We think the LangChain Expression Language (LCEL) is the quickest way to prototype the brains of your LLM application. The next exciting step is to ship it to your users and get some feedback! Today we're making that a lot easier, launching LangServe. LangServe is the easiest and best way to deploy any any LangChain chain/agent/runnable.
Important Links:
- LangServe Github Repo
- Example repo (deploy on GCP)
- Replit Template
Why it exists
Whether you’re building a customer-facing chatbot, or an internal tool powered by LLMs, you’ll probably start by building a prototype (maybe in a Jupyter notebook), and iterate on it until it’s good enough to get people using it.
And that’s where LangServe comes in, we’ve taken our experience scaling applications in production, and made it available as a python package you can use for your own LLM apps.
+ LCEL = Prototype
+ LangServe = Production-ready API
+ [Hosting Provider] = Live deployment
+ LangSmith Tracing = Monitor your production deployment
We've been hesitant to release anything around deployment because, to be honest, we weren't entirely sure what value we could add. With some key improvements and additions over the past few months, we now believe that LangServe can provide real value. Most of the features we highlight in the release today make it significantly easier to go from prototype to production and get a production ready API. Over next few weeks, we'll be adding more features that add in new functionality (as opposed to just making it easier to create an API).
We've used LangServe to deploy ChatLangChain and WebLangChain over the past week, and this has help battle test it.
The road to LangServe
The journey to build LangServe really started a few months ago when we launched LCEL and the Runnable protocol. This was designed from day 1 to support putting prototypes in production, with no code changes, from the simplest “prompt + LLM” chain to the most complex chains (we’ve seen folks successfully running in production LCEL chains with 100s of steps). To highlight a few:
- first-class support for streaming: when you build your chains with LCEL you get the best possible time-to-first-token (time elapsed until the first chunk of output comes out). For some chains this means eg. we stream tokens straight from an LLM to a streaming output parser, and you get back parsed, incremental chunks of output at the same rate as the LLM provider outputs the raw tokens. We’re constantly improving streaming support, recently we added a streaming JSON parser, and more is in the works.
- first-class async support: any chain built with LCEL can be called both with the synchronous API (eg. in your Jupyter notebook while prototyping) as well as with the asynchronous API (eg. in a LangServe server). This enables using the same code for prototypes and in production, with great performance, and the ability to handle many concurrent requests in the same server.
- optimized parallel execution: whenever your LCEL chains have steps that can be executed in parallel (eg if you fetch documents from multiple retrievers) we automatically do it, both in the sync and the async interfaces, for the smallest possible latency.
- support for retries and fallbacks: more recently we’ve added support for configuring retries and fallbacks for any part of your LCEL chain. This is a great way to make your chains more reliable at scale. We’re currently working on adding streaming support for retries/fallbacks, so you can get the added reliability without any latency cost.
- accessing intermediate results: for more complex chains it’s often very useful to access the results of intermediate steps even before the final output is produced. This can be used let end-users know something is happening, or even just to debug your chain. We’ve added support for streaming intermediate results, and it’s available on every LangServe server.
- input and output schemas: this week we launched input and output schemas for LCEL, giving every LCEL chain Pydantic and JSONSchema schemas inferred from the structure of your chain. This can be used for validation of inputs and outputs, and is an integral part of LangServe.
To this ever-growing list of the benefits of building with LCEL today we’re adding LangServe, which takes advantage of all these to give you the fastest path from LLM idea to scalable LLM app in production.
How it works
First we create our chain, here using a conversational retrieval chain, but any other chain would work. This is the my_package/chain.py file.
"""A conversational retrieval chain."""
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
vectorstore = FAISS.from_texts(
["cats like fish", "dogs like sticks"],
embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
model = ChatOpenAI()
chain = ConversationalRetrievalChain.from_llm(model, retriever)Then, we pass that chain to add_routes. This is the my_package/server.py file.
