Key Links
Motivation
Because most LLMs are only periodically trained on a large corpus of public data, they lack recent information and / or private data that is inaccessible for training. Retrieval augmented generation (RAG) is a central paradigm in LLM application development to address this by connecting LLMs to external data sources (see our video series and blog post). The basic RAG pipeline involves embedding a user query, retrieving relevant documents to the query, and passing the documents to an LLM for generation of an answer grounded in the retrieved context.
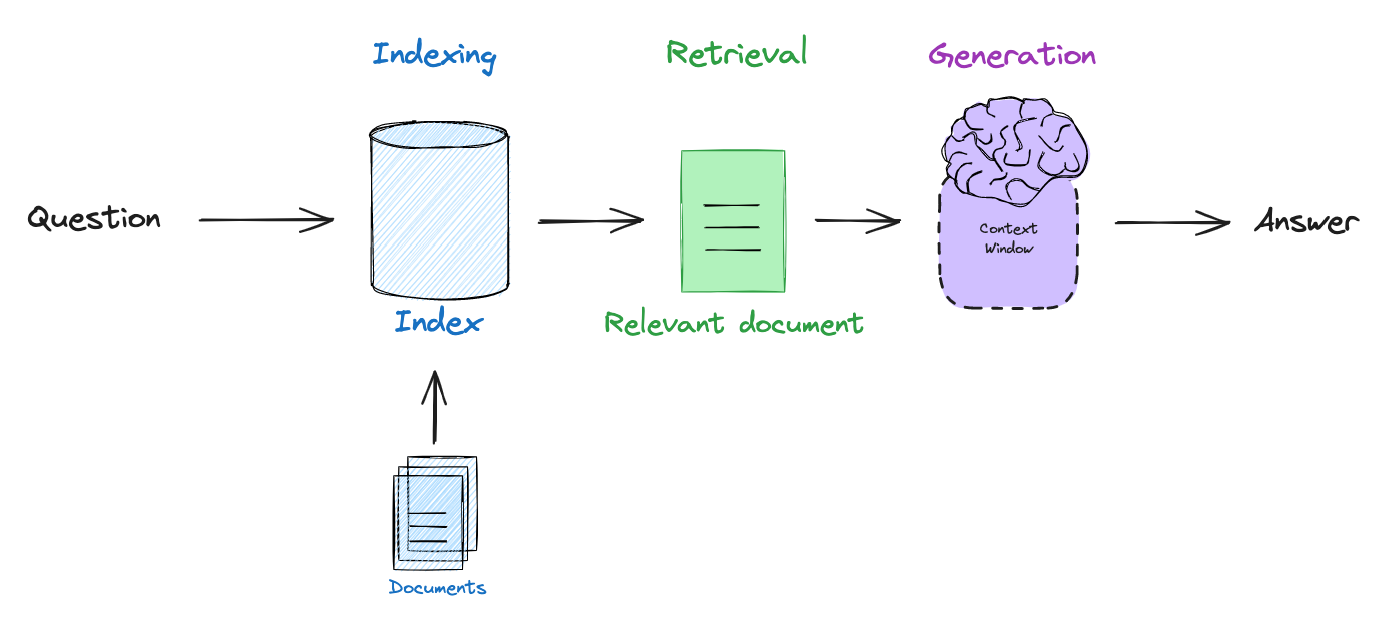
Self-Reflective RAG
In practice, many have found that implementing RAG requires logical reasoning around these steps: for example, we can ask when to retrieve (based upon the question and composition of the index), when to re-write the question for better retrieval, or when to discard irrelevant retrieved documents and re-try retrieval? The term self-reflective RAG (paper) has been introduced, which captures the idea of using an LLM to self-correct poor quality retrieval and / or generations.
