Agents may be the “killer” LLM app, but building and evaluating agents is hard. Function calling is a key skill for effective tool use, but there aren’t many good benchmarks for measuring function calling performance. Today, we are excited to release four new test environments for benchmarking LLMs’ ability to effectively use tools to accomplish tasks. We hope this makes it easier for everyone to test different LLM and prompting strategies to show what enables the best agentic behavior.
We designed these tasks to test capabilities we consider to be prerequisites for common agentic workflows, such as planning / task decomposition, function calling, and the ability to override pre-trained biases when needed. If an LLM is unable to solve these types of tasks (without explicit fine-tuning), it will likely struggle to perform and generalize reliably for other workflows where “reasoning” is required. Below are some key take-ways for those eager to see our findings:
- All of the models can fail over longer trajectories, even for simple tasks.
- GPT-4 got the highest score on the Relational Data task, which most closely approximates common usage.
- GPT-4 seems to be worse than GPT-3.5 on the Multiverse Math task; it's possible its pretrained bias hinders its performance in an example of inverse scaling.
- Claude-2.1 performs within the error bounds of GPT-4 for 3 of 4 tasks, though seems to lag GPT-4 on the relational data task.
- Despite outputting well-formatted tool invocations, AnyScale’s fine-tuned variant of Mistral 7b struggles to reliably compose more than 2 calls. Future open-source function calling efforts should focus on function composition in addition to single-call correctness.
- In addition to model quality, service reliability is important. We ran into frequent random 5xx errors from the most popular model providers.
- Superhuman model knowledge doesn't help if your task or knowledge differs significantly from its pre-training. Validate the LLM you choose on the behavior patterns you need it to excel on before deploying.
- Planning is still hard for LLMs - the likelihood of failure increases with the number of required steps, even for simple tasks.
- Function calling makes it easy to get 100% schema correctness, but that’s not sufficient for task correctness. If you are fine-tuning a model for agent use, it's imperative that you train on multi-step trajectories.
In the rest of this post, we’ll walk through each task and communicate some initial benchmark results.
Experiment overview
