
Another year of building with LLMs is coming to an end — and 2024 didn’t disappoint. With nearly 30k users signing up for LangSmith every month, we’re lucky to have front row seats to what’s happening in the industry.
As we did last year, we want to share some product usage patterns that showcase how the AI ecosystem and practice of building LLM apps are evolving. As folks have traced, evaluated, and iterated their way around LangSmith, we’ve seen a few notable changes. These include the dramatic rise of open-source model adoption and a shift from predominantly retrieval workflows to AI agent applications with multi-step, agentic workflows.
Dive into the stats below to learn exactly what developers are building, testing, and prioritizing.
Infrastructure usage
With Large Language Models (LLMs) eating the world, everyone’s asking the mirror-mirror-on-the-wall question: “Which model is the most utilized of them all?” Let’s unpack what we’ve seen.
Top LLM providers
Like last year’s results, OpenAI reigns as the most used LLM provider among LangSmith users — used more than 6x as much as Ollama, the next-most popular provider (counted by LangSmith organization usage).
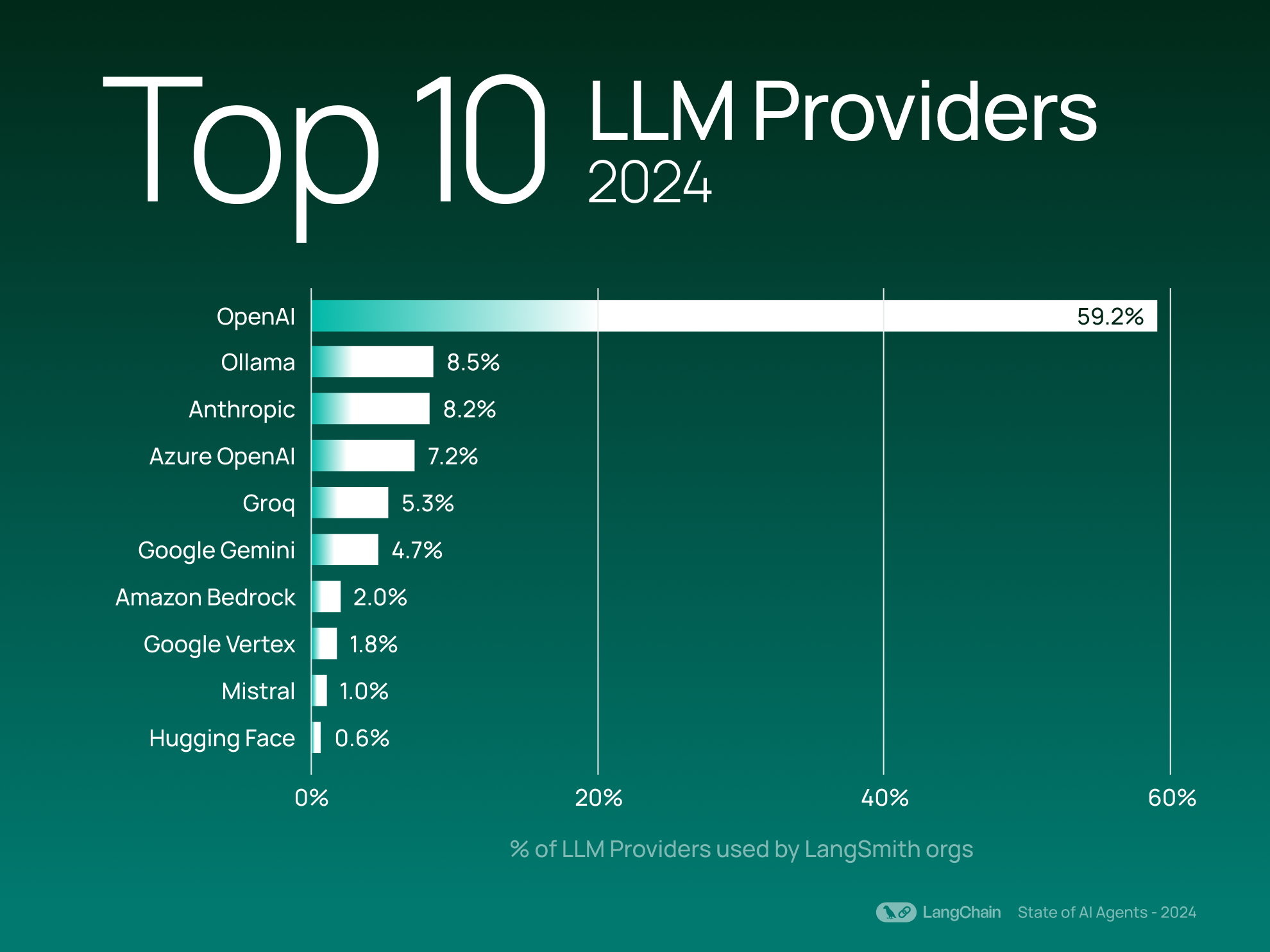
Interestingly, Ollama and Groq (which both allow users to run open source models, with the former focusing on local execution and the latter on cloud deployment) have accelerated in momentum this year, breaking into the top 5. This shows a growing interest in more flexible deployment options and customizable AI infrastructure.

