
Update: Several readers have pointed out that the term "cognitive architecture" has a rich history in neuroscience and computational cognitive science. Per Wikipedia, "a cognitive architecture refers to both a theory about the structure of the human mind and to a computational instantiation of such a theory". That definition (and corresponding research and articles on the topic) are more comprehensive than any definition I attempt to offer here, and this blog should instead be read as a mapping of my experience building and helping build LLM-powered applications over the past year to this area of research.
One phrase I’ve used a lot over the past six months (and will likely use more) is “cognitive architecture”. It’s a term I first heard from Flo Crivello - all credit for coming up with it goes to him, and I think it's a fantastic term. So what exactly do I mean by this?
What I mean by cognitive architecture is how your system thinks — in other words, the flow of code/prompts/LLM calls that takes user input and performs actions or generates a response.
I like the word “cognitive” because agentic systems rely on using an LLM to reason about what to do.
I like the word “architecture” because these agentic systems still involve a good amount of engineering similar to traditional system architecture.
Mapping levels of autonomy to cognitive architectures
If we refer back to this slide (originally from my TED Talk) on the different levels of autonomy in LLM applications, we can see examples of different cognitive architectures.
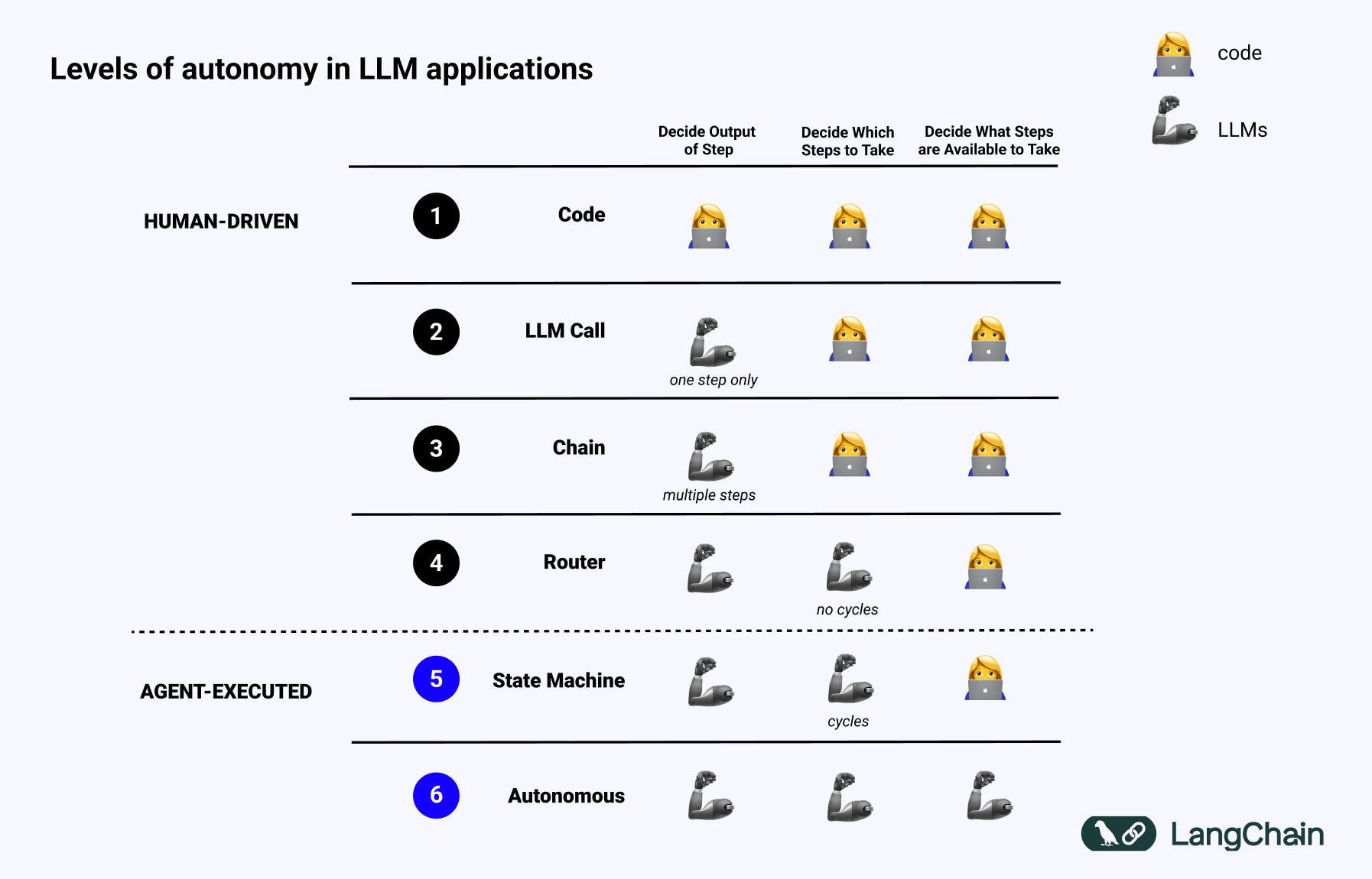
First is just code - everything is hard coded. Not even really a cognitive architecture.
Next is just a single LLM call. Some data preprocessing before and/or after, but a single LLM call makes up the majority of the application. Simple chatbots likely fall into this category.
Next is a chain of LLM calls. This sequence can be either breaking the problem down into different steps, or just serve different purposes. More complex RAG pipelines fall into this category: use a first LLM call to generate a search query, then a second LLM call to generate an answer.
After that, a router. Prior to this, you knew all the steps the application would take ahead of time. Now, you no longer do. The LLM decides which actions to take. This adds in a bit more randomness and unpredictability.
The next level is what I call a state machine. This is combining an LLM doing some routing with a loop. This is even more unpredictable, as by combining the router with a loop, the system could (in theory) invoke an unlimited number of LLM calls.
The final level of autonomy is the level I call an agent, or really an “autonomous agent”. With state machines, there are still constraints on which actions can be taken and what flows are executed after that action is taken. With autonomous agents, those guardrails are removed. The system itself starts to decide which steps are available to take and what the instructions are: this can be done by updating the prompts, tools, or code used to power the system.
Choosing a cognitive architecture
When I talk about "choosing a cognitive architecture,” I mean choosing which of these architectures you want to adopt. None of these are strictly “better” than others - they all have their own purpose for different tasks.
When building LLM applications, you’ll probably want to experiment with different cognitive architectures just as frequently as you experiment with prompts. We’re building LangChain and LangGraph to enable that. Most of our development efforts over the past year have gone into building low-level, highly controllable orchestration frameworks (LCEL and LangGraph).
This is a bit of a departure from early LangChain which focused on easy-to-use, off-the-shelf chains. These were great for getting started but tough to customize and experiment with. This was fine early on, as everyone was just trying to get started, but as the space matured, the design pretty quickly hit its limits.
I’m extremely proud of the changes we’ve made over the past year to make LangChain and LangGraph more flexible and customizable. If you’ve only ever used LangChain through the high level wrappers, check out the low-level bits. They are much more customizable, and will really let you control the cognitive architecture of your application.
If you’re building straight-forward chains and retrieval flows, check out LangChain in Python and JavaScript. For more complex agentic workflows, try out LangGraph in Python and JavaScript.