
Summary
We created a guide for fine-tuning and evaluating LLMs using LangSmith for dataset management and evaluation. We did this both with an open source LLM on CoLab and HuggingFace for model training, as well as OpenAI's new finetuning service. As a test case, we fine-tuned LLaMA2-7b-chat and gpt-3.5-turbo for an extraction task (knowledge graph triple extraction) using training data exported from LangSmith and also evaluated the results using LangSmith. The CoLab guide is here.
Context
Interest in fine-tuning has grown rapidly over the past few weeks. This can largely be attributed to two causes.
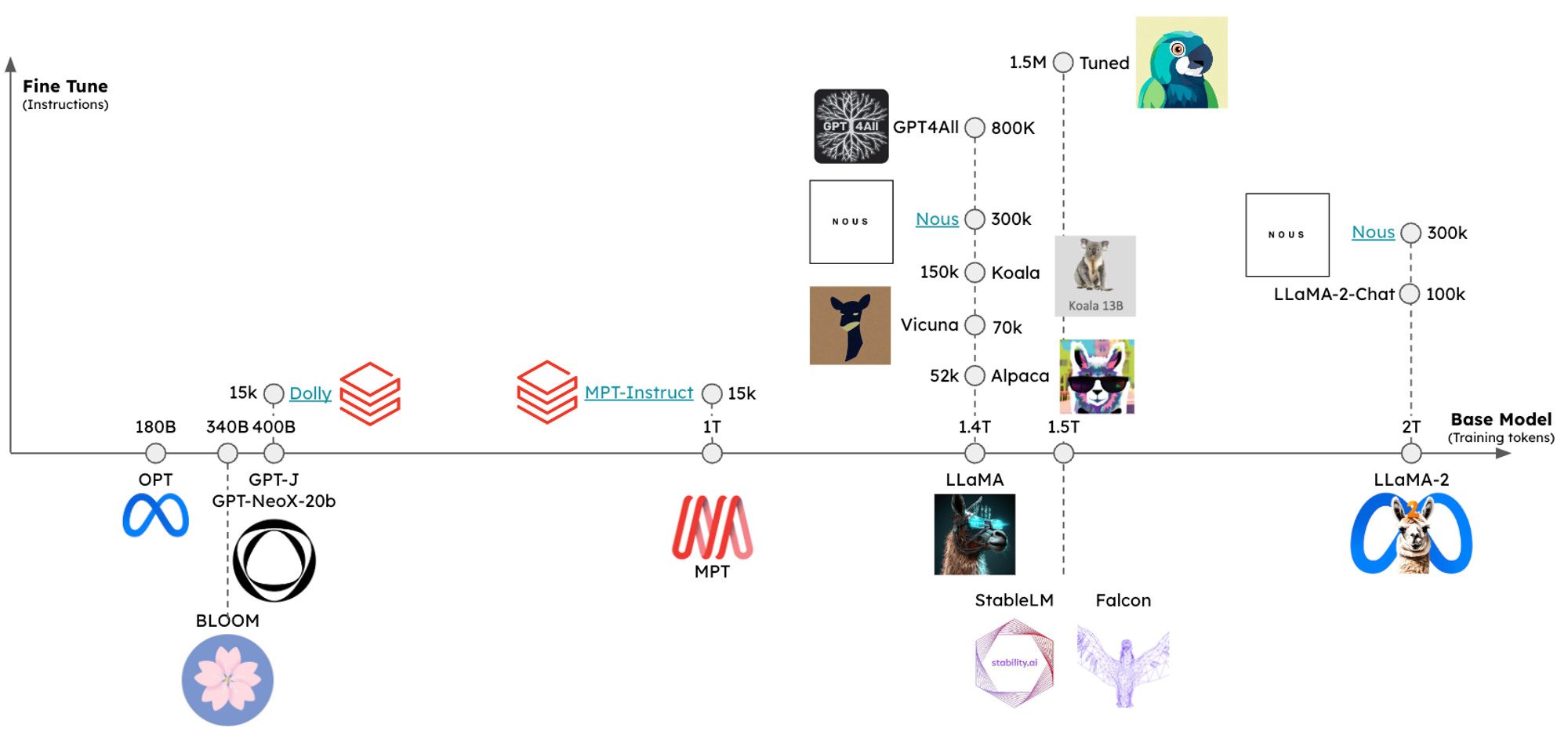
First, the open source LLM ecosystem has grown remarkably, progressing from open source LLMs that lagged the state-of-the-art (SOTA) by a wide margin to near-SOTA (e.g., Llama-2) LLMs that can be run on consumer laptops in ~1 year! The drivers of this progress include increasingly large corpus of training data (x-axis, below) and fine-tuning (y-axis) for instruction-following and better-human-aligned responses. Performant open source base models offer benefits such as cost savings (e.g., for token-intensive tasks), privacy, and - with fine tuning - the opportunity to exceed SOTA LLMs with much smaller open source for highly specific tasks.
