
Editor's Note: This post was written in collaboration with the Xata team. We're excited about their new integrations and really enjoyed their deepdive on implementation a Q&A chat bot with them.
Over the past few weeks, we’ve merged four Xata integrations to the LangChain repositories, and today we’re happy to unveil them as part of Xata’s launch week! In this blog post, we’ll take a brief look at what Xata is and why it is a good data companion for AI applications. We’ll also show a code example for implementing a Q&A chat bot that answers questions based on the info in a Xata database (as a vector store) and has long-term memory stored in Xata (as a memory store).
What is Xata?
Xata is a database platform powered by PostgreSQL. It stores the source-of-truth data in PostgreSQL, but also replicates it automatically to Elasticsearch. This means that it offers functionality from both Postgres (ACID transactions, joins, constraints, etc.) and from Elasticsearch (BM25 full-text search, vector search, hybrid search), behind the same simple serverless API. This covers the functionality needed by the majority of AI applications and because it’s based on PostgreSQL and Elasticsearch, it is reliable and scalable.
Xata has client SDKs for both TypeScript/JavaScript and Python and built-in integrations with platforms like GitHub, Vercel, and Netlify.
In the AI space, beside the LangChain integrations announced here, Xata offers a deep integration with OpenAI for the “ChatGPT on your data” use case.
The integrations
As of today, the following integrations are available :
- Xata as a vector store in LangChain. This allows one to store documents with embeddings in a Xata table and perform vector search on them. The integration takes advantage of the newly GA-ed Python SDK. The integration supports filtering by metadata, which is represented in Xata columns for the maximum performance.
- Xata as a vector store in LangChain.js. Same as the Python integration, but for your TypeScript/JavaScript applications.
- Xata as a memory store in LangChain. This allows storing the chat message history for AI chat sessions in Xata, making it work as “memory” for LLM applications.The messages are stored in
- Xata as a memory store in LangChain.js. Same as the Python integration, but for TypeScript/JavaScript.
Each integration comes with one or two code examples in the doc pages linked above.
The four integrations already make Xata one of the most comprehensive data solutions for LangChain, and we’re just getting started! For the near future, we’re planning to add custom retrievers for the Xata keyword and hybrid search and the Xata Ask AI endpoint.
Example: Conversational Q&A with memory
While each LangChain integration comes with at least one minimal code example, in this blog post we’ll look at a more complex example that uses Xata both as a vector store and as a memory store. The application implements the “chat with your data” use case, and allows for follow-up questions. The full code can be found in this repo, which you can also use as a starter-kit for LangChain + Xata applications.
While the example application here is written in TypeScript, a similar example using the Python LangChain can be found in this Jupyter notebook.
The main part of the code looks like this:
import * as dotenv from "dotenv";
import { XataVectorSearch } from "langchain/vectorstores/xata";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { Document } from "langchain/document";
import { ConversationalRetrievalQAChain } from "langchain/chains";
import { BufferMemory } from "langchain/memory";
import { XataChatMessageHistory } from "langchain/stores/message/xata";
import { ChatOpenAI } from "langchain/chat_models/openai";
import { getXataClient } from "./xata.ts";
dotenv.config();
const client = getXataClient();
/* Create the vector store */
const table = "docs";
const embeddings = new OpenAIEmbeddings();
const vectorStore = new XataVectorSearch(embeddings, { client, table });
/* Add documents to the vector store */
const docs = [
new Document({
pageContent: "Xata is a Serverless Data platform based on PostgreSQL",
}),
new Document({
pageContent:
"Xata offers a built-in vector type that can be used to store and query vectors",
}),
new Document({
pageContent: "Xata includes similarity search",
}),
];
const ids = await vectorStore.addDocuments(docs);
// eslint-disable-next-line no-promise-executor-return
await new Promise((r) => setTimeout(r, 2000));
/* Create the chat memory store */
const memory = new BufferMemory({
chatHistory: new XataChatMessageHistory({
table: "memory",
sessionId: new Date().toISOString(), // Or some other unique identifier for the conversation
client,
createTable: false,
}),
memoryKey: "chat_history",
});
/* Initialize the LLM to use to answer the question */
const model = new ChatOpenAI({});
/* Create the chain */
const chain = ConversationalRetrievalQAChain.fromLLM(
model,
vectorStore.asRetriever(),
{
memory,
}
);
/* Ask it a question */
const question = "What is Xata?";
const res = await chain.call({ question });
console.log("Question: ", question);
console.log(res);
/* Ask it a follow up question */
const followUpQ = "Can it do vector search?";
const followUpRes = await chain.call({
question: followUpQ,
});
console.log("Follow-up question: ", followUpQ);
console.log(followUpRes);
/* Clear both the vector store and the memory store */
await vectorStore.delete({ ids });
await memory.clear();
Let’s take it piece by piece and see what it does:
First, we use Xata as a vector store. In this vector store, we index a few sample documents, but in a real application you can index tens of thousands of documents. These are the documents that our chatbot will use to find answers for user questions. While not shown here, it’s also possible to add custom metadata columns to these documents. You can see the examples on the integration page.