In this release, we are sharing results and code to reproduce these experiments for 7 models across the 4 tool usage tasks:
- Typewriter (Single tool): sequentially call a single tool to type out a word.
- Typewriter (26 tools): call different tools in sequence to type out a word.
- Relational Data: answer questions based on information in three tables.
- Multiverse Math: use tools to answer math problems, where the underlying math rules have changed slightly.
We calculate four metrics across these tasks:
- Correctness (compared to the ground truth) - this uses an LLM as a judge. Since the answers for all these questions are concise and fairly binary, we found the judgements to correspond to our own decisions.
- Correct final state (environment) - for the typewriter tasks, each tool invocation updates the world state. We directly check the equivalence of the environment at the end of each test row.
- Intermediate step correctness - each data point has an optimal sequence of function calls to obtain the correct answer. We directly check the order of function calls against the ground truth.
- Ratio of steps taken to the expected steps - it may be that an agent ultimately returns the correct answer despite choosing a suboptimal set of tools. This metric will reflect discrepancies without being as strict as the exact match intermediate step. correctness.
We compared both closed source models as well as open source. Expand the section below for more details.
Models Tested
Open Source:
- Mistral-7b-instruct-v0.1: Mistral’s 7B parameter model adapted by Anyscale for function calling.
- Mixtral-8x7b-instruct: Mistral's 7B parameter mixture of experts model, adapted using instruction tuning by Fireworks.ai.
OpenAI - (Tool Calling Agent)
- GPT-3.5-0613
- GPT-3.5-1106-preview
- GPT-4-0613
- GPT-4-1106-preview
Anthropic
- Claude 2.1 using XML prompting and its tool user library.
⌨ Typewriter (Single tool)
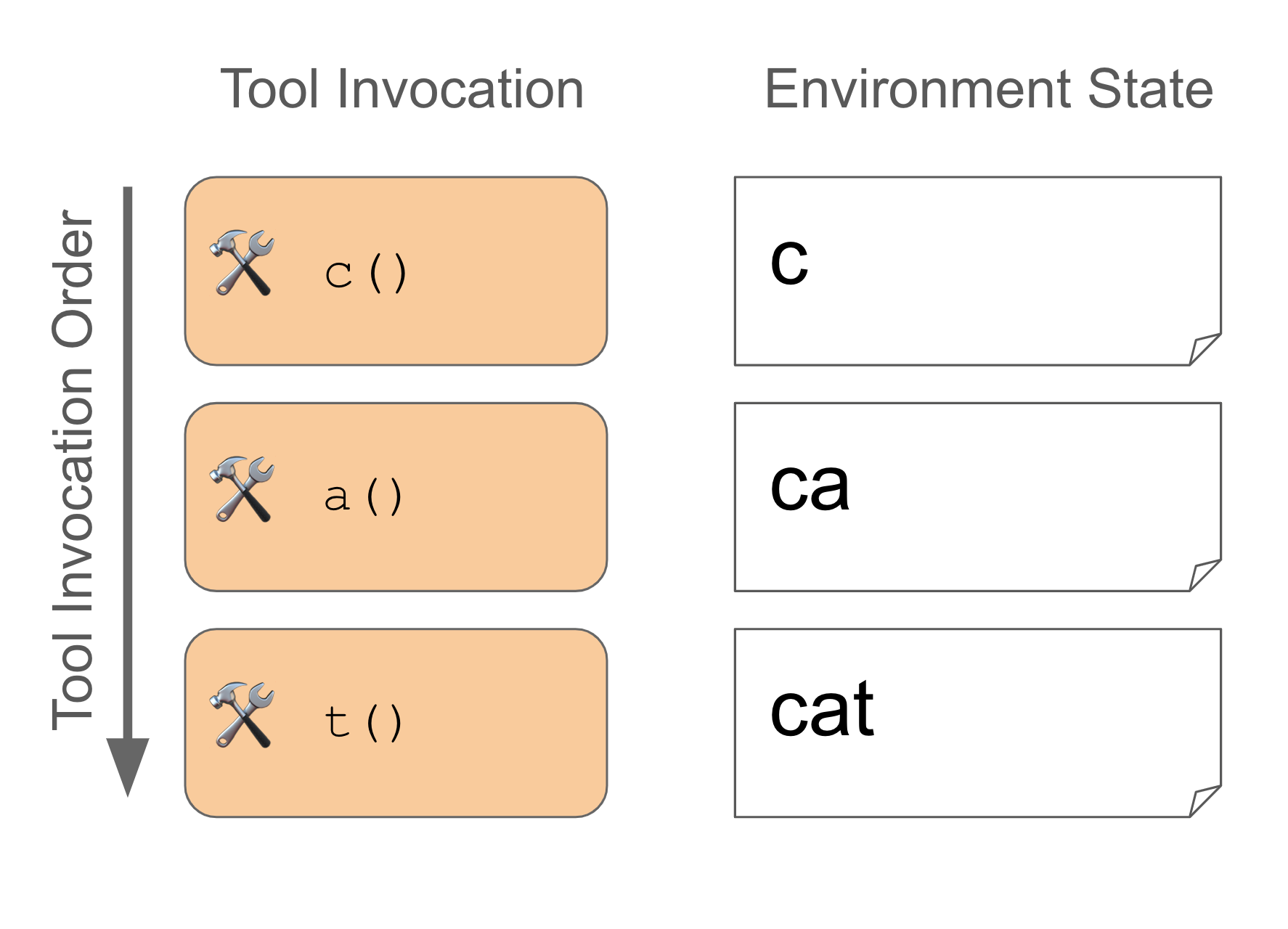
The typewriter tasks are simple: the agent must “type” a given word and then stop. Words range from easy (a or cat ) to a tad harder (communication and keyboard). In the single-tool setting, the model is given a single type_letter tool that accepts a character as input. To pass, all the agent has to do is call the tool for each letter in the right sequence. For instance, for cat, the agent would execute:
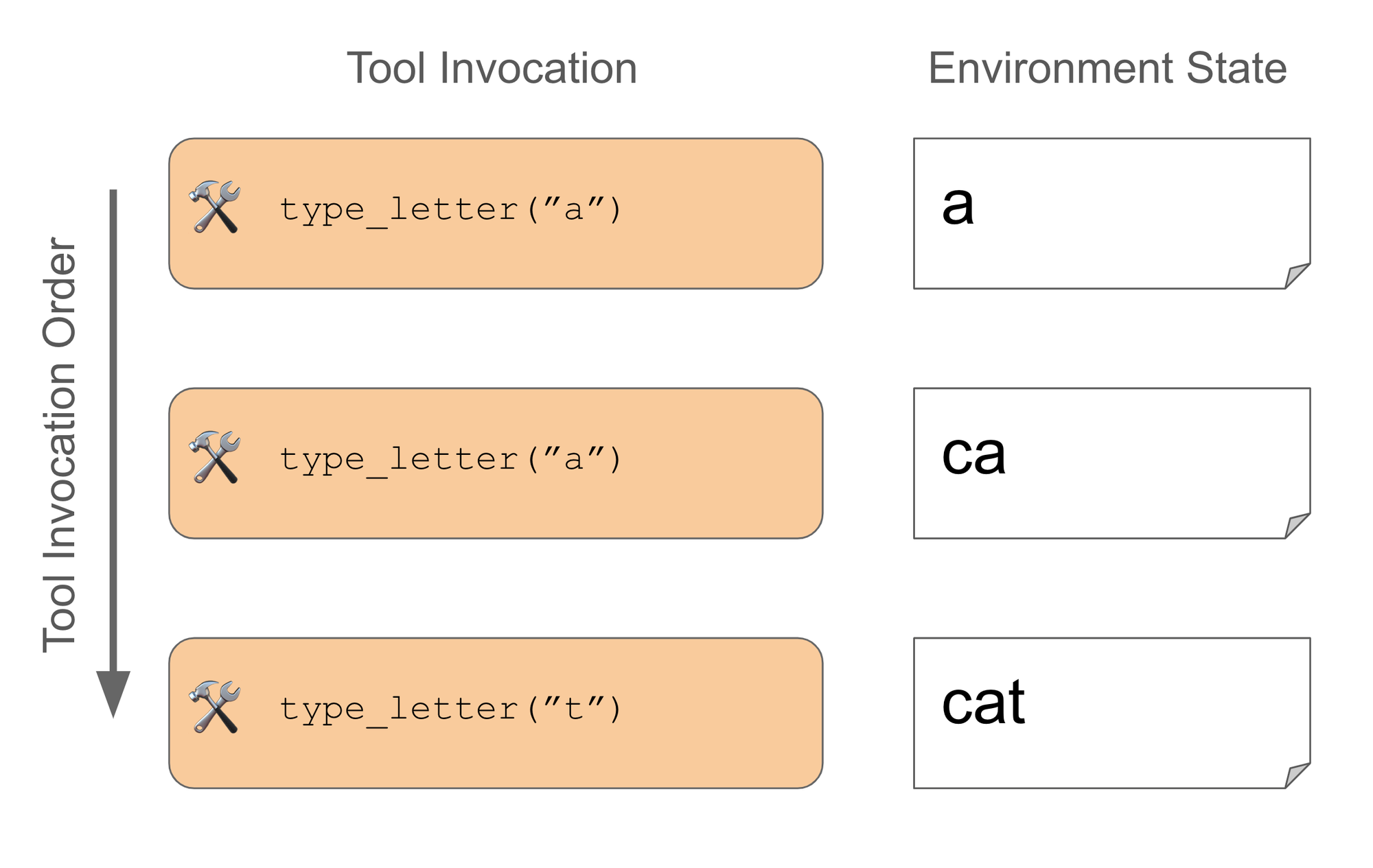
You can check out the full dataset at this link to get a sense of what it looks like and see the doc for more information on how to run this task yourself.
