
At Sequoia’s AI Ascent conference in March, I talked about three limitations for agents: planning, UX, and memory. Check out that talk here. This is our second post on UX for agents, focused on ambient agents.
In our previous blog post on chat-based UX for agents, we discussed how chat requires users to proactively think about messaging an AI. But what if the AI could just work in the background for you?
I’d argue that in order for agentic systems to really reach their potential, this shift towards allowing AI to work in the background needs to happen. When tasks are handled in the background, users are generally more tolerant of longer completion times (as they relax expectations for low latency). This frees up the agent to do more work, often more carefully / diligently than in a chat UX.
Additionally, running agents in the background enables us humans to scale our capabilities more effectively. Chat interfaces typically limit us to one task at a time. But if agents are running ambiently in the background, there can be many agents handling multiple tasks simultaneously .
So, what would this background agent UX look like?
Building trust with background agents: Moving from “Human-in-the-loop” to “Human-on-the-loop”
It requires a certain level of trust to let an agent run in the background. How do you build this trust?
One straightforward idea is to just show users exactly what the agent is doing. Display all the steps it is taking, and let users observe what is happening. While this information may not be immediately visible (as it would be when streaming a response back), it should be available for users to click into and observe.
The next step is to not only let users see what is happening, but also let them correct the agent. If they see that the agent made an incorrect choice on step 4 of 10, they should be able to go back to step 4 and correct the agent in some way.
What does this correction look like? There are a few forms this can take. Let’s take a concrete example of correcting an agent that called a tool incorrectly:
- You could manually type out the correct tool invocation and make it as if the agent had outputted that, then resume from there
- You give the agent explicit instructions on how to call the tool better - e.g., “call it with argument X, not argument Y” - and ask the agent to update its prediction
- You could update the instructions or state of the agent at the point in time, and then rerun from that step onwards
The difference between options 2 and 3 lies in whether the agent is aware of its previous mistakes. In option 2, the agent is presented with its previous poor generation and asked to correct it, while in option 3, it does not know of its bad prediction (and simply follows updated instructions).
This approach moves the human from being “in-the-loop” to “on-the-loop”. “On-the-loop” requires the ability to show the user all intermediate steps the agent took, allowing the user to pause a workflow halfway through, provide feedback, and then let the agent continue.
One application that has implemented a UX similar to this is Devin, the AI software engineer. Devin runs for an extended period of time, but you can see all the steps taken, rewind to the state of development at a specific point in time, and issue corrections from there.
Integrating human input: How agents can ask for help when needed
Although the agent may be running in the background, that does not mean that it needs to perform a task completely autonomously. There will be moments when the agent does not know what to do or how to answer. At this point, it needs to get the attention of a human and ask for help.
A concrete example of this is with an email assistant agent I am building. Although the email assistant can answer basic emails, it often needs my input on certain tasks I do not want to automate away. These tasks include reviewing complicated LangChain bug reports, decisions on whether I want to go to conferences, etc.
In this case, the email assistant needs a way of communicating to me that it needs information to respond. Note that it’s not asking me to respond directly; instead, it’s seeks my opinion on certain tasks, which it can then use to craft and send a nice email or schedule a calendar invite.
Currently, I have this assistant set up in Slack. It pings me a question and I respond to it in a thread, natively integrating with my workflow. If I were to think about this type of UX at a larger scale than just an email assistant for myself, I would envision a UX similar to a customer support dashboard. This interface would show all the areas where the assistant needs human help, the priority of requests, and any additional metadata.
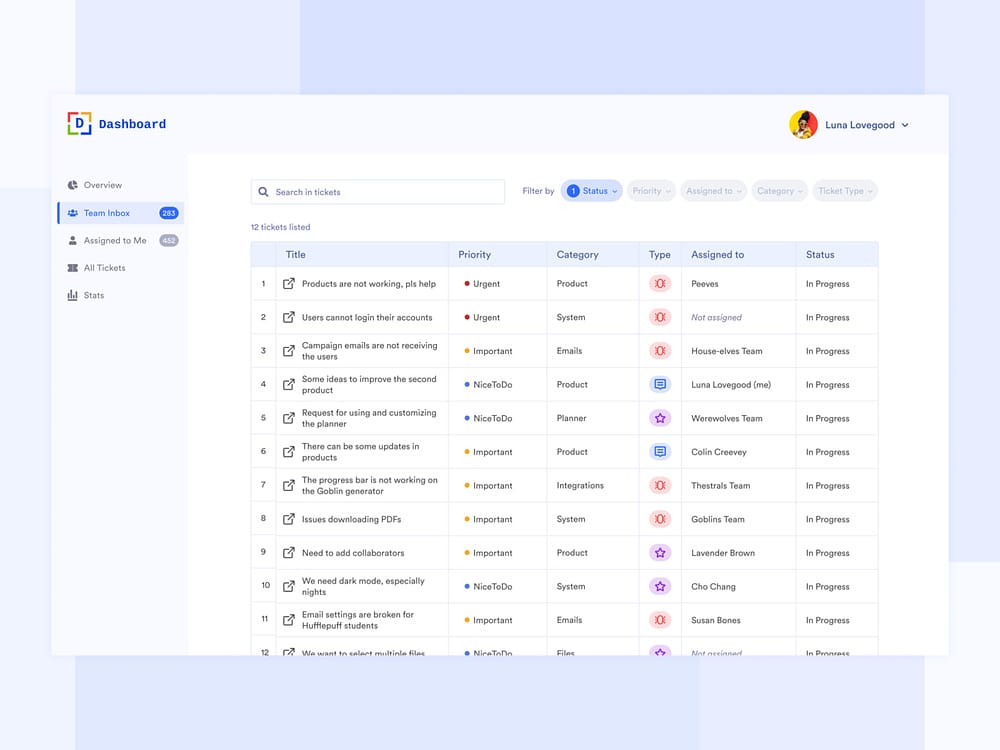
I initially used the term “Agent Inbox” when describing this email assistant - but more accurately, it’s an inbox for humans to assist agents on certain tasks… a bit of a chilling thought.
Conclusion
I am incredibly bullish on ambient agents, as I think they are key to allowing us to scale our own capabilities as humans.
As our team continues building LangGraph, we are building with these types of UXs in mind. We checkpoint all states, easily allowing for human-on-the-loop observability, rewinding, and editing. This also enables agents to reach out to a human and wait for their response before continuing.
If you’re building an application with ambient agents, please reach out. We’d love to hear about your experience!