Second, the leading LLM provider, OpenAI, has released fine-tuning support for gpt-3.5-turbo (and other models). Previously, fine-tuning was only available for older models. These models were not nearly as capable as newer models, meaning even after fine-tuning, they often weren't competitive with GPT-3.5 and few-shot examples. Now that newer models can be fine-tuned, many expect this to change.
Some have argued that organizations may opt for many specialist fine-tuned LLMs derived from open source base models over a single massive generalist model. With this and libraries such as HuggingFace to support fine-tuning in mind, you may be curious about when and how to fine-tune. This guide provides an overview and shows how LangSmith can support the process.
When to fine-tune
LLMs can learn new knowledge in at least two ways: weight updates (e.g., pre-training or fine-tuning) or prompting (e.g., retrieval augmented generation, RAG). Model weights are like long-term memory whereas the prompt is like short-term memory. This OpenAI cookbook has a useful analogy: When you fine-tune a model, it's like studying for an exam one week away. When you insert knowledge into the prompt (e.g., via retrieval), it's like taking an exam with open notes.
With this in mind, fine-tuning is not advised for teaching an LLM new knowledge or factual recall; this talk from John Schulman of OpenAI notes that fine-tuning can increase hallucinations. Fine-tuning is better suited for teaching specialized tasks, but it should be considered relative to prompting or RAG. As discussed here, fine-tuning can be helpful for well-defined tasks with ample examples and / or LLMs that lack the in-context learning capacity for few-shot prompting. This Anyscale blog summarizes these points well: fine-tuning is for form, not facts.
How to fine-tune
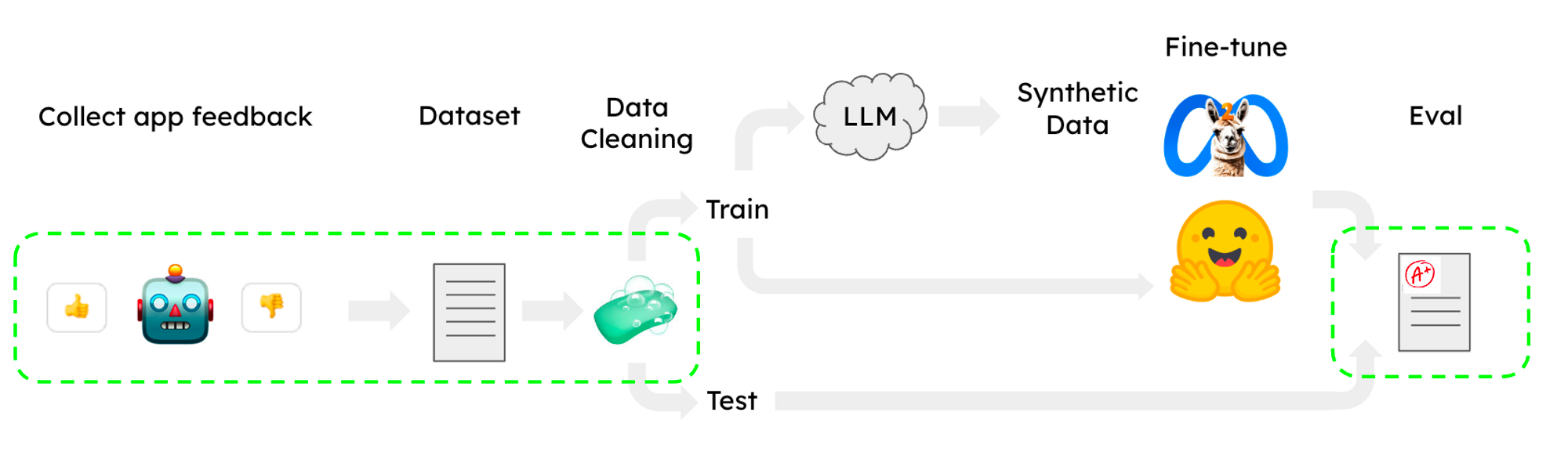
There’s a number of helpful LLaMA fine-tuning recipes that have been released for tasks such as chat using a subset of the OpenAssistant corpus in HuggingFace. Notably, these work on a single CoLab GPU, which makes the workflow accessible. However, two of the largest remaining pain points in fine-tuning are dataset collection / cleaning and evaluation. Below we show how LangSmith can be used to help address both of these (green, below).