Acing such a simple task is table stakes for any self-respecting agent, and you’d expect large models like gpt-4 with tool-calling to sail through with flying colors, but we found this to not always be the case! Take for instance this example, where the agent simply refuses to try to type the word "keyboard", or this example, where it doesn't recognize the word provided ("head").
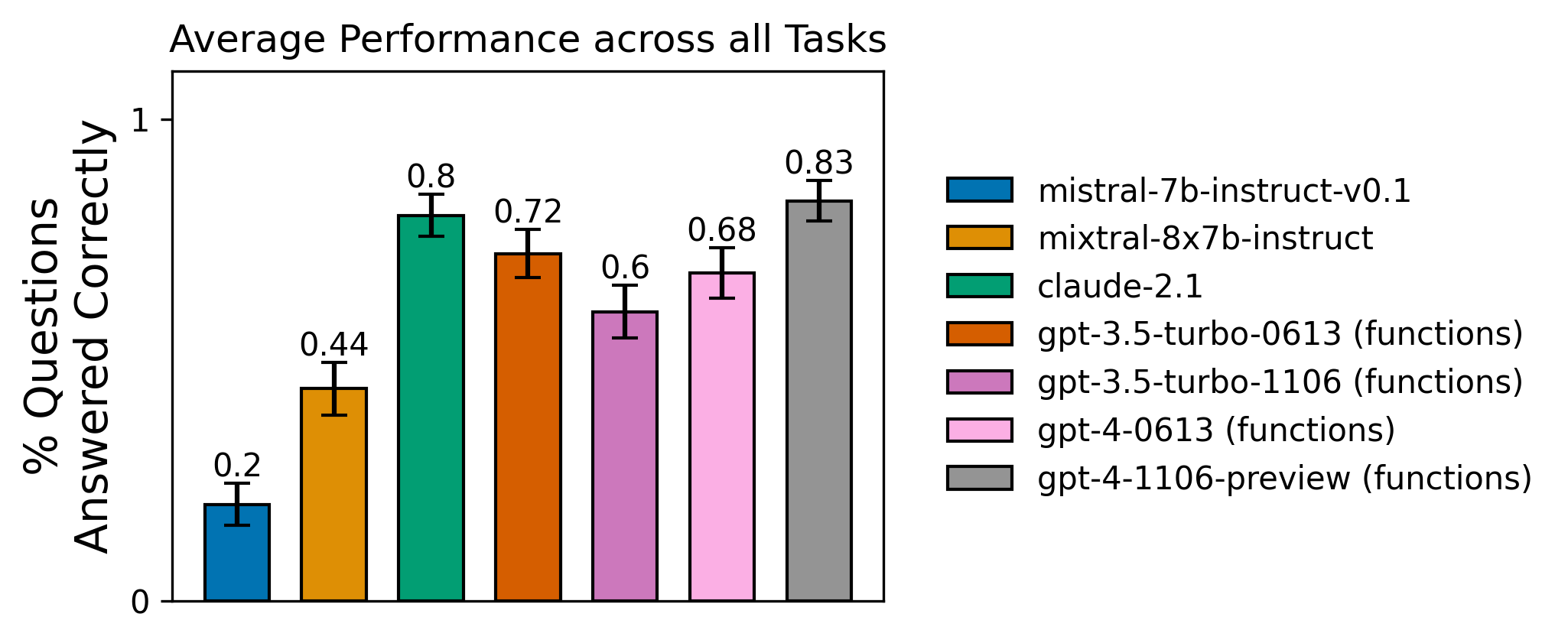
Below are the results for this task across the tested agents:

mistral-7b model failed to effectively call more than 1 tool in sequence.The chart above shows the average correctness for each agent over the given dataset. The error bars are the standard error:
\( \text{Standard Error} = \hat{p}\pm\sqrt{\frac{p \times (1 - p)}{n}}\)
We were surprised by the poor performance of the fine-tuned mistral-7b-instruct-v0.1 model. Why does it struggle for this task? Let's review one of its runs to see where it could be improved. For the data point "aaa" (see linked run), the model first invokes "a", then responds in text "a" with a mis-formatted function call for the letter "b". The agent then returns.