/* Create the vector store */
const table = "docs";
const embeddings = new OpenAIEmbeddings();
const vectorStore = new XataVectorSearch(embeddings, { client, table });
/* Add documents to the vector store */
const docs = [
new Document({
pageContent: "Xata is a Serverless Data platform based on PostgreSQL",
}),
new Document({
pageContent:
"Xata offers a built-in vector type that can be used to store and query vectors",
}),
new Document({
pageContent: "Xata includes similarity search",
}),
];
const ids = await vectorStore.addDocuments(docs);
Next, we create a chat memory store, again based on Xata. This stores the messages exchanged by the chat bots with the users in a Xata table. Each conversation gets a session ID, which is then used to retrieve the previous messages in the conversation, so that the context is not lost.
/* Create the chat memory store */
const memory = new BufferMemory({
chatHistory: new XataChatMessageHistory({
table: "memory",
sessionId: new Date().toISOString(), // Or some other unique identifier for the conversation
client,
createTable: false,
}),
memoryKey: "chat_history",
});
Then we initialize the client for interrogating the model, in this case the OpenAI ChatGPT API:
/* Initialize the LLM to use to answer the question */
const model = new ChatOpenAI({});
And finally, put all of them together in a conversational QA chain:
/* Create the chain */
const chain = ConversationalRetrievalQAChain.fromLLM(
model,
vectorStore.asRetriever(),
{
memory,
}
);
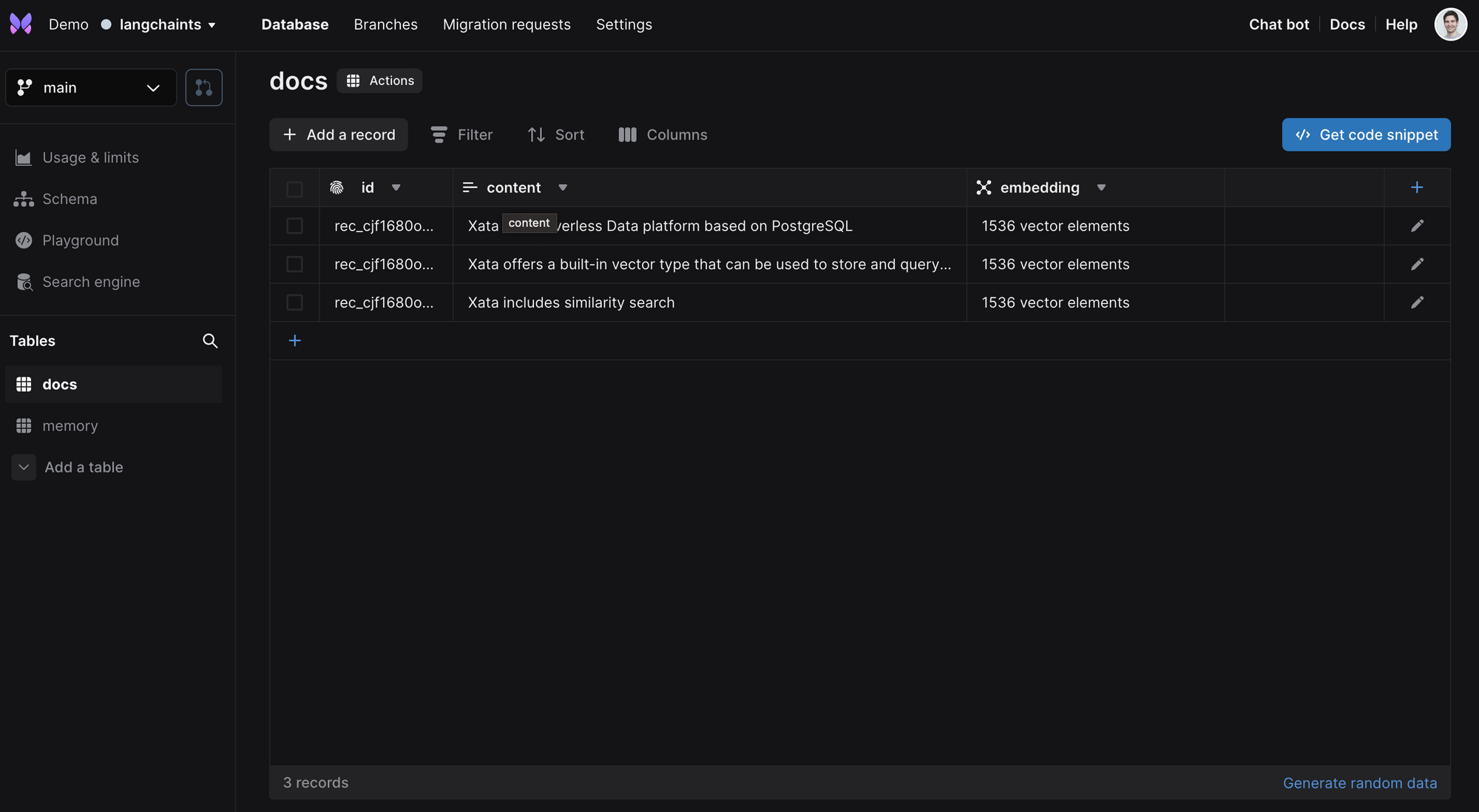
If you look at the data via the Xata UI while the example is running, you will see two tables: docs and memory. The docs table is populated with the documents from the vector store, having a content column and an embedding column of type vector:
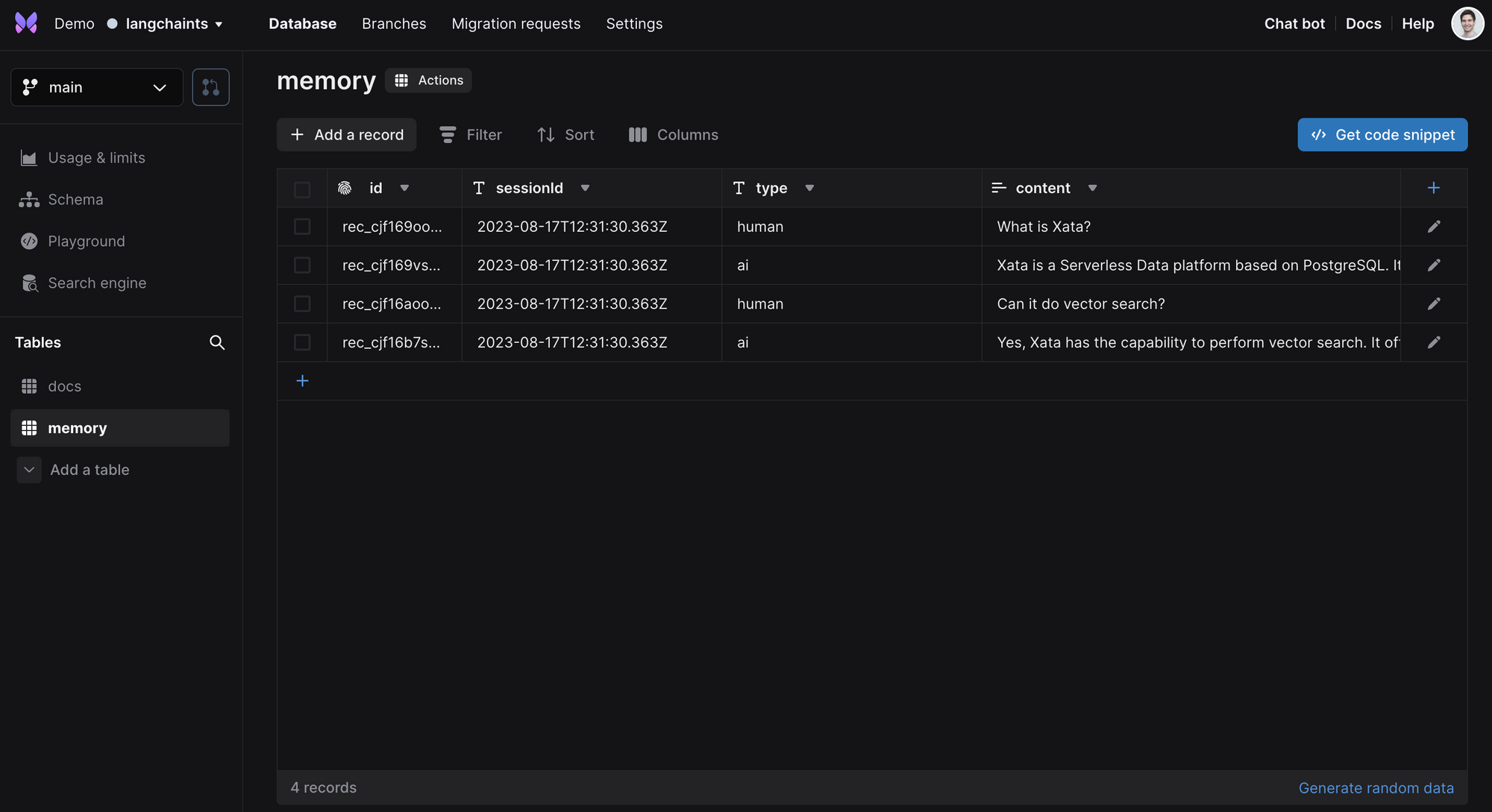
The memory table is populated with the questions and answers from the user and from the AI:
Content hackathon
As part of the launch week, Xata is also organizing a content hackathon, where you can win prizes and swag by creating apps, writing blogs, recording videos, and more. See the launch week blog post for details.
If you have any questions or ideas or if you need help implementing Xata with LangChain, join us on Discord or reach out on Twitter.