This is a guest blog post written by Sam and Connor at Unify. Unify is reinventing how go-to-market teams work using generative AI. As part of this transformation, they are launching a new agents feature today (powered by LangGraph and LangSmith). We had the pleasure of learning more about the engineering journey taken to launch this feature, and thought it would be a great story to share.
Agents are a new feature we’re launching alongside a broader automation suite we call Plays. Agents are effectively research tools—they can research companies or people by searching the web, visiting websites, navigating between pages, and performing standard LLM synthesis and reasoning to answer questions.
For the initial launch, the target use case of Agents is account qualification, which is the task of deciding whether a company fits your ideal customer profile to sell to or not. Given a company and a set of questions and criteria, the agent performs some research and decides whether they are “qualified” or not.
Example Research Questions
Here are some examples of qualification questions different users might ask the agent to research and qualify based on:
- An HR software company ⇒
- Are there any HR job postings on this company’s careers page?
- Do any of the job postings for HR roles mention a competitor’s software?
- An AI infra company ⇒
- Does this company mention using LLMs anywhere on their website?
- Are any of the company’s open ML roles looking for experience with transformer models for language or audio?
- Does the website or any job postings mention open source LLMs?
Agent v0
We used LangGraph as the framework for the agent state machine and LangSmith as the experimentation and tracing framework. Our starting point was a trivial agent that was about as barebones as you can imagine (not even a prompt):
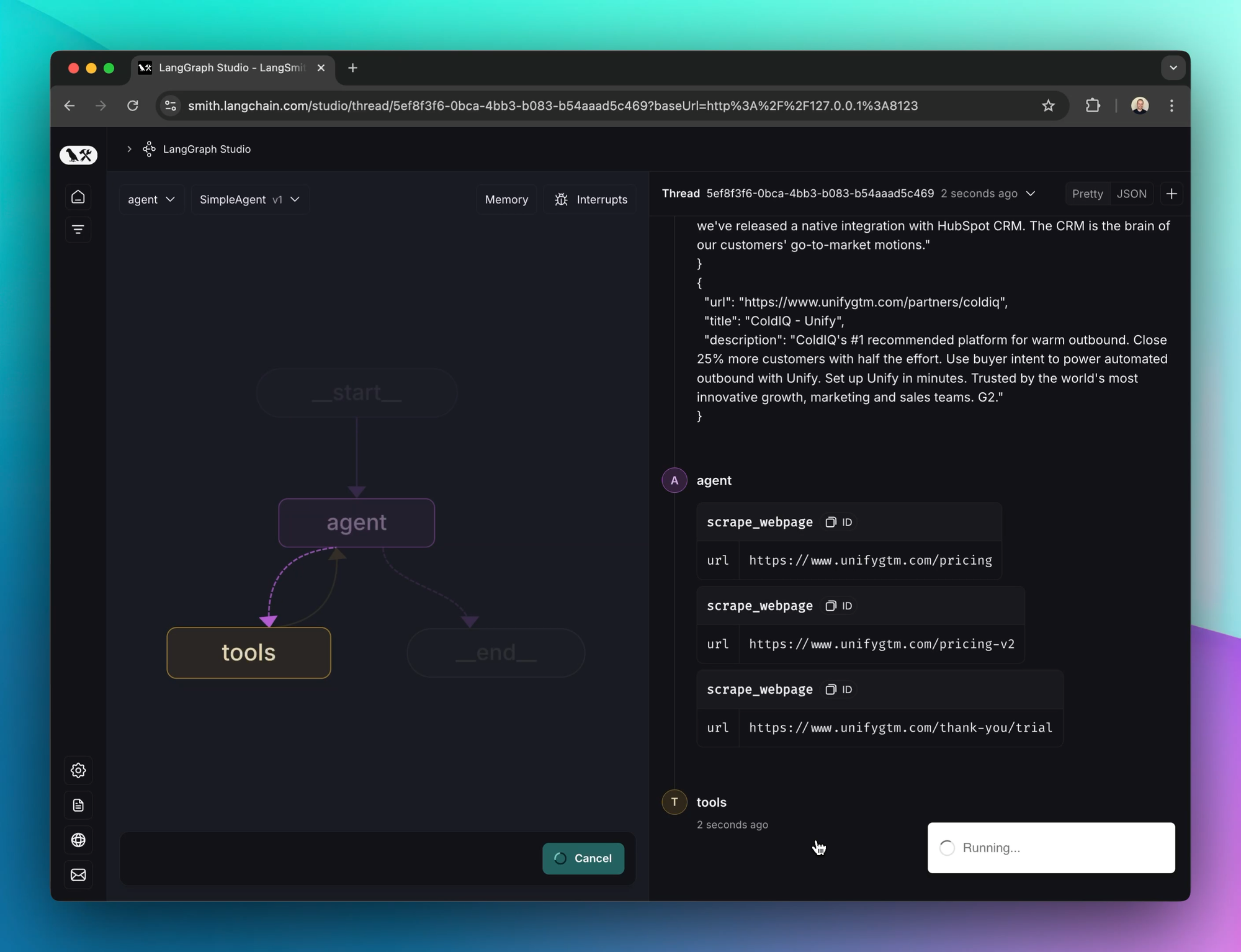
This actually worked reasonably well for a lot of simple tasks, but it also gets things wrong and produces inconsistent results. It was also difficult to analyze the reasoning behind answers.
Agent v1
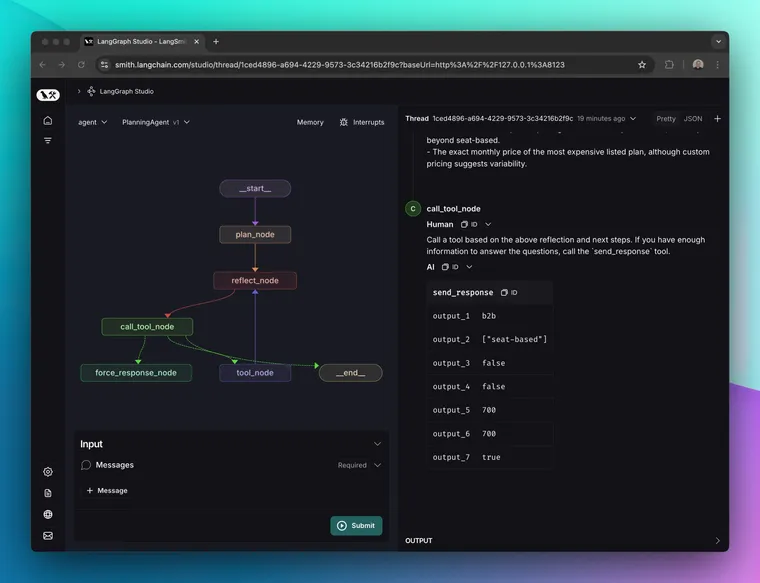
Our next iteration was to build out a more complex agent structure with an initial plan step and a reflect step. The graph looks like this:
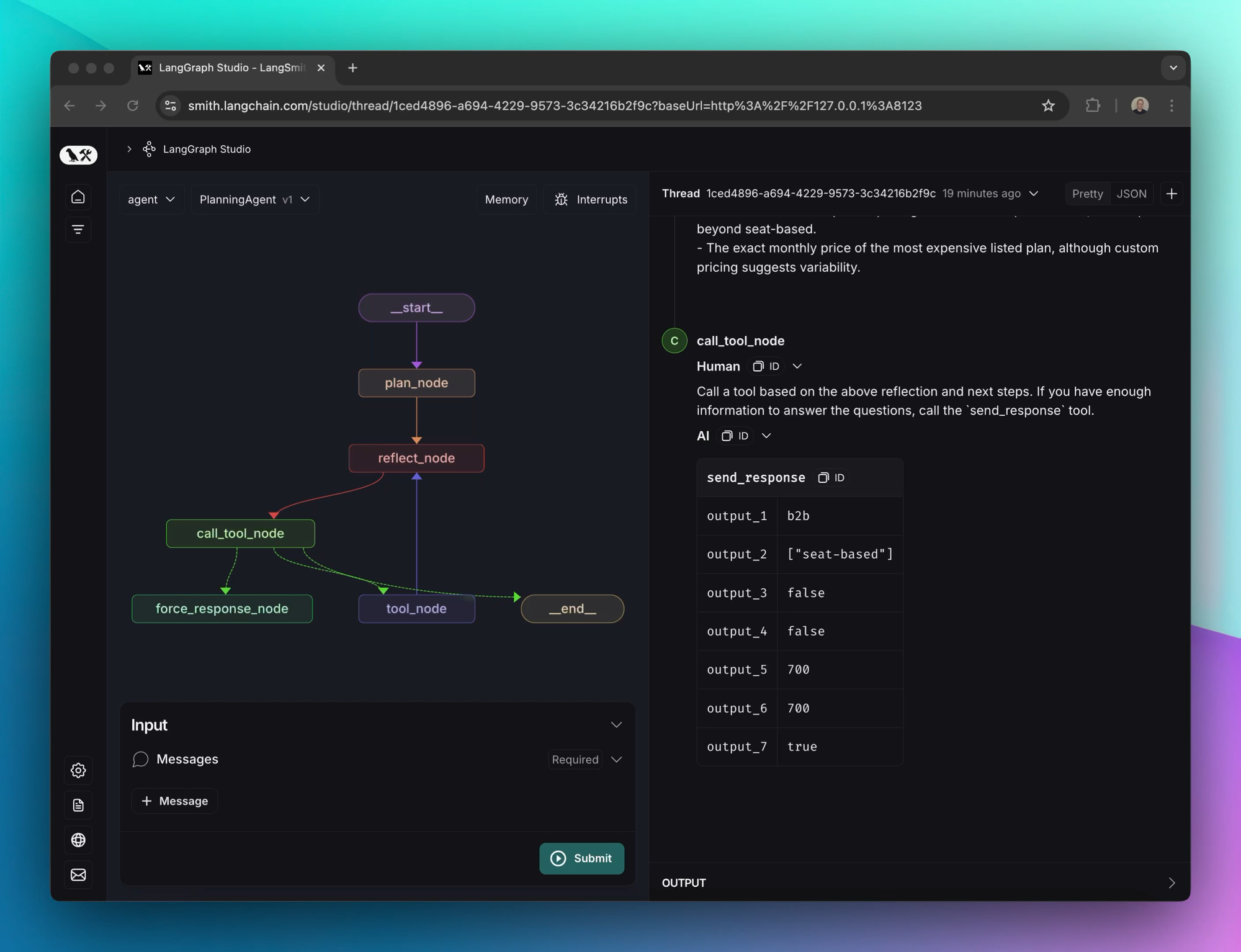
The first step involves using a large model to generate a plan. In our testing, mainline models like gpt-4o did not construct particularly comprehensive plans without very specific prompting. The best results we obtained at this stage were with OpenAI’s o1-preview model. The plans generated by o1 stood out as being difficult to replicate with other models because they had:
- Very detailed step-by-step instructions
- Potential pitfalls and mistakes to avoid that are correct and useful
- Expansions of what the user’s questions are asking, even when phrased poorly
The main downside of o1 is its speed. It can take up to 30-45 seconds to respond, which significantly slows down the overall agent run. An active area of experimentation for us is replicating equivalent results with faster, lighter models.
After planning, the agent then begins looping between a “reflect” step and tool calling. For this, we experimented with several models. The “mainline” models like GPT-4o and 3.5 Sonnet work fairly well. One of the most important characteristics of the reflection model is honesty about what it does not yet know in order to appropriately choose the right next steps.