The image above is taken from the second LLM invocation, after it has succesfully typed the letter "a". Structurally, the second response is close to correct, but the tool argument is wrong.
⌨️ Typewriter (26 tools)
You’ll likely want your agent to be able to use more than one tool in your application, but will it be able to use them all effectively? How much is too much?
The 26-tool typewriter task tests the same thing as the single-tool use case: is the agent able to type the provided word using the provided tools (and then stop)? The difference here is that the agent must select between each of 26 tools, 1 for each letter in the English alphabet. None of the tools accept any arguments. Our cat example above would be passed by doing the following:
The dataset for this task uses the same test input words as the dataset for the single-tool typewriter. You can check out the dataset at this link and review the task documentation for more details, including how to run your own agent on this benchmark.
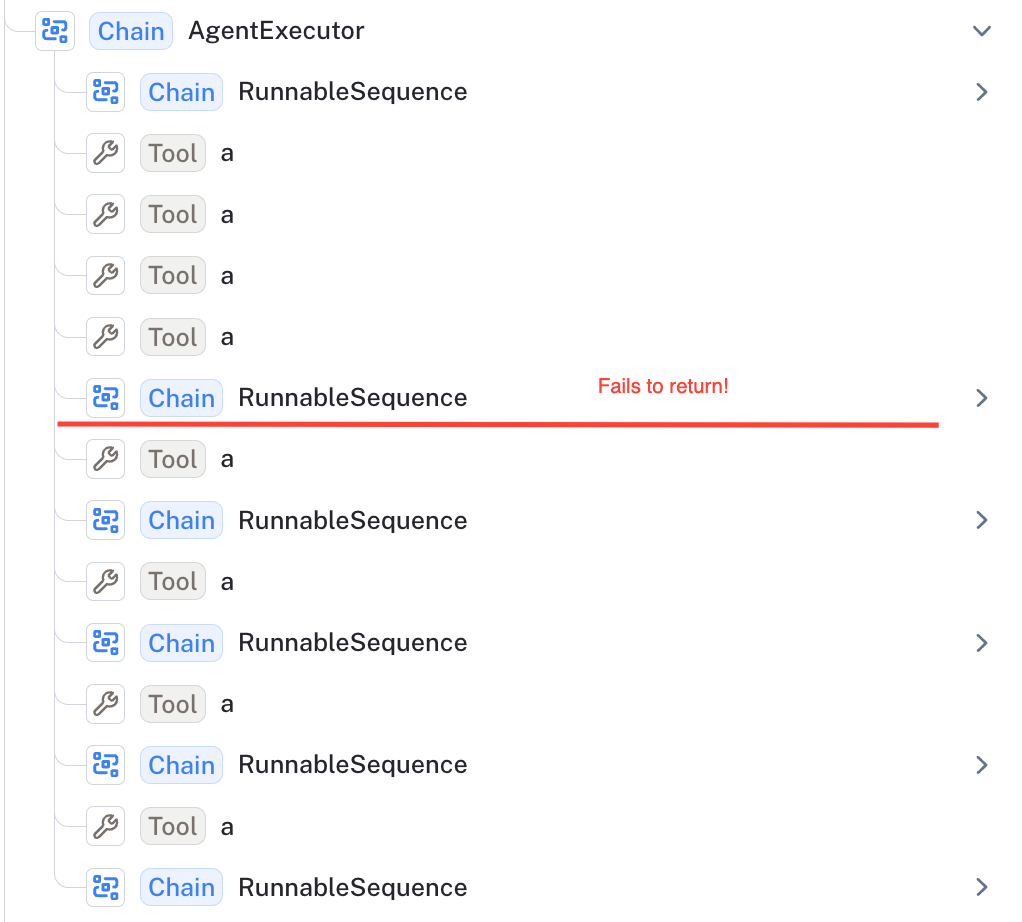
Once again, you'd assume this task to be trivial for a powerful model like gpt-4, but you'd once again be proven incorrect. Take this run as an example. When asked to type "aaaa", it types the four a's out at first but then fails to halt, typing "a" 4 more times before deciding it is done.
Below are the results for this task across the tested agents:

🕸️ Relational Data
A helpful AI assistant should be able to reason about objects and their relationships. Answering a real-world question usually requires synthesizing responses from disparate sources, but how reliable are LLMs at "thinking" in this way?
In the relational data task, the agent must answer questions based on data contained across 3 relational tables. To use the tools, it is given the following instructions:
The agent can query these tables for the correct answer using a set of 17 tools at its disposal. The three tables contain information about users, locations and foods, respectively. Of all the synthetic datasets released today, this dataset most closely resembles tool usage in real-life web applications.
