particular integration. For example: langchain-openai, langchain-anthropic, etc. These packages will either live inside the LangChain monorepo or in their own individual repositories (depending on the desire of the integration partner). This will provide several benefits. It will let us version these packages by themselves, and if breaking changes are made they can be reflected by appropriate version bumps. It will simplify the testing process, increasing test coverage for these key integrations. It will let us make third party dependencies required for these packages, making installation easier. For packages that are split out into their own repo, it will let other companies own their integration.
LangChain
Remaining in the langchain package will be chains, agents, advanced retrieval methods, and other generalizable orchestration pieces that make up an application’s cognitive architecture.
Some of these will be the old legacy Chains - like ConversationalRetrievalChain, which is one of our most popular chains for doing retrieval augmented generation. We will continue to support and maintain these types of chains. More and more though, we will move towards chains constructed with LangChain Expression Language.
We are defaulting to LangChain Expression Language for many of the reasons listed in the previous section. Top of mind are ease of creating new chains, transparency of what steps are involved, ease of editing those steps, and ease of exposure of streaming, batch, and async interfaces.
Over the past few months we've largely been focused on getting LangChain Expression Language and langchain-core in a solid spot. Now that we believe that to be the case, we will increase the focus on higher level abstractions and chains (all powered by LangChain Expression Language).
Example
Let's take a look at what this looks like in practice! To do so, we can look at a recently added template for responding to emails. Let's look at the imports and see what we're importing from each package:
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.tools import toolFrom langchain_core we are importing a few things. First, we are importing message types like AIMessage and HumanMessage that we will use to abstract away how different model providers deal with these objects. Next, will import ChatPromptTemplate and MessagesPlaceholder. These are a way to encapsulate the logic required to take the user input and produce a list of messages to pass to the chat model. Finally, we will import tool. This is a decorator we can put on any function to automatically turn it into a LangChain tool object. All of these objects are core to working with LangChain.
from langchain_community.chat_models import ChatOpenAI
from langchain_community.tools.gmail import (
GmailCreateDraft,
GmailGetMessage,
GmailGetThread,
GmailSearch,
GmailSendMessage,
)From langchain_community we are importing third party integrations. First, with OpenAI - we will be using their chat model. Next, we import a bunch of tools for working with Gmail. These are specific instantiations of base LangChain abstractions (ChatModel and Tool, respectively).
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.tools.render import format_tool_to_openai_functionFrom langchain we import a few things. First, we import AgentExecutor. This is a specific cognitive architecture to run agents and tools. Next, we import utils for working with a particular type of agent (one that uses OpenAI Functions). This includes (a) logic to format the agent_scratchpad (intermediate steps an agent may take) to messages to pass to the chat model, (b) an output parser to parse the output of the LLM into an agent action, and (c) a function to convert the list of tools into a format that OpenAI functions expects.
Previously, all of these were imported from the same langchain package, even though they represent three different types of imports (base logic, third party integrations, and cognitive architectures). Part of the value of splitting up langchain is to make it more clear how to think of each type of module.
Parity of Python and JS
We've gotten a lot of questions about the Python and JS packages and how they relate to each other. Splitting the packages in this way (langchain-core, langchain-community, and langchain) can explain our philosophy around that.
langchain-core is very close to feature parity between the two languages already. Keeping the Python and JavaScript packages at feature parity is a priority for us. We are working on a serializable syntax (which we are already using in some places); maintaining cross-language support for core functionality is very important.
With regards to integrations in langchain-community (and their own packages), most of these will be at the discretion of either language, and it's not expected that all will be ported over. There are a few key ones (mainly LLM providers at the moment) that we are interested in achieving feature parity for.
langchain is somewhere in the middle - it's not nearly as close to feature parity as langchain-core is, but it's more of a goal to get it there than langchain-community.
LangChain Experimental
langchain-experimental will remain as a place to put more experimental tools, chains, and agents. “Experimental” can mean several things. Currently most of the implementations in langchain-experimental are either (1) newer and more more “out-there” ideas that we want to encourage people to use and play around with but aren’t sure if they are the proper abstractions, or (2) potentially risky and could introduce CVEs (Python REPL, writing and executing SQL). We separate these tools, chains, and agents to convey their experimental nature to end users.
LangChain Templates
We launched LangChain Templates two months ago as the easiest way to get started building a GenAI application. These are end-to-end applications that can be easily deployed with LangServe. These are distinct from chains and agents in the langchain library in a few ways.
First, they are not part of a Python library but are rather code that is downloaded and part of your application. This has a huge benefit in that they are easily modifiable. One of the main things that we observed over time is that as users would bring LangChain applications into production they had to do some customization of the chain or agent that they started from. At a minimum they had to edit the prompts used, and often they had to modify the internals of the chain, how data flowed through. By putting this logic (both the prompts and orchestration) as part of your application - rather than as part of a library's source code - it is MUCH more modifiable.
