Three weeks ago OpenAI held a highly anticipated developer day. They released a myriad of new features. The two most interesting to me were the Assistants API and GPTs. To me, these represent the same bet – on a particular, agent-like, closed “cognitive architecture”. They appeal to different end users, but both speak to OpenAI’s ambitions to drive applications towards this particular cognitive architecture. At LangChain, we believe in a world where LLMs power agent-like systems that are truly transformative. However, we believe the route to get there is one where companies have control over their cognitive architectures. You can do that today with projects like OpenGPTs - an open, editable, and configurable version of the Assistants API (and GPTs).
GPTs and the Assistants API
Of the two, GPTs are probably the more commonly discussed one on the internet. They provide a (largely) no-code way to create your own “GPT”. These GPTs can be customized with custom instructions, custom knowledge, and custom functions. These GPTs seem to be a second attempt at an app store of sorts, following up on Plugins (which - in Sam Altman's own words - did not find product market fit).
The Assistants API is the more developer-centric version of this idea. The Assistants API is a stateful API that allows for storage of previous messages, uploading of files, access to built-in tools (code interpreter), and can be used to control other tools (through function calling, where the developer specifies a function to be called, which can then be executed client side).
Cognitive Architectures
Under the hood, these both represent a similar type of “cognitive architecture”. Here, I use cognitive architecture to describe the orchestration of an LLM application. I first heard this term used by Flo Crivello (creator of Lindy, an autonomous agent startup) and think it is a fantastic term.