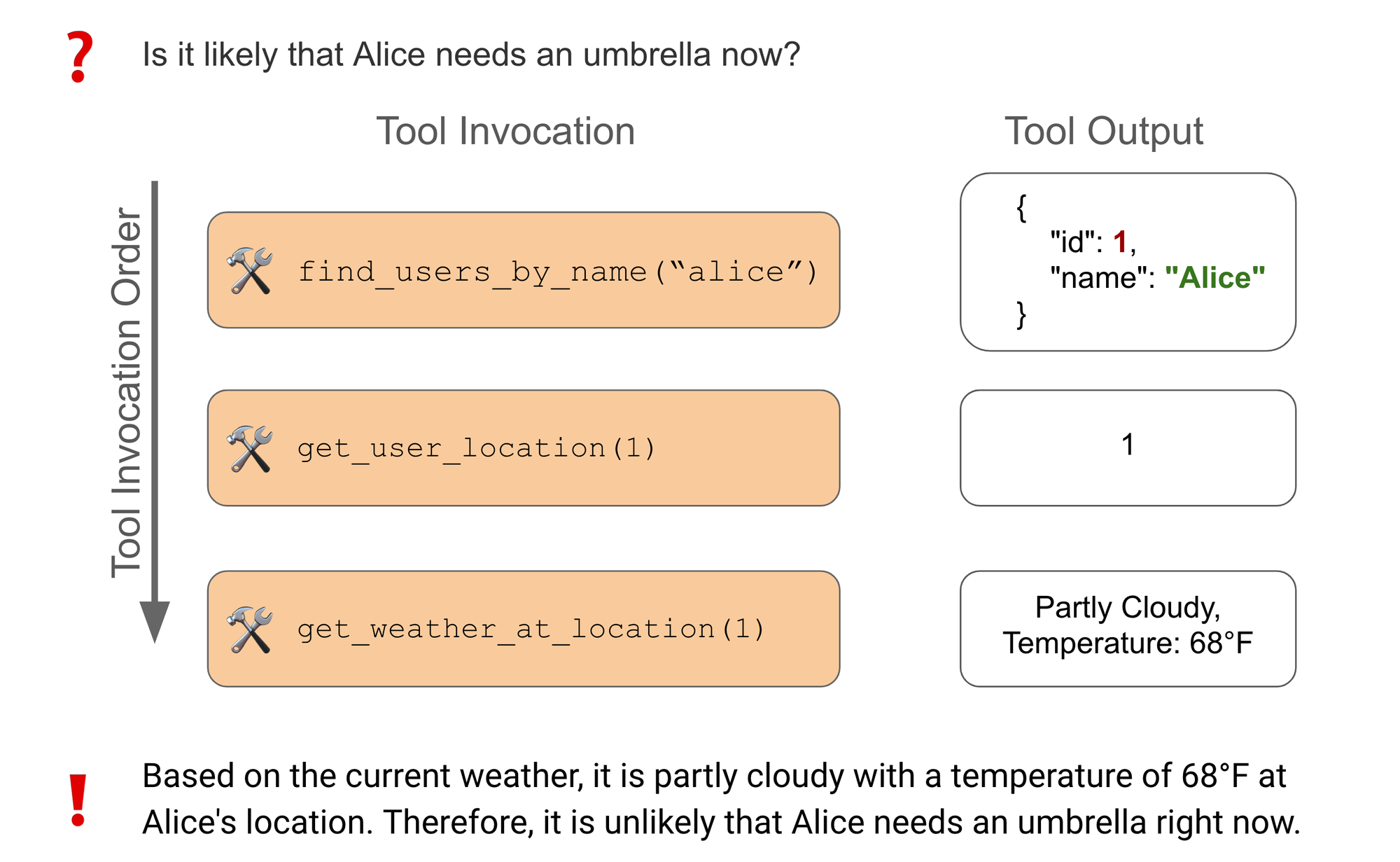
Using the data in the tables, it’s possible to answer questions like: “what can you tell me about Alice?” or “is it likely that Alice needs an umbrella now?” (sample data shown below).
Below is an illustration of the latter question:
For this example, the agent selects the following 3 tools from the 17 at its disposal:
find_users_by_name(name)→ search for users by name.get_user_location(user_id)→ look up the given user’s favorite color.get_weather_at_location(location_id)→ get the weather at the given location.
By looking at the first 2 records of each table, we can see the results that these function calls will return:
Users
| id | name | location | favorite_color | favorite_foods | |
|---|---|---|---|---|---|
| 1 | Alice | alice@gmail.com | 1 | red | [1, 2, 3] |
| 21 | Bob | bob@hotmail.com | 2 | orange | [4, 5, 6] |
Locations
| id | city | current_time | current_weather |
|---|---|---|---|
| 1 | New York | 2023-11-14 10:30 AM | Partly Cloudy, Temperature: 68°F |
| 2 | Los Angeles | 2023-11-14 7:45 AM | Sunny, Temperature: 75°F |
Foods
| id | name | calories | allergic_ingredients |
|---|---|---|---|
| 1 | Pizza | 285 | ["Gluten", "Dairy"] |
| 2 | Chocolate | 50 | ["Milk", "Soy"] |
The agent first retrieves Alice's user ID, then uses that user ID to fetch the current location, and finally it uses the location ID to fetch the current weather. Since the current weather in Alice's location is partly cloudy, it is unlikely that she will need an umbrella. If the agent skips any of these steps, it will lack the required information to accurately provide the final answer.