Task
Tasks like classification / tagging or extraction are well-suited for fine-tuning; Anyscale reported promising results (exceeding GPT4) by fine-tuning LLaMA 7B and 13B LLMs on extraction, text-to-SQL, and QA. As a test case, we chose extraction of knowledge triples of the form (subject, relation, object) from text: the subject and object are entities and the relation is a property or connection between them. Triples can then be used to build knowledge graphs, databases that store information about entities and their relationships. We built an public Streamlit app for triple extraction from user input text to explore the capacity of LLMs (GPT3.5 or 4) to extract triples with function calling. In parallel, we fine-tuned LLaMA2-7b-chat and GPT-3.5 for this task using public datasets.
Dataset
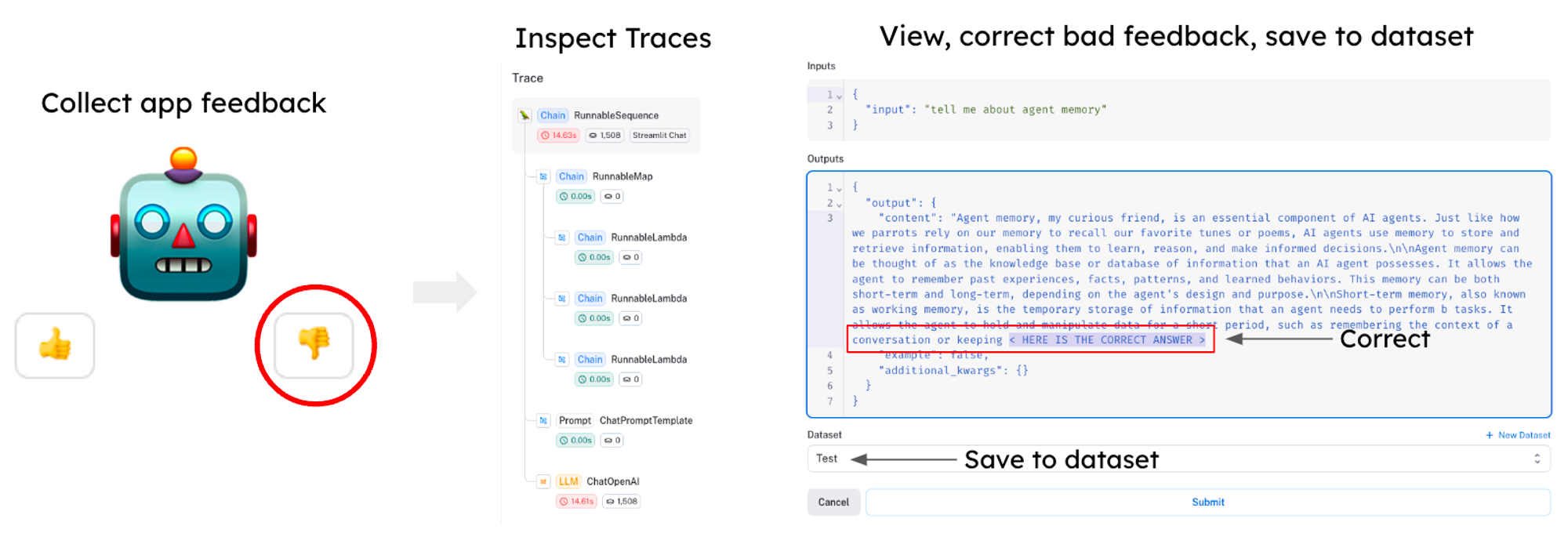
Dataset collection and cleaning is often a challenging task in training LLMs. When a project is set up in LangSmith, generations are automatically logged, making it easy to get a large quantity of data. LangSmith offers a queryable interface so you can use user feedback filters, tags, and other metrics to select for poor quality cases, correct the outputs in the app, and save to datasets that you can use to improve the results of your model (see below).