Agent v2
We’re still using the plan-reflect-tools state machine structure for our latest iteration. The areas we’ve been most actively tuning and experimenting with are speed and user experience.
Speed
The main downside of this architecture (especially when using heavier planning models like o1-preview) is that it increases the overall runtime substantially. We’ve found ways to deal with this by both speeding up the agent loop and by revising the UI/UX around using agents in our product.
One of the biggest speed boosts we achieved came from parallelizing tool calls. For example, we allowed the model to scrape multiple web pages at a time. This helps a lot since each webpage can take several seconds to load. It works well intuitively because humans often do the same thing—quickly opening multiple Google results at once in new tabs.
User Experience
There’s ultimately a limit on how fast agents can be made without sacrificing accuracy and capabilities. We instead decided to rework the UI for building and testing agents in our product. The initial designs showed a spinner to the user while the agent ran (which gets pretty painful after a few seconds). Our updated interface instead shows the actions and decision-making process of the agent as it runs in real time. (See video at the top of this article)
Pulling this off also required some engineering changes. We originally had a simple prediction endpoint that would hold a request open while the agent ran. To deal with longer agent runtimes and accomplish the new step-by-step UI, we converted this to an “async” endpoint that starts the agent execution and returns an ID that can be used to poll for progress. We added hooks into the agent graph and tools to “log” progress to our database. The frontend then polls for updates and displays newly completed steps as they are executed until the final result is obtained.
Final Learnings
Embrace Experimentation
Working with agents definitely required figuring new things out. The research space is super green at the moment and there’s no definitive SOTA agent architectures yet in the way we think of SOTA in other domains like vision or audio.
Given this, we have to lean heavily into good old fashioned ML experimentation and evaluation cycles to make substantive progress.
We’ve been really happy with LangSmith for this (we were also already using LangSmith for Smart Snippets, another LLM-powered feature in Unify). In particular, versioned datasets are exactly what we were hoping they would be. Running and comparing experiments is straightforward, and the tracing is also excellent. We’re able to run a new agent version on hundreds of examples and quickly compare it against previous versions on a given dataset with very little in house ML infra work.
Think of agents as summer interns
For example, many tools with agent building functionality have a UX that revolves around writing a prompt, running it on some test cases, waiting for a black box agent to run, inspecting the results, and then guessing at how to modify the prompt to try and improve it.
Now imagine the agent was instead a summer intern prone to oversights and mistakes. If you give the intern a task and they come back with the wrong answer, would you simply try to revise your instructions and then send them off on their own again? No — you would ask them to show how they accomplished the task so that you can identify what they’re doing wrong. Once you spot their mistake, it’s much easier to adjust your instructions to prevent the mistake from happening again.
Bringing it back to agents, the UX we ended up at is one where users can clearly see what the agent is doing step-by-step to analyze its decision-making and figure out what additional guidance they need to provide.
o1-preview is a solid model, but very slow
Despite its slowness, OpenAI’s o1-preview model is a step up from other models we’ve experimented with for plan formation. It has a tendency to be verbose, but that verbosity is often valuable content rather than just filler or boilerplate. It consistently returns results that we aren’t able to reproduce with other models (yet), but with a painfully long wait. We were able to work around the slowness with UX improvements, but as we scale this system o1 will likely become a bottleneck.
Empower end users to experiment
The biggest challenge we see users face with LLM-powered features is figuring out how to iterate. Many users have little exposure to LLMs or prompting strategies. As a user, if I hit “generate” and the results are only partially right, what do I do next? How do I iterate in a way that makes progress without regressions in the examples that were already correct?
We see the intersection of UX and LLMs as ripe for disruption. While we’re excited about the UI we’ve developed so far, making it easier for users to experiment and correct agents’ mistakes will be one of our biggest focuses going forward.