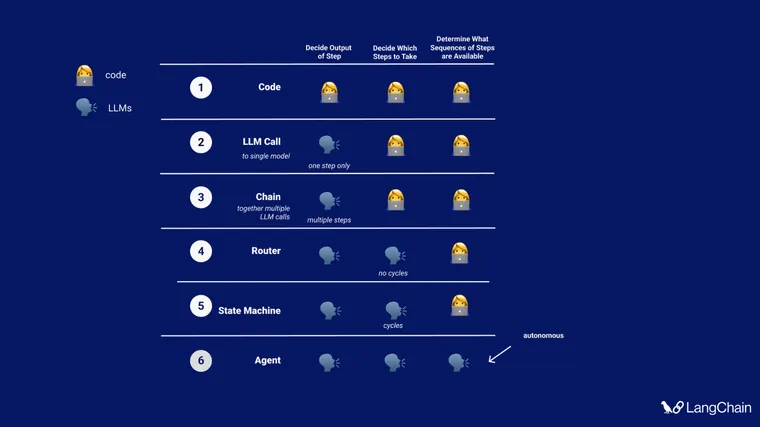
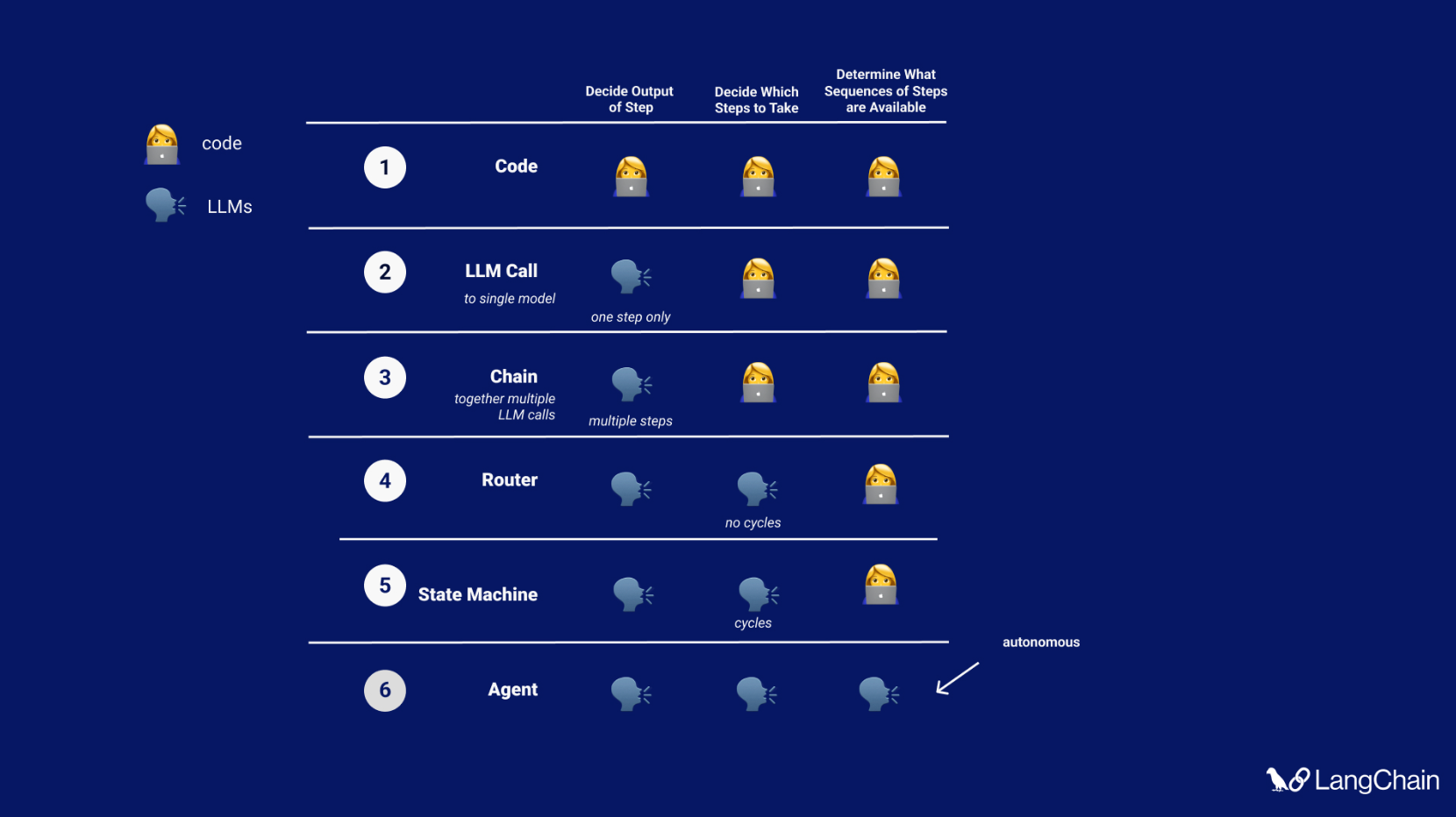
At LangChain, we’ve been thinking about cognitive architectures for a while. In a recent TedAI talk (video yet to be released) I spoke about the different levels of cognitive architectures that we see developers building. These include:
- A single LLM call, only determining the output of the application
- A chain of LLM calls, still only determining the output of the application
- Using an LLM as a router, to choose which action (tool, retriever, prompt) to use
- State machines - using LLMs to route between steps, in some sort of loop, but still with the allowed transition options enumerated in code
- Agents - removing a lot of the scaffolding, so that the transition options are wholly determined by the LLM
Agents
Both the Assistants API and GPTs are examples of the “agent” cognitive architecture described above. Sam Altman even used that exact term (”agent”) when announcing them. Although agents can be an overloaded term, used to describe a myriad of different applications, OpenAI’s use of the term largely tracks with our understanding: using the LLM alone to define transition options.
What do applications like this look like in practice? This can best be thought of as a loop. Given user input, this loop will be entered. An LLM is then called, resulting in either a response to the user OR action(s) to be taken. If it is determined that a response is required, then that is passed to the user, and that cycle is finished. If it is determined that an action is required, that action is then taken, and an observation (action result) is made. That action & corresponding observation are added back to the prompt (we call this an “agent scratchpad”), and the loop resets, ie. the LLM is called again (with the updated agent scratchpad).