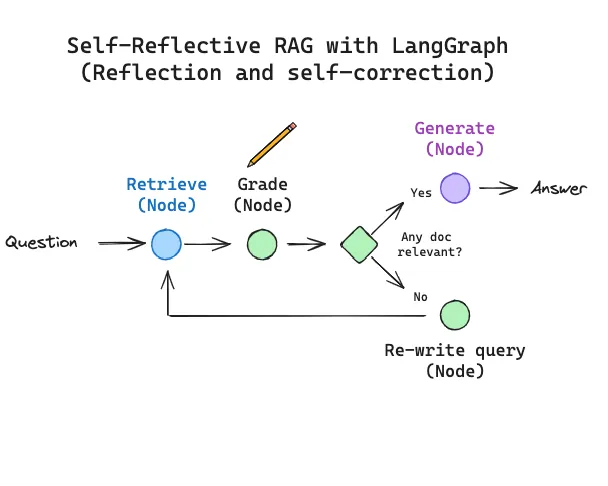
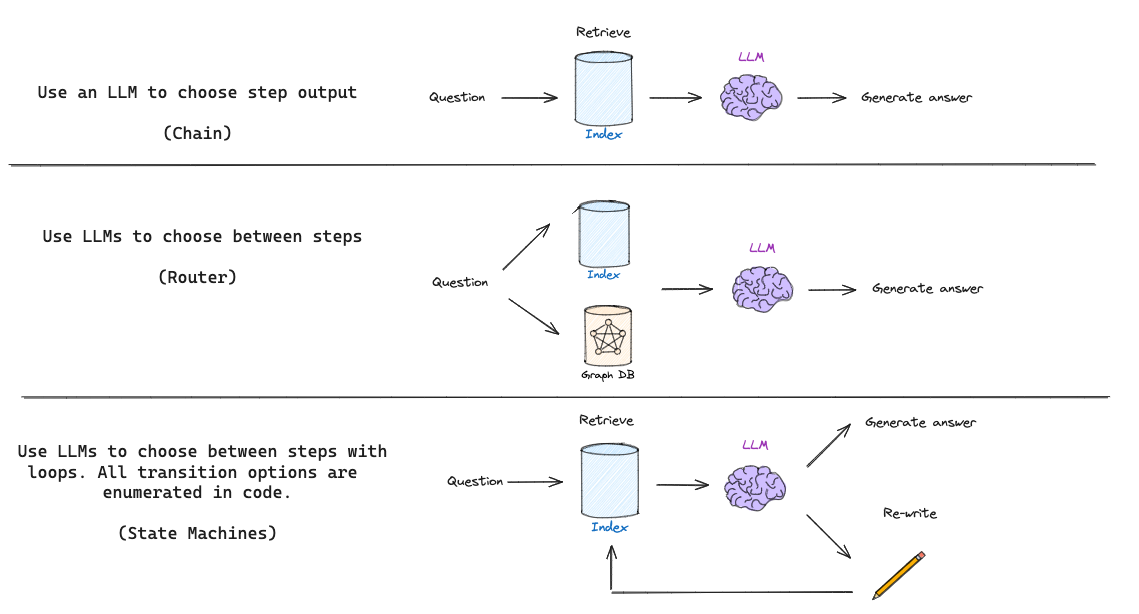
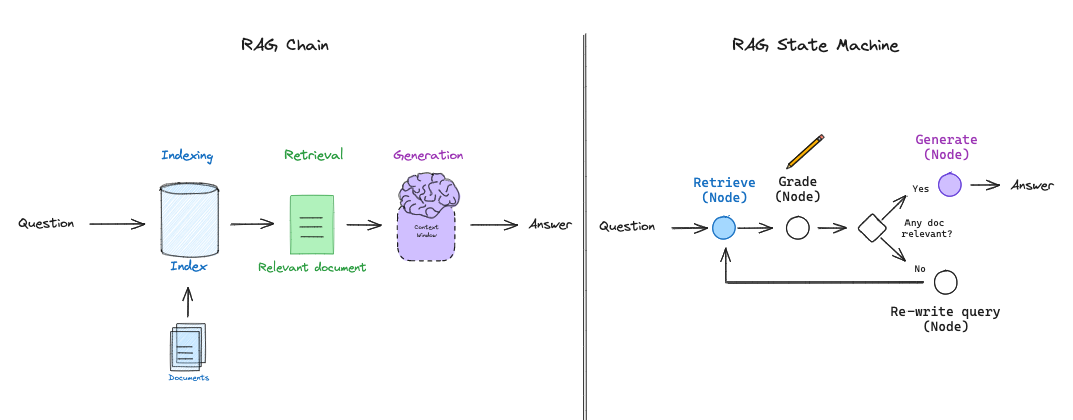
The basic RAG flow (shown above) simply uses a chain: the LLM determines what to generate based upon the retrieved documents. Some RAG flows use routing, where an LLM decides between, for example, different retrievers based on the question. But self-reflective RAG usually requires some kind of feedback, re-generating the question and / or re-retrieving documents. State machines are a third kind of cognitive architecture that supports loops and it well suited for this: a state machine simply lets us define a set of steps (e.g., retrieval, grade documents, re-write query) and set the transitions options between them; e.g., if our retrieved docs are not relevant, then re-write the query and re-retrieve new documents.
Self-Reflective RAG with LangGraph
We recently launched LangGraph, which is an easy way to implement LLM state machines. This gives us a lot of flexibility in the layout of diverse RAG flows and supports the more general process of "flow engineering" for RAG with specific decision points (e.g., document grading) and loops (e.g., re-try retrieval).