#!/usr/bin/env python
"""A server for the chain above."""
from fastapi import FastAPI
from langserve import add_routes
from my_package.chain import chain
app = FastAPI(title="Retrieval App")
add_routes(app, chain)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)That's it! This gets you a scalable python web server with
- Input and Output schemas automatically inferred from your chain, and enforced on every API call, with rich error messages
/docsendpoint serves API docs with JSONSchema and Swagger (insert example link)/invokeendpoint that accepts JSON input and returns JSON output from your chain, with support for many concurrent requests in the same server/batchendpoint that produces output for several inputs in parallel, batching calls to LLMs where possible/streamendpoint that sends output chunks as they become available, using SSE (same as OpenAI Streaming API)/stream_logendpoint for streaming all (or some) intermediate steps from your chain/agent- Built-in (optional) tracing to LangSmith, just add your API key as an environment variable
- Support for hosting multiple chains in the same server under separate paths
- All built with battle-tested open-source Python libraries like FastAPI, Pydantic, uvloop and asyncio.
Deployment
After an API is created, the next step is to deploy it on a hosting platform. We're launching with two examples:
- GCP: Deploy to GCP Cloud Run with one command.
- Replit: Deploy (and also build) on Replit. This can be done by cloning an existing Github repo.
We will add instructions and templates for other platforms. If you have suggestions for what you want to see, please let us know.
See it in action
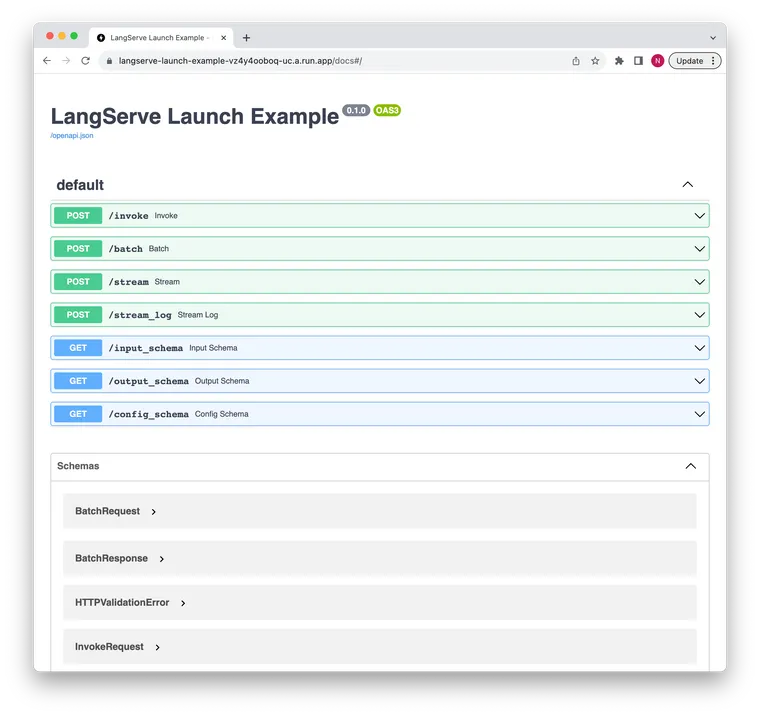
Let's see it in action. We have deployed this repo as an example.
The API docs are available here.
We can stream a response:
curl https://langserve-launch-example-vz4y4ooboq-uc.a.run.app/stream -X POST -H "Content-Type: application/json" --data '{"input": {"topic": "bears"}}'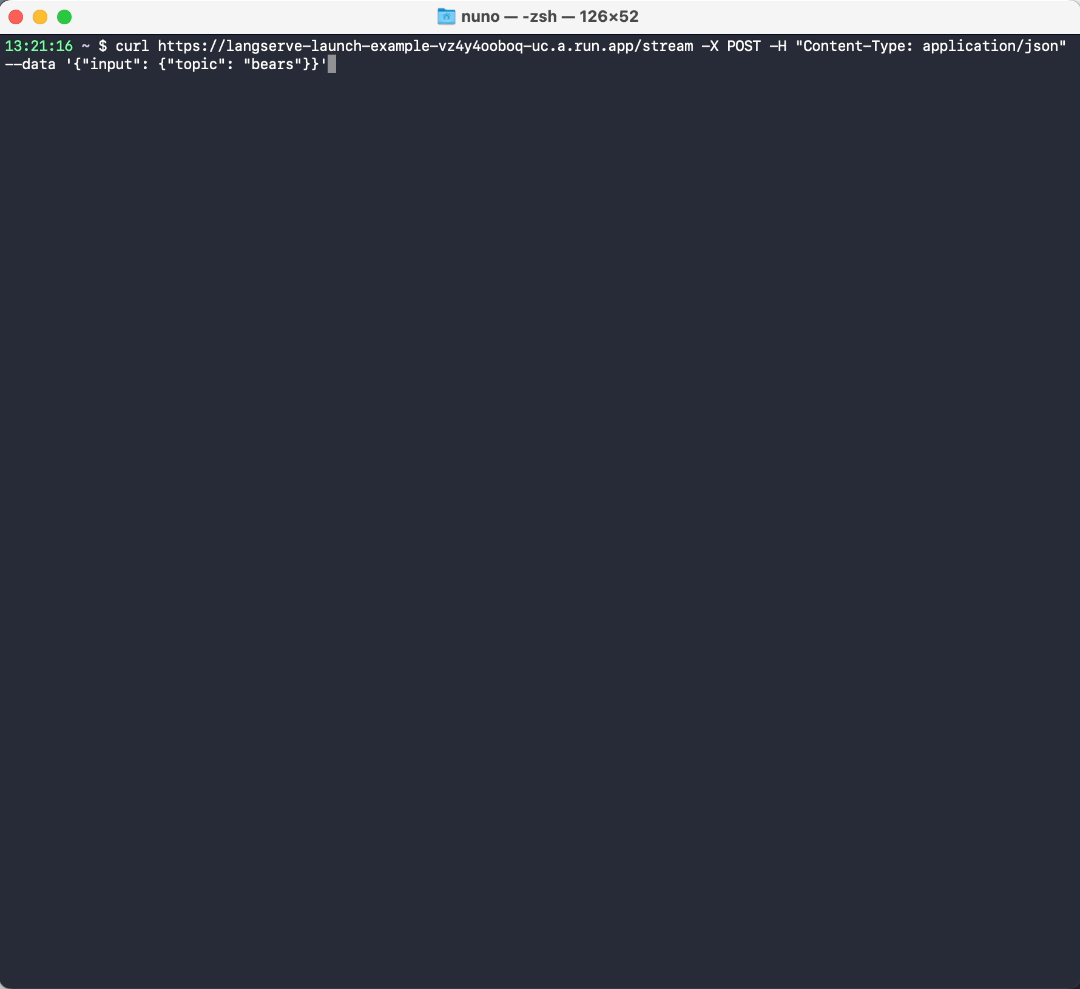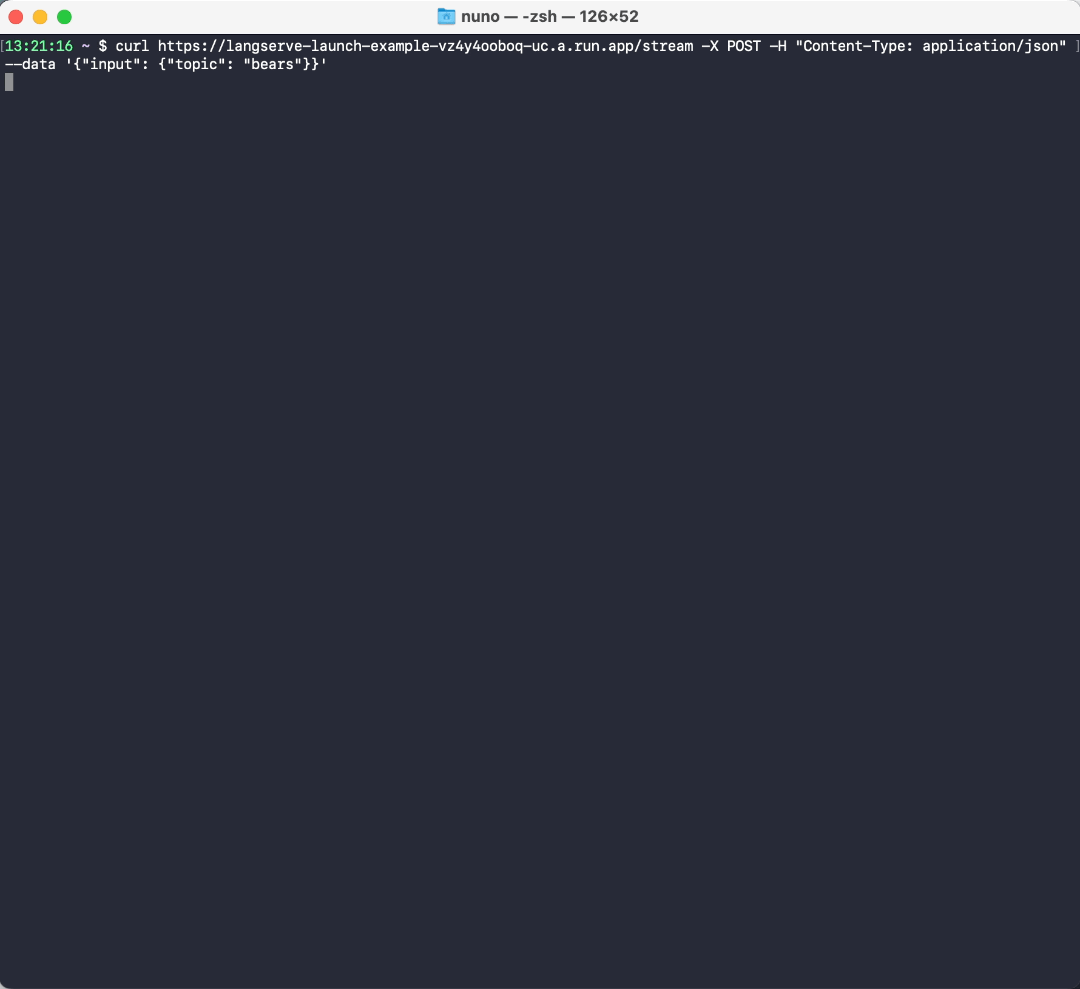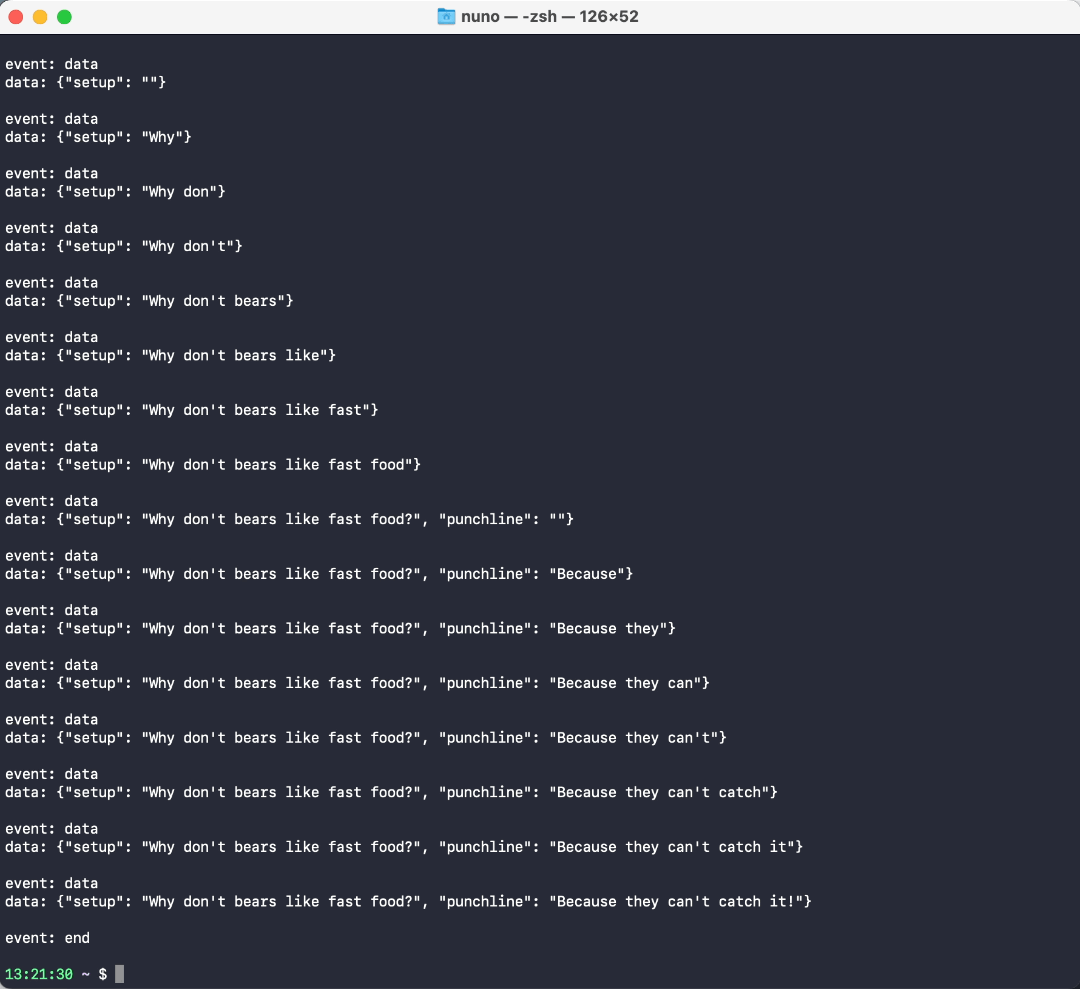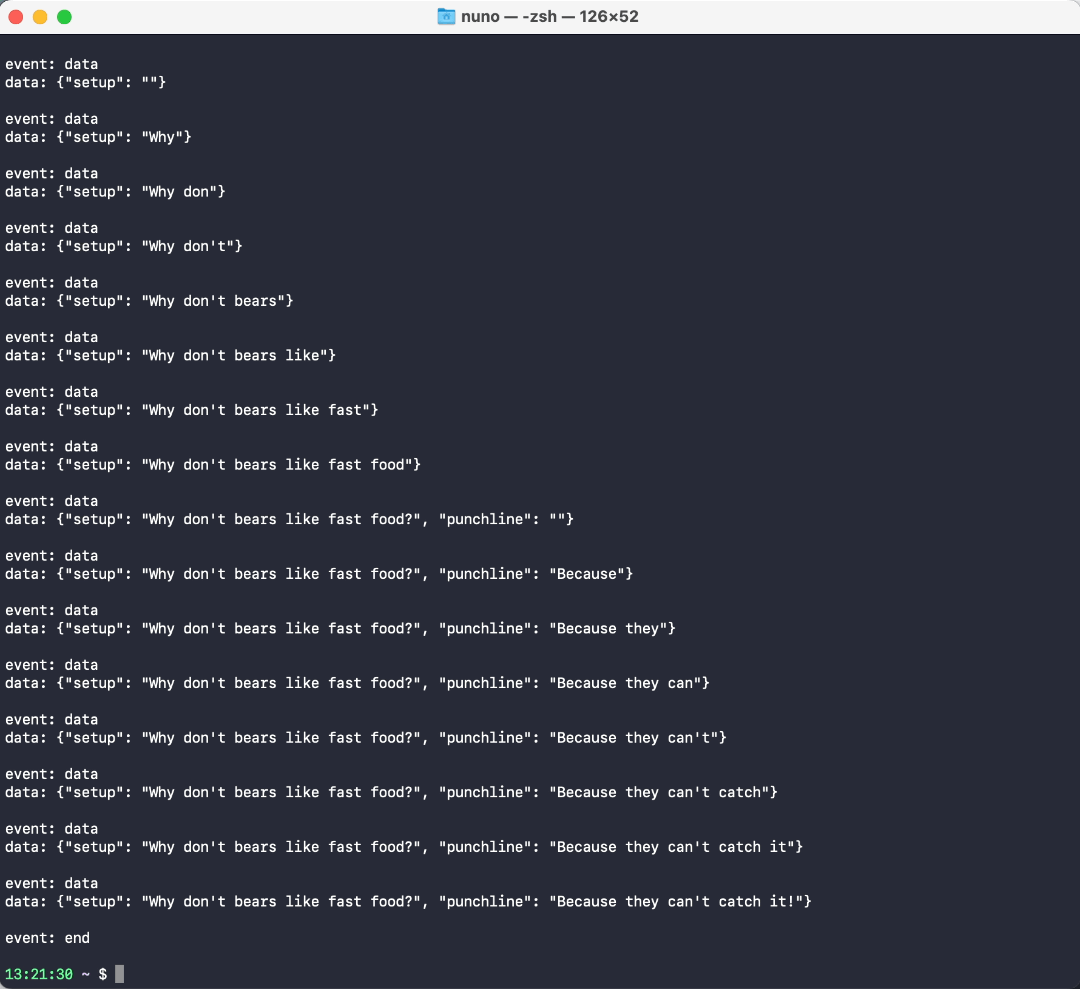
What's next
We're always improving LangChain/LCEL, just recently we've added support for input and output schemas, streaming intermediate results, and a streaming JSON parser.
We'll also be working to add features over the next few weeks: the next two we are adding are (1) a playground to experiment with different prompts/retrievers for deployed chains, (2) a way to save multiple configurations for the same chain.
Let us know what you'd like to see next!