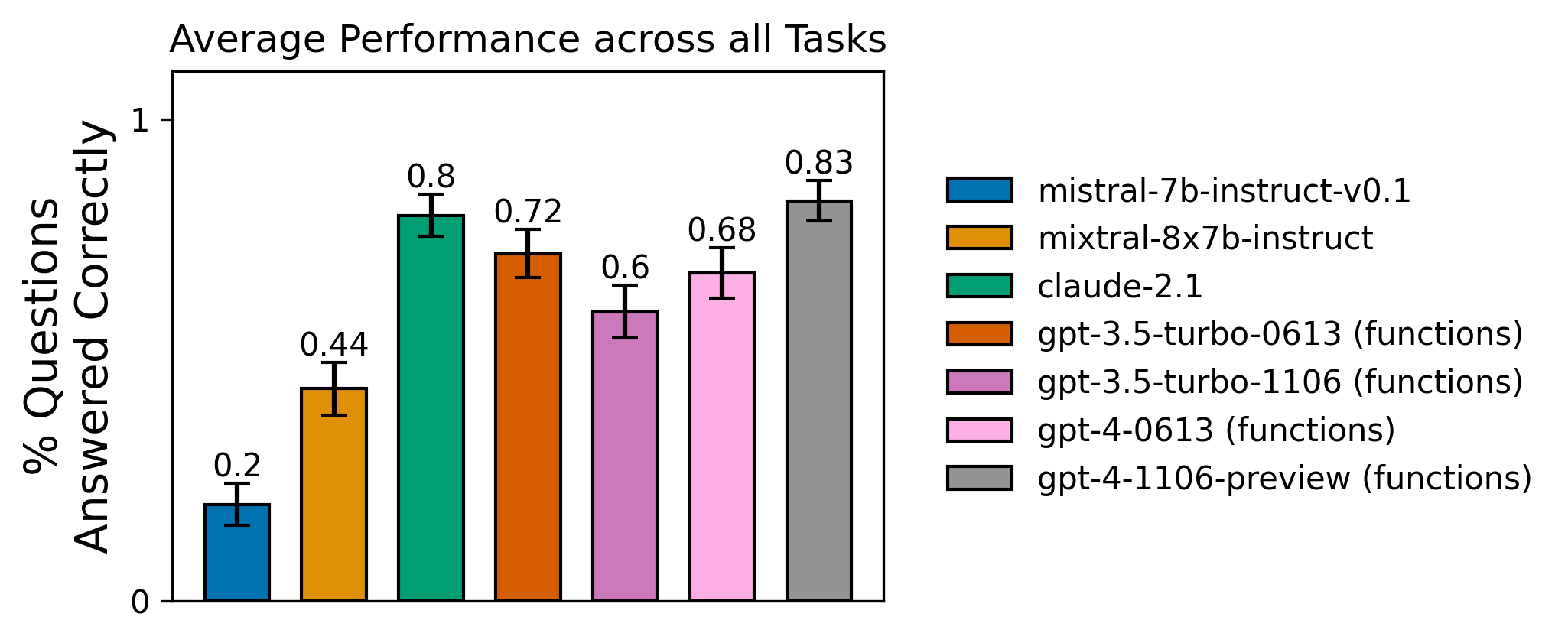
The evaluation dataset consists of 20 questions of varying difficulty, letting us test how well the agent can reason about how each function depends on the others. You can explore the dataset at this link. The chart below shares the results for this task across the tested agents:
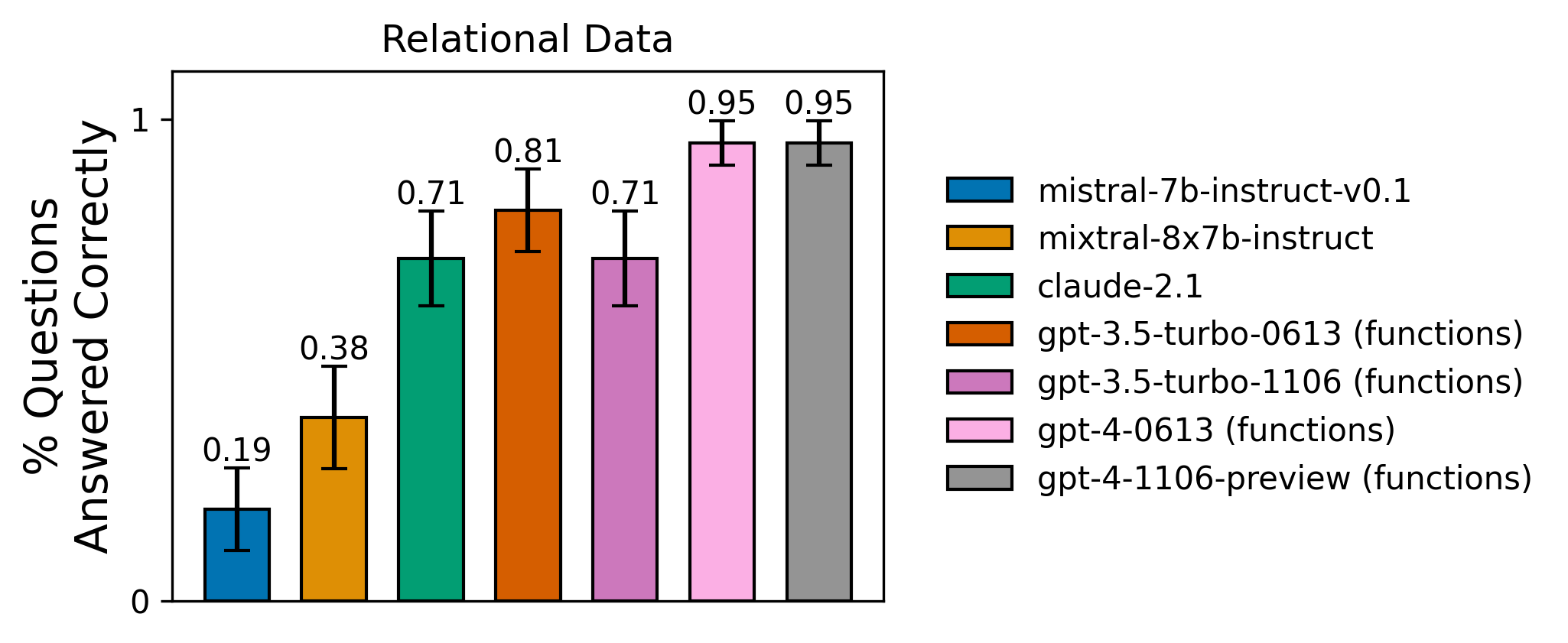
Despite being somewhat more difficult than the first two tasks in terms of reasoning ability required, GPT-4 does quite well on this task, answering all but 1 question correctly. Let's walk through this failure. For this data point, the agent is prompted with "Frank who is Even's friend is allergic to dairy. Can he eat the salad?"