To highlight the flexibility of LangGraph, we'll use it to implement ideas inspired from two interesting and recent self-reflective RAG papers, CRAG and Self-RAG.
Corrective RAG (CRAG)
Corrective RAG (CRAG) introduces a few interesting ideas (paper):
- Employ a lightweight retrieval evaluator to assess the overall quality of retrieved documents for a query, returning a confidence score for each.
- Perform web-based document retrieval to supplement context if vectorstore retrieval is deemed ambiguous or irrelevant to the user query.
- Perform knowledge refinement of retrieved document by partitioning them into "knowledge strips", grading each strip, and filtering our irrelevant ones.
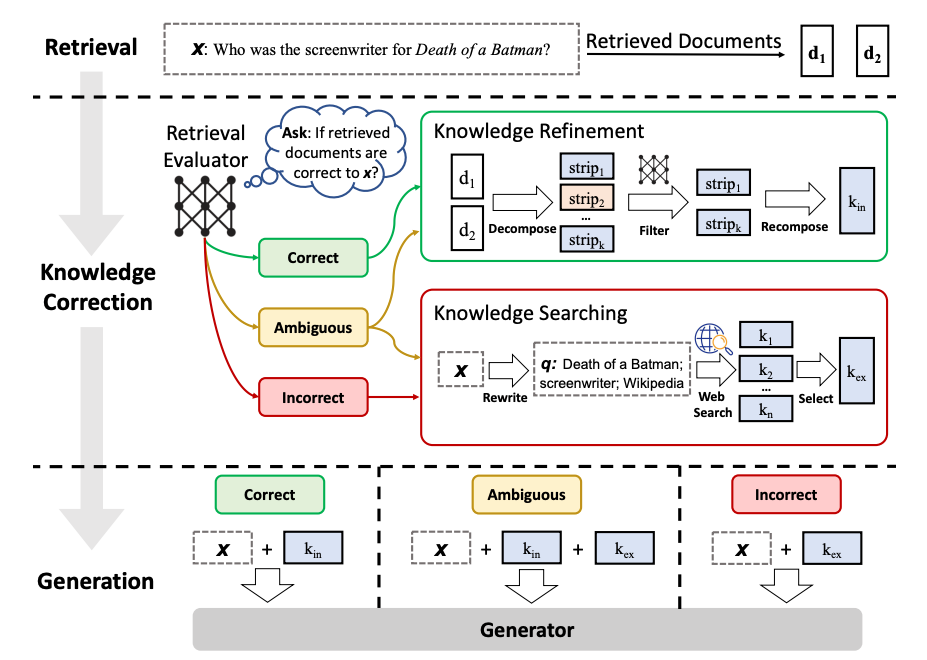
We can represent this as a graph, making a few simplifications and adjustment for illustrative purposes (of course, this can be customized and extended as desired):
- We will skip the knowledge refinement phase as a first pass. It represents an interesting and valuable form of post-processing, but is not essential for understanding how to lay out this workflow in LangGraph.
- If any document is irrelevant, we'll supplement retrieval with web search. We'll use Tavily Search API for web search, which is rapid and convenient.
- We'll use query re-writing to optimize the query for web search.
- For binary decisions, we use Pydantic to model the output and supply this function as an OpenAI tool that is called every time the LLM is run. This lets us model the output of conditional edges where consistent binary logic is critical.
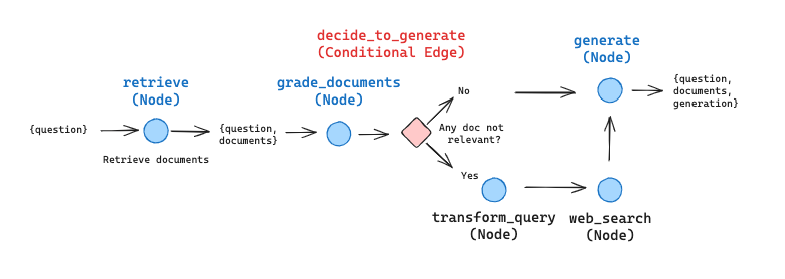
We lay this out in an example notebook and index three blog posts. We can see a trace here highlighting the usage when asked about information found in the blog posts: the logical flow across our nodes is clearly enumerated.