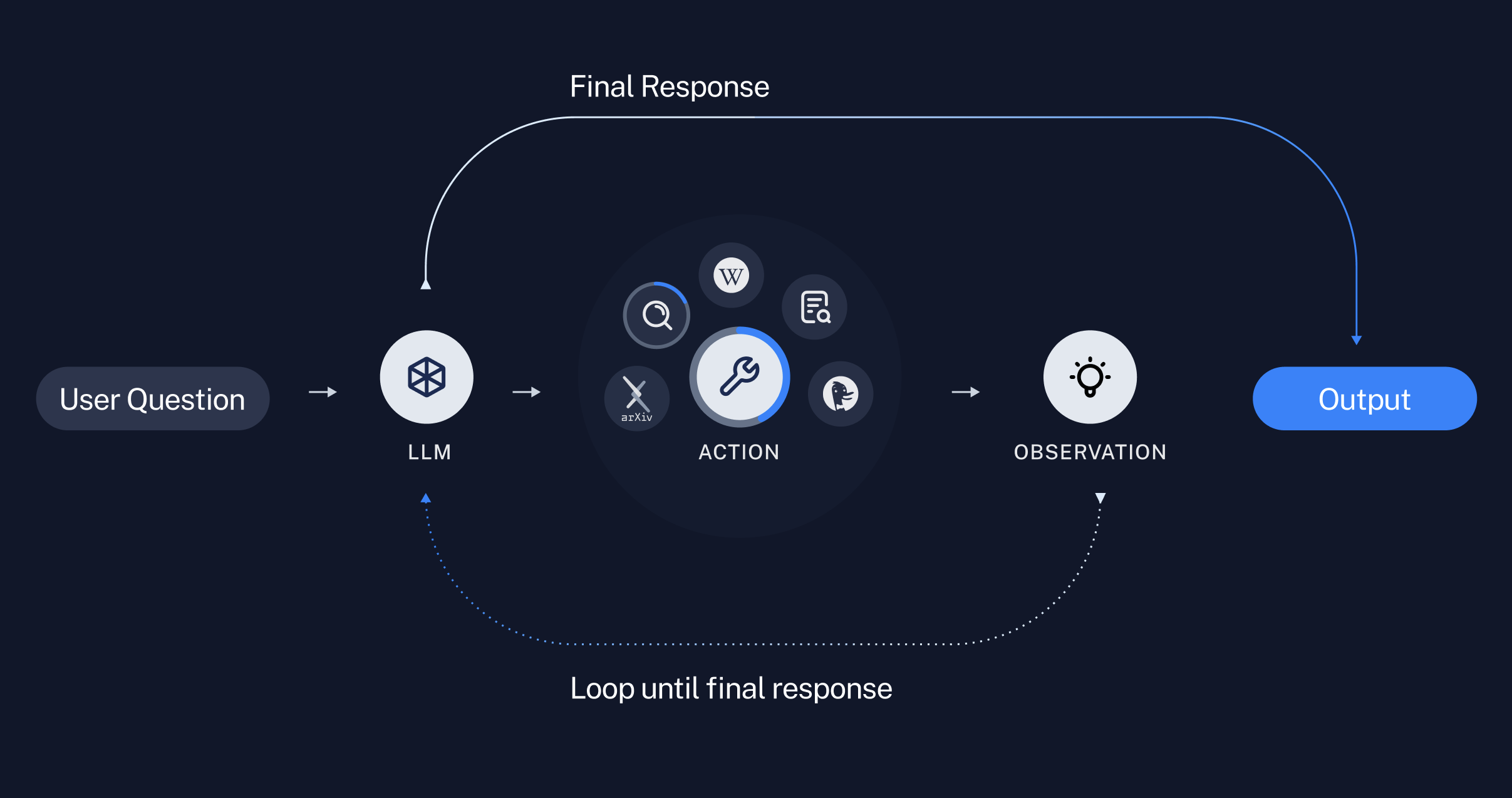
At a high level, this is what GPTs are doing. When they call a tool you give them (or a built-in tool like retrieval or code interpreter) you can see a widget on the screen that spins. This represents the action being taken, and the GPT is waiting for an observation. As some point, it just responds with text - no action to be taken - and the loop is finished.
The Assistants API is the same. The only difference is that the API doesn’t call the tools for you - unless it is a built in tool like retrieval or code interpreter. Instead, it responds with a certain type of message, telling you which tool(s) should be called (and what the inputs to those tools should be) and then waits for you to call the tools client-side and pass back in the results.
This “agent” cognitive architecture has been evolving over the past year and a half. AI21 Labs released their MRKL paper over a year and half ago. The ReAct prompting strategy (released over a year ago) was a particular type of prompting strategy that enables this type of architecture. We incorporated ReAct in LangChain nearly a year ago, quickly expanding to a more general, zero-shot prompting strategy. AutoGPT burst onto the scene about nine months ago, using this same cognitive architecture but giving it more tools, more persistent memory, and generally larger tasks to accomplish.
The Bet OpenAI is Making
I was very interested to see how heavily OpenAI leaned into agents given that by all accounts this cognitive architecture is not reliable enough for serious applications. They are best positioned out of anyone to make this work - they control the underlying model, after all. But it is still a bet. They are betting that over time the issues that plague agents will go away.
Nearly all of the actually useful “autonomous agents” that we see differ in two key regards.
First, many are actually NOT this “agent” cognitive architecture, but rather either elaborate and complex chains, or more similar to “state machines”. Two great public examples of this are GPT-Researcher and Sweep.dev.