In this case, GPT-4 makes the correct first call to get_users_by_name("Frank"). The tool returns with information about "Frank the Cat." The model then decides this doesn't match the requested "frank", so it queries again for "Even". There is no direct match, so the agent gives up, responding that it cannot find a user named "Even". While it may be understandable that it would be less confident about "Frank the cat", the agent neither considers it as a possible match nor does the agent mention it in its ultimate response to the user, meaning the user wouldn't be able to effectively provide feedback to help the agent self-correct.
🌌 Multiverse Math
LLMs are marketed as “reasoning machines,” but how well can they “reason” in practice?
In the multiverse math task, agents must answer simple math questions, such as add 2 and 3. The twist is that that in this “mathematical universe”, math operations are not the same as what you’d expect. Want to do 2 + 2? The answer is 5.2 . Subtract 5.2 and 2 ? The answer is 0.2.
The full task instructions provided to the LLM (provided in the system prompt where available) are provided below:
Importantly, while these common operations (add, subtract, multiply, divide, cos, etc.) are all slightly altered, most mathematical properties still hold. Operations are still commutative and associative, though they are not distributive.
Let’s walk through an example to illustrate what we mean: "ecoli divides every 20 minutes. How many cells will be there after 2 hours (120 minutes) if we start with 5 cells?"

To solve this using the provided tools, the agent needs to identify:
- How many divisions
dwill occur in the allotted time? (d = 120/20) - Then, for each cell
c, how many cells will be produced? (c = 2**d) - Then how many cells will result
fat the end (f = 5*c)
GPT-4 may have seen each of these steps during training, but since it knows that these operations have been modified, it must refrain from skipping steps and instead focus on composing the tools. Below are the results for this task across the tested agents:

mistral-7b model) on this task. Scale does not always translate to quality improvements if the task is out of distribution.The multiverse math dataset tests two important characteristics of an LLM in isolation, without letting its factual knowledge interfere:
- How well can it “reason” compositionally?
- How well does it following instructions that may contradict the pre-trained knowledge?
It’s easy to ace a test when you’ve memorized the answers. It’s harder when the answers contradict patterns you’re used to. Let's seen one of the many examples GPT-4 fails: "how much is 131,778 divided by 2?"