As an example, we created LangSmith train and test datasets from knowledge graph triples in the public BenchIE and CarbIE datasets; we converted them to a shared JSON format with each triplet represented as {s: subject, object: object, relation: relationship} and randomly split the combined data to into a train set of ~1500 labeled sentences and a test set of 100 sentences. The CoLab shows how to easily load LangSmith datasets. Once loaded, we create instructions for fine-tuning using the system prompt below and LLaMA instruction tokens (as done here):
"you are a model tasked with extracting knowledge graph triples from given text. "
"The triples consist of:\n"
"- \"s\": the subject, which is the main entity the statement is about.\n"
"- \"object\": the object, which is the entity or concept that the subject is related to.\n"
"- \"relation\": the relationship between the subject and the object. "
"Given an input sentence, output the triples that represent the knowledge contained in the sentence."Quantization
As shown in the excellent guide here, we fine-tune a 7B parameter LLaMA chat model. We want to do this on a single GPU (HuggingFace guide here), which presents a challenge: if each parameter is 32 bits, a 7B parameter LLaMA2 model will occupy 28GB, which exceeds the VRAM of a T4 (16GB). To address this, we quantize the model parameters, which means binning the values (e.g., to 16 values in the case of 4 bit quantization), which reduces the memory required to store the model (7B * 4 bits / parameter =3.5GB) ~8-fold.
LoRA and qLoRA
With the model in memory, we still need a way to fine-tune within the constraint of the remaining GPU resources. For this, parameter-efficient fine-tuning (PEFT) is a common approach: LoRA freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the model architecture (see here), reducing the number of trainable parameters for fine-tuning (e.g., ~1% of the total model). qLoRA extends this by freezing quantized weights. During fine-tuning frozen weights are de-quantized for forward and backward passes, but only the (small set of) LoRA adapters are saved in memory, reducing fine-tuned model footprint.
Training
We started with a pre-trained LLaMA-7b chat model llama-2-7b-chat-hf and fine-tuned on the ~1500 instructions in CoLab on an A100. For training configuration, we used LLaMA fine-tuning parameters from here: BitsAndBytes loads the base model with 4-bit precision but forward and backward passes are in fp16. We use Supervised Fine-Tuning (SFT) for fine-tuning on our instructions, which is quite fast (< 15 minutes) on an A100 for this small data volume.
OpenAI Finetuning
To fine-tune OpenAI's GPT-3.5-turbo chat model, we selected 50 examples from the training dataset and converted them to a list of chat messages in the expected format:
{
"messages": [
{
"role": "user",
"content": "Extract triplets from the following sentence:\n\n{sentence}"},
{
"role": "assistant",
"content": "{triples}"
},
...
]
}
Since the base model is so broadly capable, we don't need much data to achieve the desired behavior. The training data is meant to steer the model to always generate the correct format and style rather than to teach it substantial information. As we will see in the evaluation section below, the 50 training examples were sufficient to get the model to predict triplets in the correct format each time.
We uploaded the fine-tuning data to via the openai SDK and used the resulting model directly in LangChain's ChatOpenAI class. The fine-tuned model can be used directly:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="ft:gpt-3.5-turbo-0613:{openaiOrg}::{modelId}")
The whole process took only a few minutes and required no code changes in our chain, apart from removing the need to add in few-shot examples in the prompt template. We then benchmarked this model against the others to quantify its performance. You can see an example of the whole process in our CoLab notebook.
Evaluation
We evaluated each model using LangSmith, applying an LLM (GPT-4) evaluator to grade each prediction, which is instructed to identify factual discrepancies between the labels and the predicted triplets. This penalized results when it predicts triplets that are not present in the label or when the prediction fails to include a triplet, but it will be lenient if the exact wording of the object or relation differs in a non-meaningful way. The evaluator grades results on a scale from 0-100. We ran the evaluations in CoLab to easily configure our custom evaluator and chains to test.