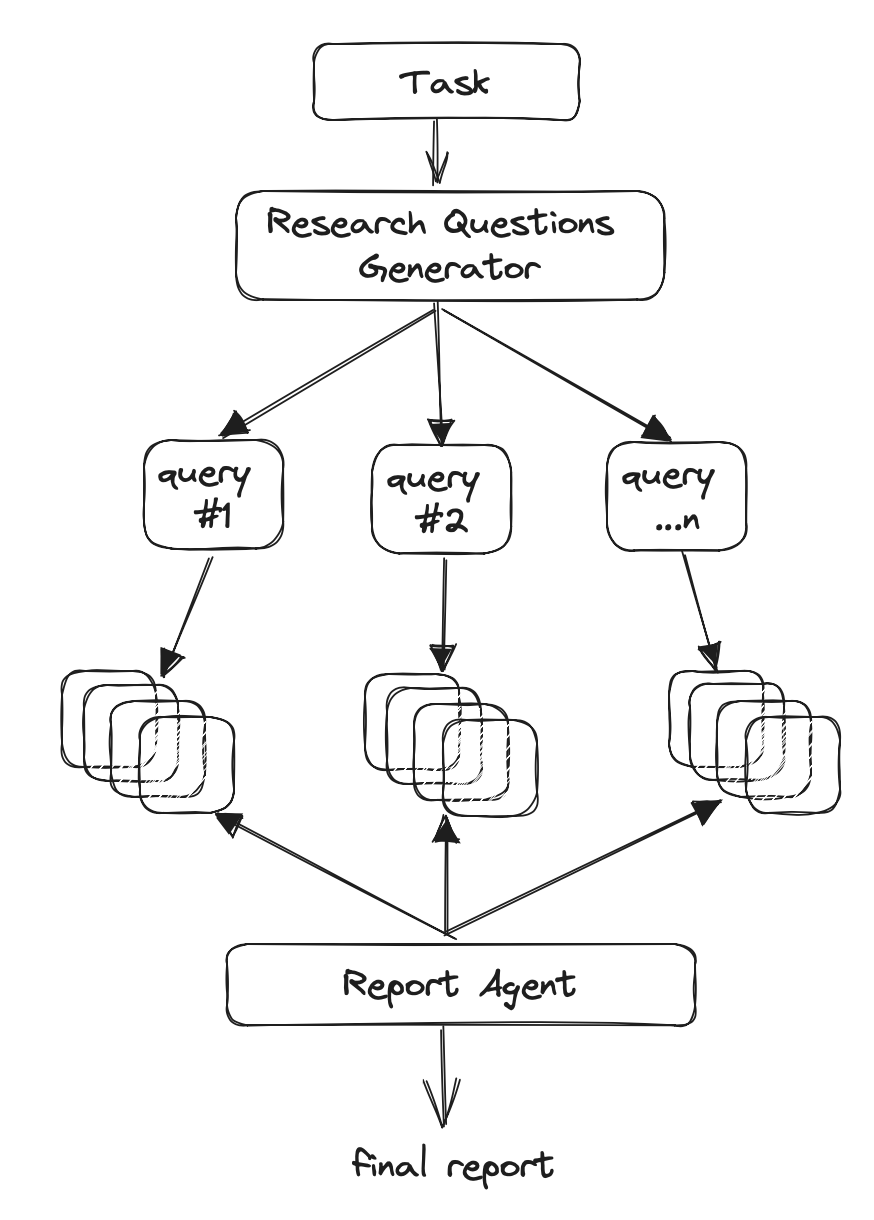
We wrote at length about GPT-Researcher multiple times, and worked with them last week to release a LangChain template. They are one of the few complex LLM powered applications that produce valuable results, but their cognitive architecture is more like a complex chain. If we look at the diagram below, we can see that it flows in one direction. It does a lot of complex steps, but in defined manner: it first generates sub questions, then gets links for each one, then summarizes each link, then combines the summaries into a research report.
Sweep.dev is another great example. They wrote a blog over the summer describing their cognitive architecture, including a fantastic diagram.

There are clearly defined transitions and steps. First, a search is done. Then a plan is generated. Then the plan is executed on. There is then a validation step: if it passes, a PR is made and Sweep is done. If it fails, then it makes a new plan. This is a pretty clear state machine, where there are well defined transitions between different states.
Many other builders and teams that we work with have complex chains/state machines powering their applications.
For applications that do use something more similar to this agent architecture, they differ from GPTs in another way: how context is provided to the agent.
I was chatting with Flo Crivello about cognitive architectures and he brought up the point that one difference in the agent architecture is how context is provided to the agent. Remember, the way we describe most of the interesting LLM applications is “context-aware reasoning applications”.