The second big difference is that these come pre-configured with various integrations. While chains and agents often require you pass in LLMs or VectorStores to make them work, templates come with those in place already. Since different LLMs may require different prompting strategies, and different vectorstores may have different parameters, this makes it possible for us to partner with integration partners to deliver templates that best take advantage of their particular tech.
LangServe
Three months ago we launched LangServe as the best way to deploy LangChain applications. LangServe is an open source Python library that essentially wraps FastAPI to automatically add in endpoints for your LangChain object. It automatically adds in multiple endpoints (streaming, batch) as well as automatically infers the inputs/outputs of those endpoints - all because we know the underlying LangChain object so well. This also allows us to automatically spin up simple UIs for these chains and agents. This makes it easy to expose a particular chain to end users to try out.
(We’re also working on a hosted version of LangServe, allowing for 1-click deploys of LangChain apps - sign up for the waitlist here)
LangSmith
The final piece of the LangChain ecosystem is LangSmith - the control center for your LLM applications.
LangSmith comes in handy with a best-in-class debugging experience. By logging all steps of chains and agents, you can easily:
- See exactly what steps were taken and in what order
- See what the exact inputs to those steps were
- See what the exact outputs of those steps were
- Enter in a playground for a given step where you can modify the inputs and see how that changes the output
When you are building these complex chains and agents, where the main part is this non-deterministic language model, this type of observability is CRUCIAL. From the moment you get started building, LangSmith will massively increase your iteration speed.
LangSmith also contains a suite of additional tools aimed at taking your application from prototype to production. This includes:
- Feedback collection – important to understand how users are interacting with your product
- Datasets and testing – see our recent work on evaluations that uses this
- Monitoring – usage, feedback scores, latency, tokens
- Data annotation queue – for labeling data quickly
- Hub – for collaborating on prompts
For more information on all these features, check out the YouTube highlight series we recently released.
Roadmap
We have been thinking about, working on, and discussing this roadmap for a little over a month now. Below is summary of what steps we’ve taken, and what remains to come:
[11/8 - DONE] Split out langchain-core
[12/11 - DONE] Split out all integrations into langchain-community, release langchain-core v0.1
[12/11-1/5] Split out main integrations into standalone packages
[1/9] Release langchain v0.1
The langchain v0.1 release is expected to be fully compatible with what exists today. The reason we are not releasing 0.1 today is we know there a few more features we want to add, and we also want to evaluate whether some of the logic in langchain makes sense to move into langchain-core.
What this enables
The main thing this enables is a flourishing GenAI ecosystem. There are a seemingly infinite number of use cases of LLMs. What we need is more exploration and optimizations of those use cases, and less worrying about having to support streaming, multiple models, tracing, etc.
This architecture of the package more strongly paves the way for not just applications but also other libraries and frameworks to be built on top of or integrate with LangChain. We’re already seeing this happen with frameworks like GPT Researcher, CrewAI, LlamaIndex, PandasAI, and many more.
This also paves the way for integration partners to more fully own not only their integration but also the framework around their integration. A great example of this is the Datastax team with their RAGStack framework. This builds on top of LangChain but focuses on (1) a best-in-class AstraDB and CassandraDB integration, and (2) more opinionated takes on what works best with CassandraDB. This allows Datastax to provide the best possible experience for users of their software, but also seamlessly integrate with the rest of the LangChain ecosystem so they don’t have to reinvent LLM integrations, document loaders, tracing, etc.
Conclusion
The main thing we believe about the GenAI space is that it is still super early and super fast changing. As the space evolves, so will the whole LangChain ecosystem. LangChain is nothing like it was a year ago, or even three months ago. We believe the recent changes and introduction of langchain-core and langchain-community are crucial for setting a solid foundation to propel us all forward. We look forward to seeing what you build 🙂
FAQs
Q: Which package should I start with?
A: If you are looking to get started from scratch, LangChain is probably still the best one to start with. It uses langchain-core and langchain-community under the hood, so exposes the largest collection of functionality.
Q: Are there compatibility considerations amongst the three packages or are versions interoperable?
A: Right now, we have the current version of LangChain depending on langchain-core>=0.1,<0.2.
Q: What will happen to LangChain's chains and agents e.g. ConversationalRetrievalQA chain?
A: They are sticking around as an easy way to get started with particular use cases! We’ll be transitioning more and more of them use LCEL under the hood (or creating LCEL equivalents) to gain the benefits of LCEL, but these higher level interfaces will always be there (and are a focus of ours over the next month).
Q: Which version should I upgrade to?
A: langchain>=0.0.350 has all the updates!
Q: Do I need to upgrade?
A: You don't NEED to! All these changes were done in a backwards compatible way, so you can safely ignore should you choose.
Q: I'm a contributor to a LangChain integration and would like to create a separate package. How can I do so?
A: We will be adding instructions and a CLI to help with that over the next few days - keep an eye on the GitHub discussions for that.