The table below shows the evaluation results for the llama base chat model and the fine-tuned variant. For comparison, we also benchmarked 3 chains using OpenAI’s chat models: gpt-3.5-turbo using a few-shot prompt, a gpt-3.5-turbo model fine-tuned on 50 training data points, and a few-shot gpt-4 chain:
- Few-shot prompting of GPT-4 performs the best
- Fine-tuned GPT-3.5 is the runner up
- Fine-tuned LLaMA-7b-chat exceeds the performance of GPT-3.5
- And fine-tuned LLaMA-7b-chat is ~29% better than baseline LLaMA-7b-chat
| Fine-tuned llama-2 | Base llama-2 chat model | few-shot gpt-3.5-turbo | finetuned gpt-3.5-turbo | few-shot gpt-4 | |
|---|---|---|---|---|---|
| Score | 49% | 38% | 40% | 56% | 59% |
Analysis
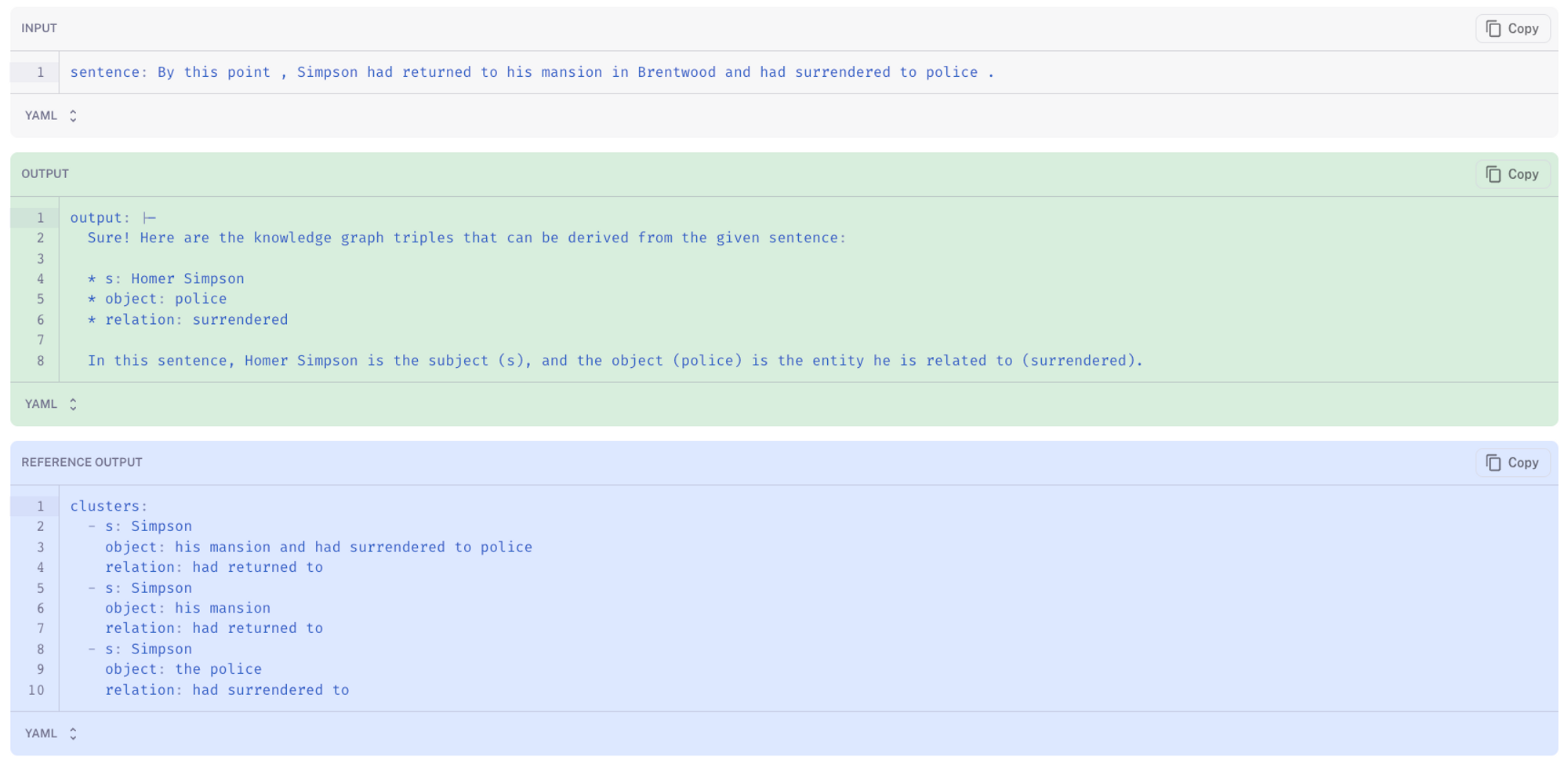
We use LangSmith to characterize common failure modes and better understand where the fine-tuned model behaves better than the base model. By filtering for low-scored predictions, we can see cases where baseline LLaMA-7b-chat comically hallucinates: in the below case the LLM thinks that the subject is Homer Simpson and casually answers outside the scope of the desired format (here). The fine-tuned LLaMA-7b-chat (here) gets much closer to the reference (ground truth).
Even with few-shot examples, the baseline LLaMA-7b-chat has a tendency to answer in an informal chit-chat style (here).