What does it mean for an agent to pull context? This means that the agent decides what context it needs, and then asks for it. This generally happens via a tool. As a concrete example, an agent created to interact with a SQL database may need to know what tables are present in the SQL database. So we may give it a tool that returns a list of tables in the database, and it can call that tool at the start.
In contrast, when context is pushed to the language model it is encoded in the logic of an application that a particular piece context should be fetched and pushed into the prompt. In the example of the SQL agent above, this would correspond to automatically fetching the SQL tables ahead of time and inserting them in the prompt.
Most applications that do use an agent architecture have a significant amount of pushed context. As one example, the SQL and Pandas agents in LangChain have the table schemas as part of the system message. As another example, the agent that the Rubrics team built for Cal.com has a significant amount of user information pushed into the prompt.
This push vs pull of context again gives developers more control. It allows us to enforce what context is relevant to the LLM when deciding what to do. Specifically, knowing what context is most relevant, how to fetch that context, and how to provide it are small decisions that can make a big impact on quality and performance.
GPTs - and to an extent, the Assistant API - largely empower applications with an unconstrained agent architecture that rely more on pulling context as needed. This can be great for getting started quickly or for simple tasks, but for more complex use cases, there’s no substitute for controlling the cognitive architecture that suits the problem at hand.
Open vs Closed
Aside from the choice of cognitive architecture, another notable attribute of Assistants API and GPTs is that the cognitive architecture itself is closed. We do not know what is going on under the hood. We do not know the exact algorithm. We do not know what is being done to manage the context of the chat history. We do not know what is being done for retrieval.
Right now we can make guesses at both of those. However, as they add more and more, and it gets more and more complex, it will become more and more of a black box.
Over time, I bet this will become a larger discussion topic than the models themselves. A year ago, most of the new features (and I would bet most of the focus internally) was on better models. Now, it seems to be a 50/50 split between core model improvements versus figuring out how best to hook them up in an agentic manner. As more evidence of the importance of this, Karpathy’s Twitter feed (the definitive reading list for all things AGI) is shifting more and more towards this idea of the LLM as an OS. Over this past weekend, he released a fantastic video on exactly that.
I fully expect this trend to continue, and OpenAI (and perhaps other labs) to invest more in platform and tooling around models, rather than just models themselves. The way to AGI is not (just) in better models - it’s also in hooking them up to their surroundings. As the focus of these labs shift, I expect - and hope - the discourse around open vs closed will happen not just models but also for cognitive architectures.
Do Cognitive Architectures Make Your Beer Taste Better?
There’s a great quote from Jeff Bezos that says to only do what makes your beer taste better. This refers to early industrial revolution, when breweries were also making their own electricity. A breweries ability to make good beer doesn’t really depend on how differentiated their electricity was - so those that outsourced electricity generation and focused more on brewing jumped to an advantage.
Is the same true of cognitive architectures? Does having control over your cognitive architecture really make your beer taste better? At the moment, I would argue strongly the answer is yes, for two reasons. First: it’s very difficult to make complex agents actually function. If your application relies on agents working, and getting agents to work is challenging, then almost by definition if you can do that well you’ll have an advantage over your competition. The second reason is that we often see the value of GenAI applications being really closely tied to the performance of the cognitive architecture. A lot of current companies are selling agents for coding, agents for customer support. In those cases, the cognitive architecture IS the product.
That last reason is also the reason that I find it hard to believe that companies would be willing to lock into a cognitive architecture controlled by a single company. I think this is different form of lock-in than cloud or even LLMs. In those cases, you are using cloud resources and LLMs in order to build or power a particular application. But if a cognitive architecture moves closer and closer to being a full application by itself - you’re unlikely to want to have that locked in.
How LangChain fits in
At LangChain, we believe in a world where LLMs power agent-like systems that are truly transformative. However, we believe the route to get there is one where companies have control over their cognitive architectures.
This takes a lot of engineering work. We’re building tools to help with that. With LCEL we have a flexible way to compose chains together. With LangChain we have over 600 integrations allowing for full flexibility in what model/vectorstore/database you use. With LangSmith we’ve explicitly focused on having the best debugging experience possible (because that’s where most teams are) but we’ve also adding in management tools (regression testing, monitoring, data annotation, prompt hub) to help you manage these systems as you to go production.
We’ve also recently released OpenGPTs. This is an attempt to recreate the same experience as the Assistants API as well as GPTs (our implementation of GPTs is just a simple UI over the Assistants API). This is open sourced, currently configurable with four different model providers, and the exact retrieval method used can be easily modified.
This is just the start.