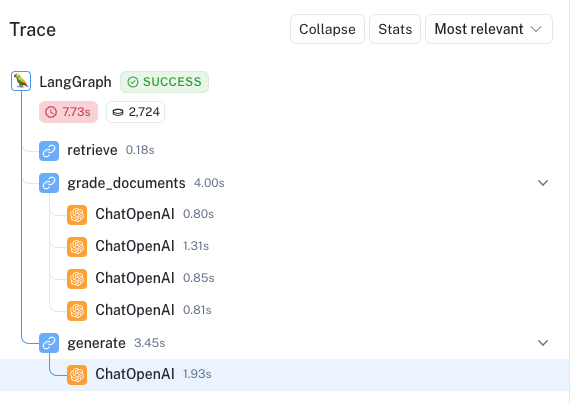
In contrast, we ask a question out of domain for the blog posts. The trace here shows that we invokes on the lower path of our conditional edge and gather supplementary documents from Tavily web search used in final generation.
Self-RAG
Self-RAG is a related approach with several other interesting RAG ideas (paper). The framework trains an LLM to generate self-reflection tokens that govern various stages in the RAG process. Here is a summary of the tokens:
Retrievetoken decides to retrieveDchunks with inputx (question)ORx (question),y (generation). The output isyes, no, continueISRELtoken decides whether passagesDare relevant toxwith input (x (question),d (chunk)) fordinD. The output isrelevant, irrelevant.
ISSUPtoken decides whether the LLM generation from each chunk inDis relevant to the chunk. The input isx,d,yfordinD. It confirm all of the verification-worthy statements iny (generation)are supported byd. Output isfully supported, partially supported, no support.ISUSEtoken decides whether generation from each chunk inDis a useful response tox. The input isx,yfordinD. Output is{5, 4, 3, 2, 1}.
This table in the paper supplements the above information:

We can outline this as simplified graph to understand the information flow:
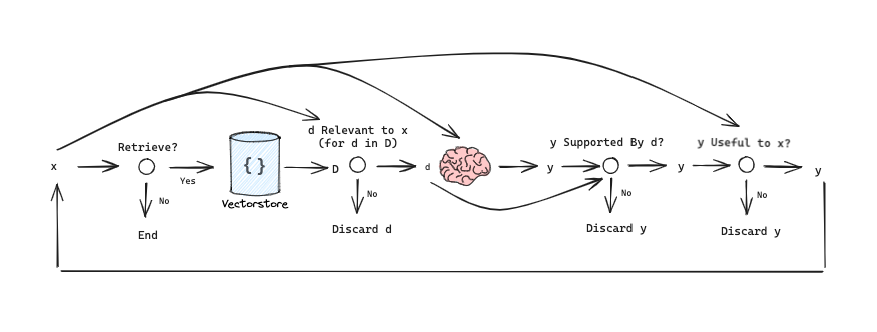
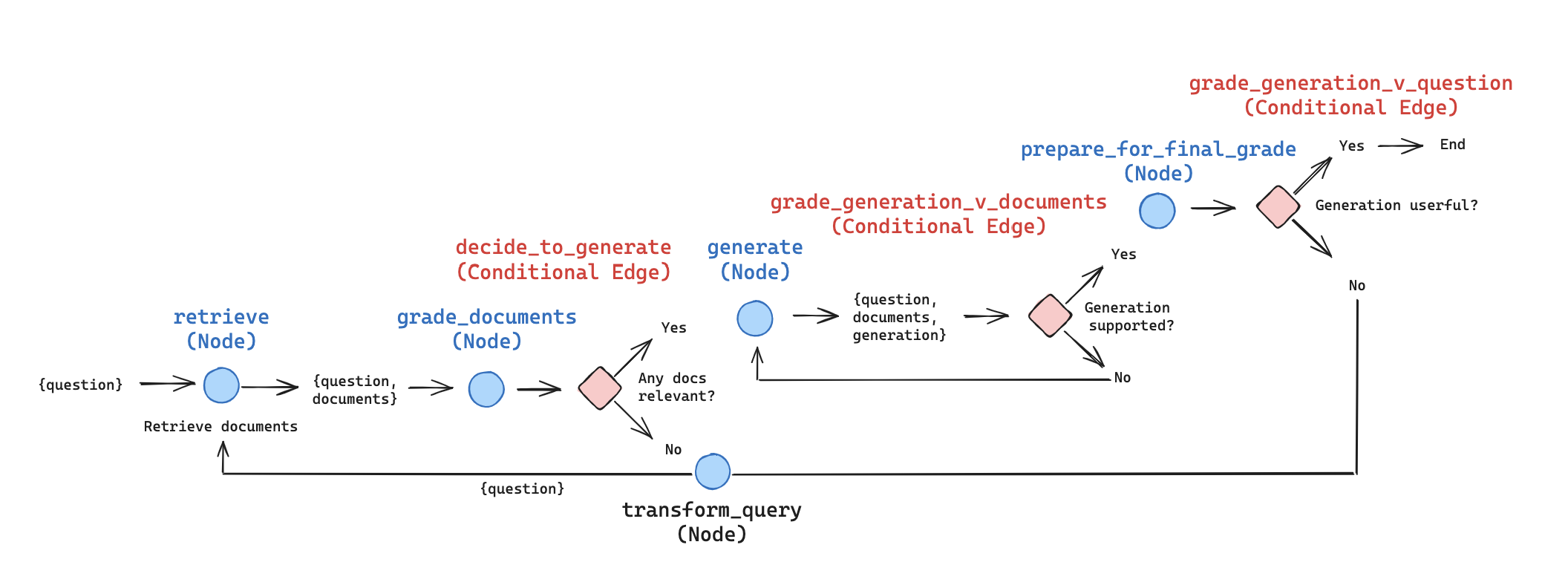
We can represent this in LangGraph, making a few simplifications / adjustments for illustrative purposes (this can be customized and extended as desired):
- As above, we grade each retrieved document. If any are relevant, we proceed to generation. If all are irrelevant, then we will transform the query to formulate an improved question and re-retrieve. Note: we could employ the idea above from CRAG (Web search) are a supplementary node in this path!