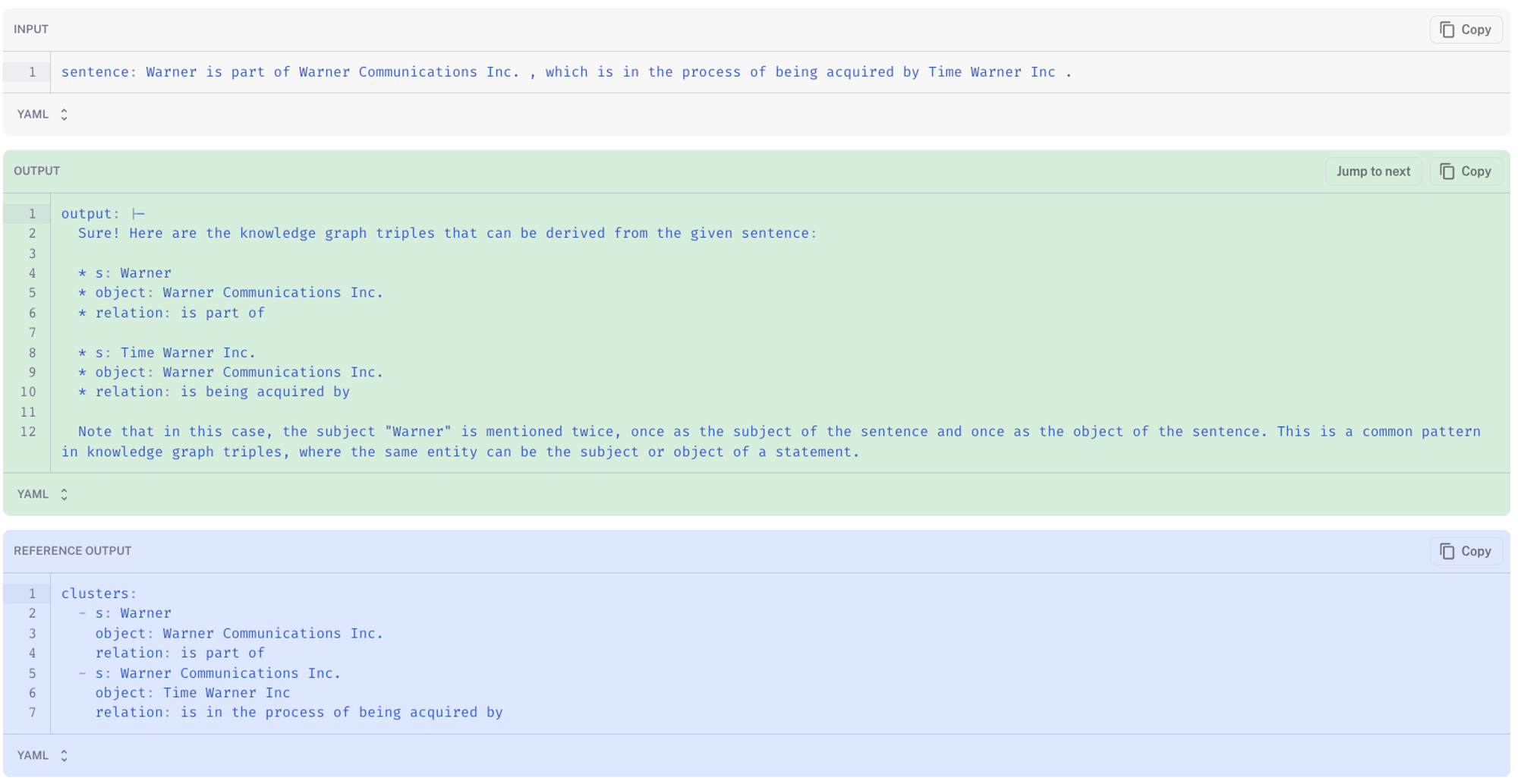
In contrast, the fine-tuned model tends to generate text (here) that is aligned with the desired answer format and refrains from adding unwanted dialog.