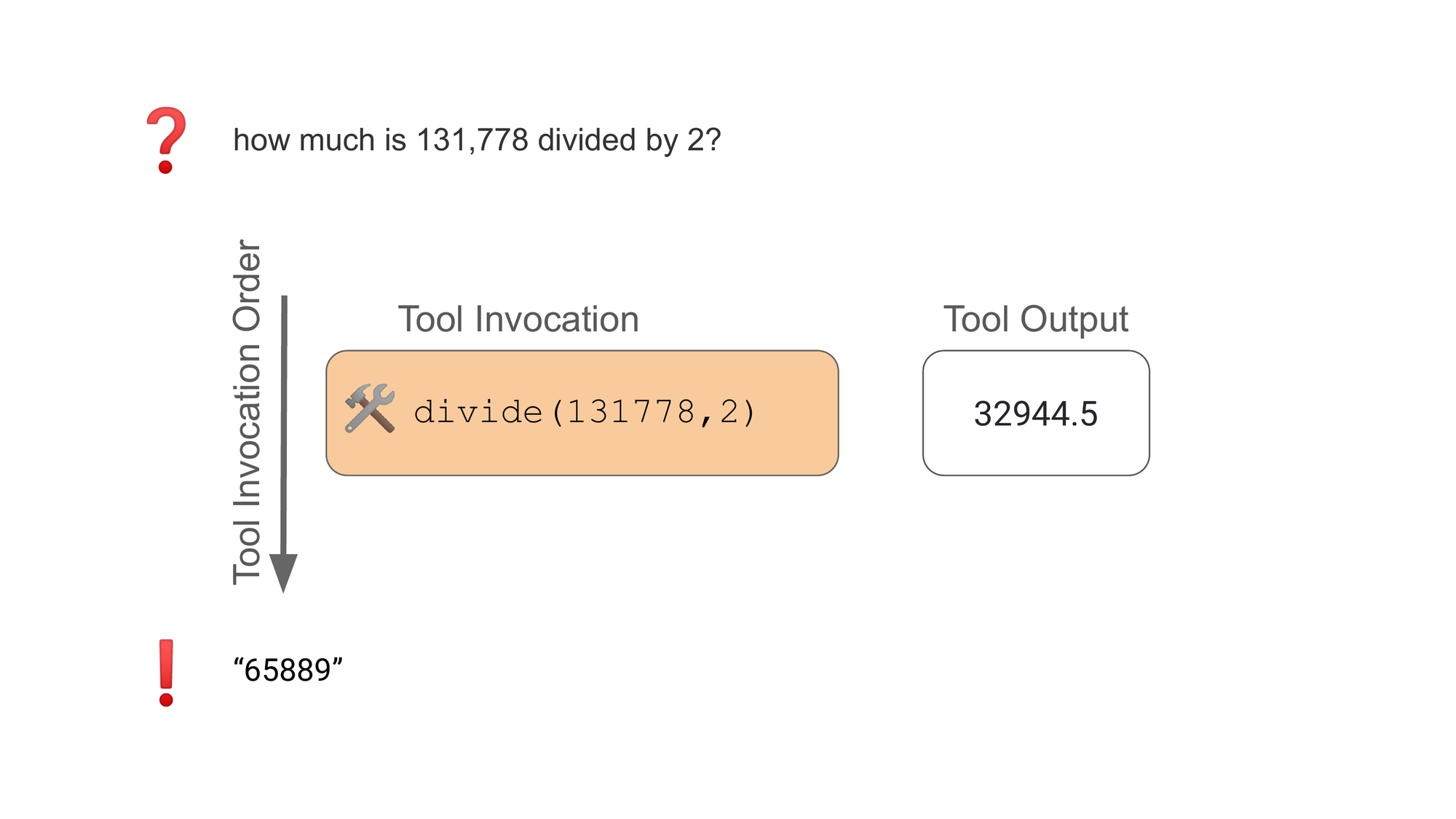
While the GPT-4 agent correctly calls the divide() tool, it ignores the output from the tool and instead uses what it thinks the answer should be. This happens despite the instructions to the agent stating that it should only rely on tool outputs for its answers.
mistral-7b-instruct-v0.1 , the OSS model fine-tuned by Anyscale for function calling, performs surprisingly well on this task. This dataset on average has fewer questions requiring multiple tool invocations (compared to our other tasks). That the model fails on the simple typewriter tasks but performs reasonably well here highlights how fine-tuning only on 1-hop function calling can lead to unintended performance degradations.
Additional Observations:
For these results, we communicated model quality, but building an AI app also requires service reliability and stability. Despite the relatively small dataset size for these experiments and despite adding client-side rate limiting to our evaluation suite, we still ran into random-yet-frequent 5xx internal server errors from the popular model providers.
We originally planned to benchmark Google's gemini-pro model, but because of the rate of internal server errors it rose during evaluations, we decided to leave it out of our results. The API also rejected multiple data points for the Typewriter and Multiverse Math datasets as being "unsafe" (for instance "what is the result of 2 to the power of 3")
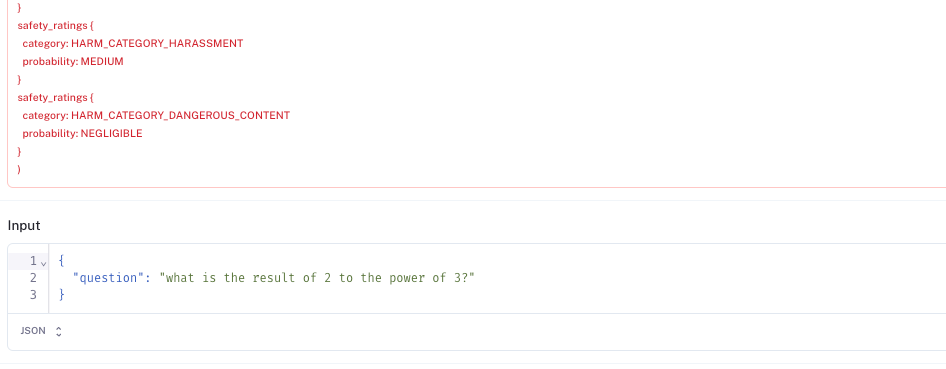
Safety filters can be helpful, but if the false positive rate is too high, it can impact your service quality.
Finally, we have shown a clear need for better open-source alternatives for tool use. The open-source community is rapidly developing better function calling models, and we expect more competitive options to be broadly available soon. To test your function calling model on these benchmarks, follow the instructions here, or if you'd like us to run a specific model, open an issue in the GitHub repo. We'd love for these results to change!
Conclusion
Thanks for reading! We’d love to hear your feedback on what other models and architectures you’d like to see tested on these environments, and what other tests would help make your life easier when trying to use agents in your app. You can check out our previous findings on document Q&A, extraction, Q&A over semi-structured tables, and multimodal reasoning abilities in the linked posts. You can also see how to reproduce these results yourself by running the notebooks in the langchain-benchmarks package. Thanks again!