- The paper will perform a generation from each chunk and grade it twice. Instead, we perform a single generation from all relevant documents. The generation is then graded relative to the documents (e.g., to guard against hallucinations) and relative to the answer, as above. This reduces the number of LLM calls and improves latency, and allows for consolidation of more context into the generation. Of course, producing generations per chunk and grading them in isolation is an easy adaption if more control is required.
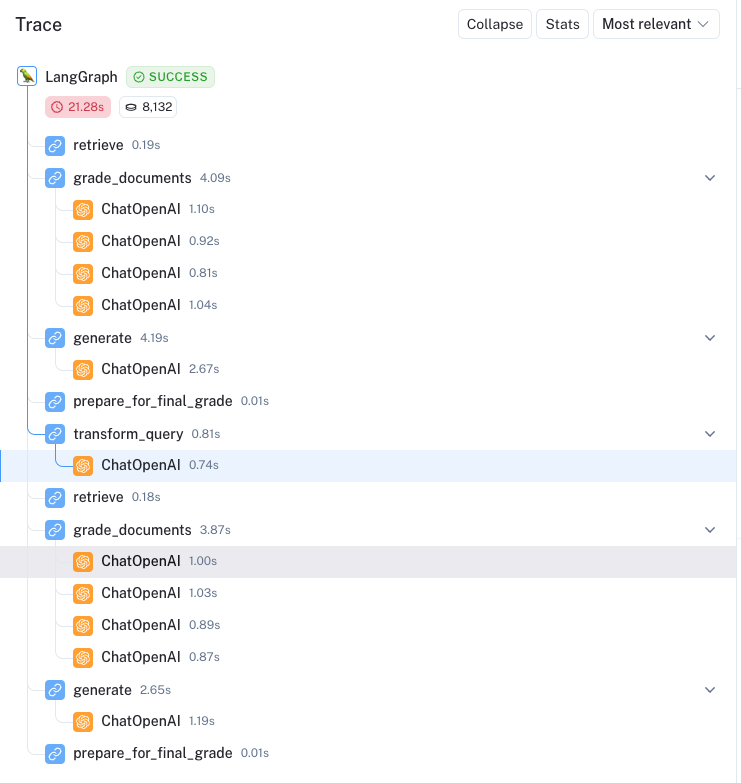
Here is an example trace that highlights the ability of active RAG to self-correct. The question is Explain how the different types of agent memory work?. All four documents were deemed relevant, the generation versus documents check passes, but the generation was not deemed fully useful to the question.
We then see the loop re-initiate with a re-formulated query here: How do the various types of agent memory function? . One of out of four documents is filtered because it is not relevant (here). The generation then passes both checks:
The various types of agent memory include sensory memory, short-term memory, and long-term memory. Sensory memory retains impressions of sensory information for a few seconds. Short-term memory is utilized for in-context learning and prompt engineering. Long-term memory allows the agent to retain and recall information over extended periods, often by leveraging an external vector store.
The overall trace is fairly easy to audit, with the nodes clearly laid out:
Conclusion
Self-reflection can greatly enhance RAG, enabling correction of poor quality retrieval or generations. Several recent RAG papers focus on this theme, but implementing the ideas can be tricky. Here, we show that LangGraph can be easily used for "flow engineering" of self-reflective RAG. We provide cookbooks for implementing ideas from two interesting papers, Self-RAG and CRAG.