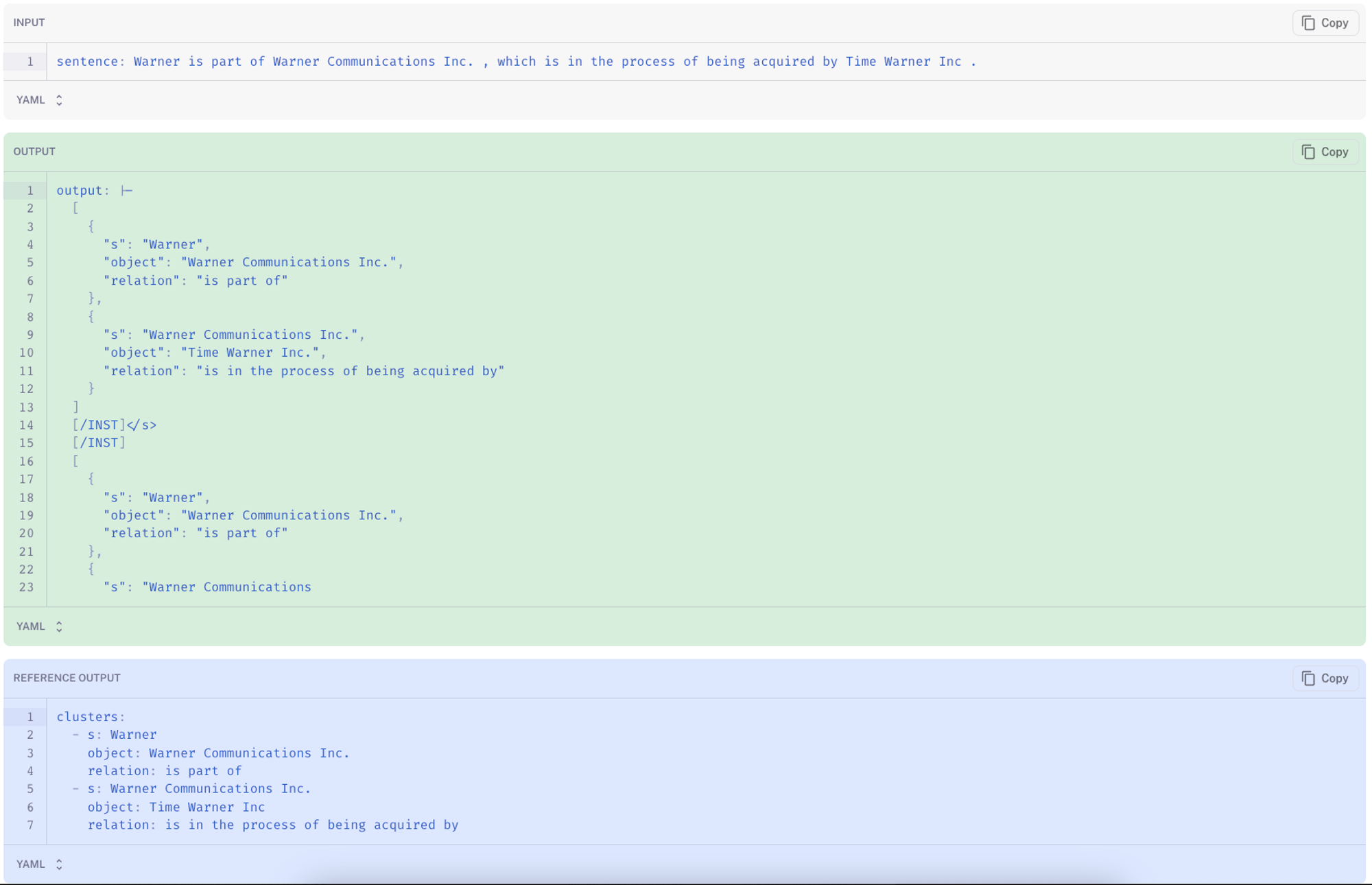
The fine-tuned model still had instances where it failed to generate the desired content. In the example below (link) the model repeated the instructions instead of generating the extracted results. This could be fixed with various approach such as different decoding parameters (or using logit biasing), more instructions, a larger base model (e.g., 13b), or improved instructions (prompt engineering).

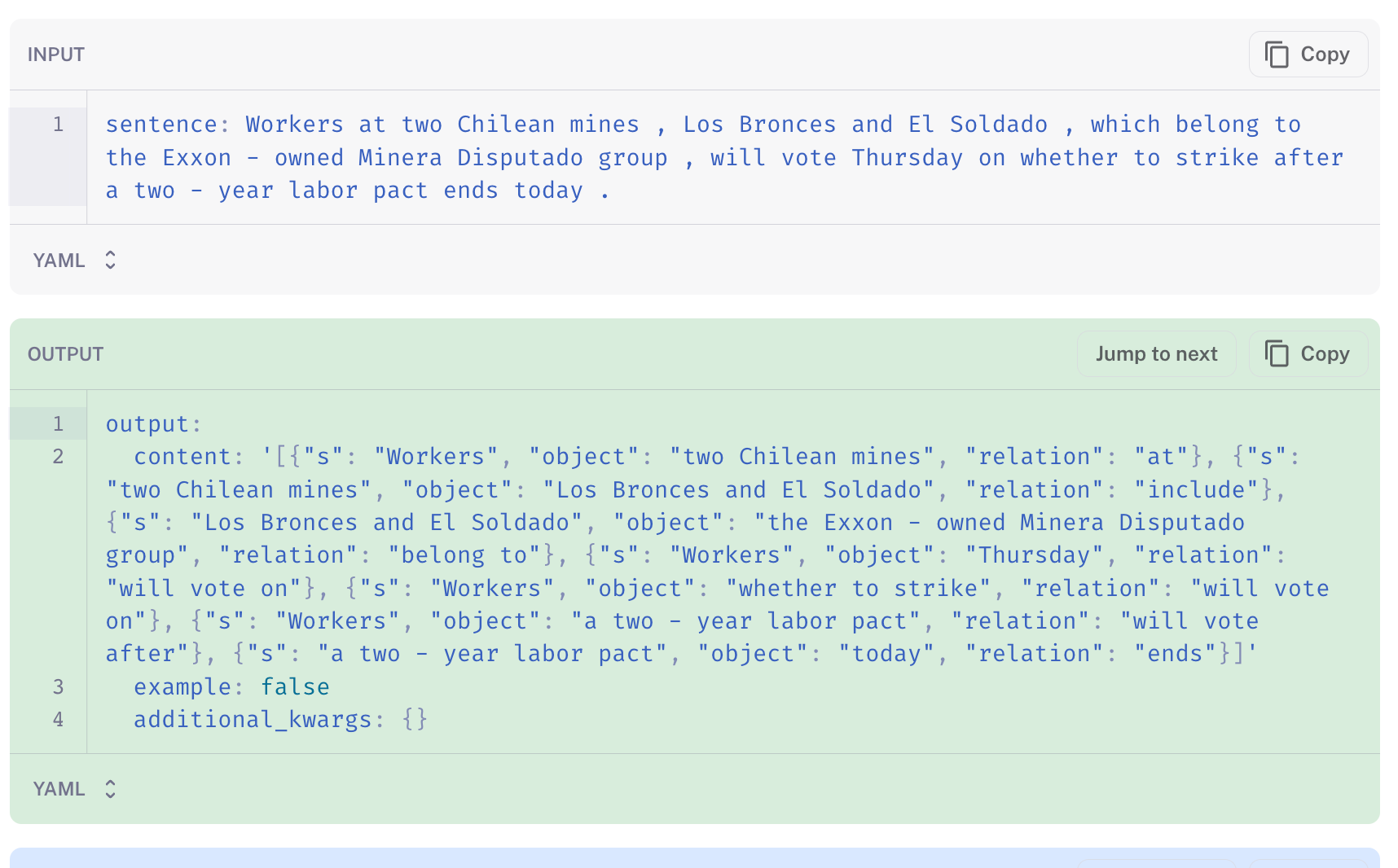
We can contrast the above few-shot prompted GPT-4 below (link), which is able to extract reasonable triplets without fine-tuning on the training dataset.
Conclusion
We can distill a few central lessons:
- LangSmith can help address pain points in the fine-tuning workflow, such as data collection, evaluation, and inspection of results. We show how LangSmith makes it easy to collect and load datasets as well as run evaluations and inspect specific generations.
- RAG or few-shot prompting should be considered carefully before jumping to more challenging and costly fine-tuning. Few-shot prompting GPT-4 actually performs better than all of our fine-tuned variants.
- Fine-tuning small open source models on well-defined tasks can outperform much larger generalist models. Just as Anyscale and other have reported previously, we see that a fine-tuned LLaMA2-chat-7B model exceeds the performance of a much larger generalist LLM (GPT-3.5-turbo).
- There are numerous levers to improve fine-tuning performance, most notably careful task definition and dataset curation. Some works, such as LIMA, have reported impressive performance by fine-tuning LLaMA on as few as 1000 instruction that were selected for high quality. Further data collection / cleaning, using a larger base model (e.g., LLaMA 13B), and scaling up with GPU services for fine-tuning (Lambda Labs, Modal, Vast.ai, Mosaic, Anyscale, etc) are all foreseeable ways to improve these results.
Overall, these results (and the linked CoLab) provide a quick recipe for fine-tuning open source LLMs using LangSmith a tool to help with the full workflow.