When it comes to providers that offer open-source models, the top providers have stayed relatively consistent compared to last year - Ollama, Mistral, and Hugging Face have made it easy for developers to run open source models on their platforms. These OSS providers’ collective usage represents 20% of the top 20 LLM providers (by the number of organizations using them).
Top Retrievers / Vector Stores
Performing retrieval is still critical for many GenAI workflows. The top 3 vector stores have remained the same as last year, with Chroma and FAISS as the most popular choices. This year, Milvus, MongoDB, and Elastic’s vector databases have also entered the top 10.

Building with LangChain products
As developers have gained more experience utilizing generative AI, they are also building more dynamic applications. From the growing sophistication of workflows, to the rise of AI agents — we’re seeing a few trends that point to an evolving ecosystem of innovation.

Observability isn’t limited to LangChain applications
While langchain (our open source framework) is central to many folks’ LLM app development journeys, 15.7% of LangSmith traces this year come from non-langchain frameworks. This reflects a broader trend where observability is needed regardless of what framework you’re using to build the LLM app — and that interoperability is supported by LangSmith.
Python remains dominant, while JavaScript usage grows
Debugging, testing, and monitoring certainly has a special place in our Python developers’ hearts, with 84.7% usage coming from the Python SDK. But there is a notable and growing interest in JavaScript as developers pursue web-first applications — the JavaScript SDK accounts for 15.3% of LangSmith usage this year, increasing 3x compared to the previous year.
AI agents are gaining traction
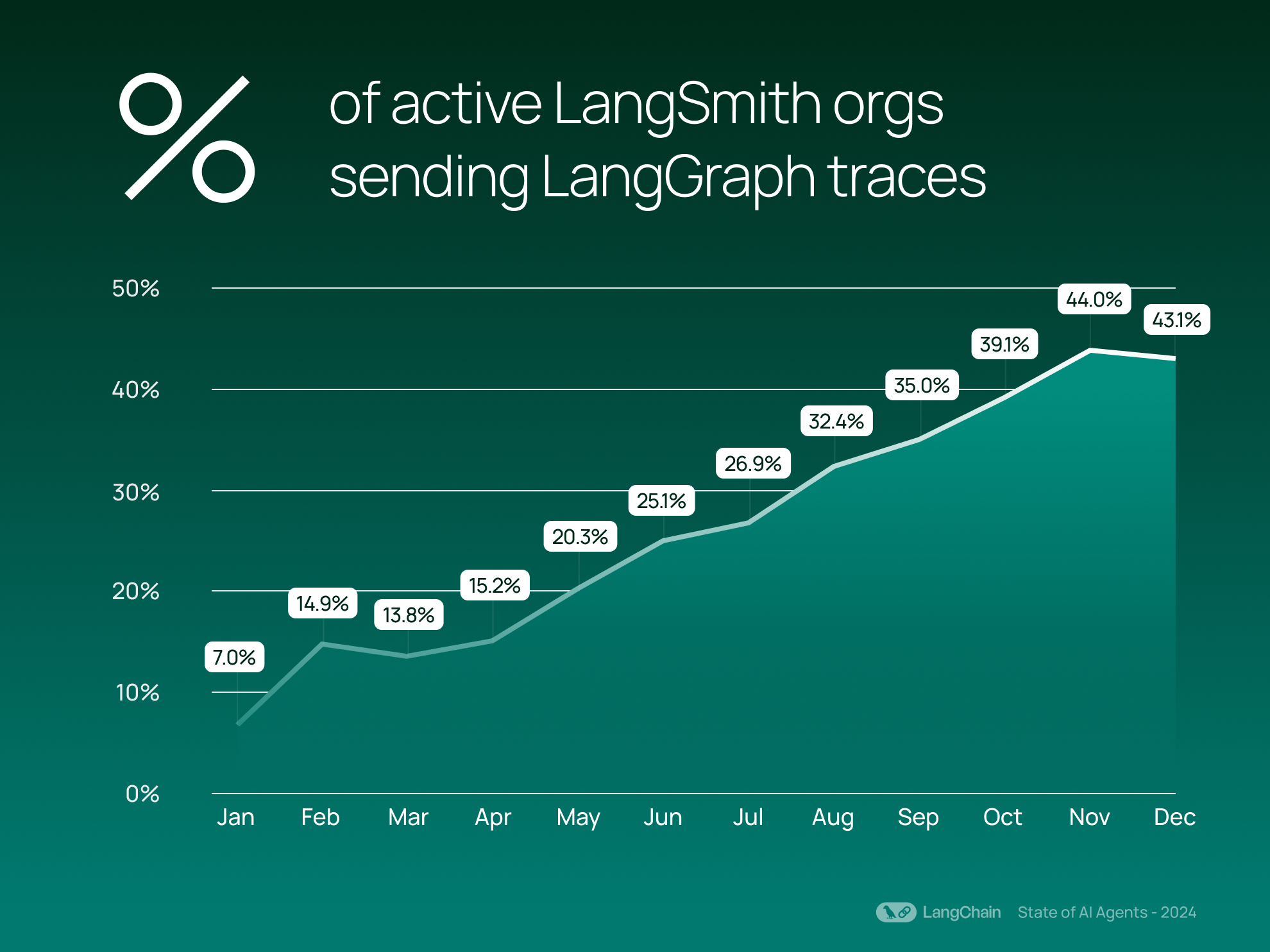
As companies are getting more serious about incorporating AI agents across various industries, adoption of our controllable agent framework, LangGraph, is also on the rise. Since its release in March 2024, LangGraph has steadily gained traction — with 43% of LangSmith organizations are now sending LangGraph traces. These traces represent complex, orchestrated tasks that go beyond basic LLM interactions.
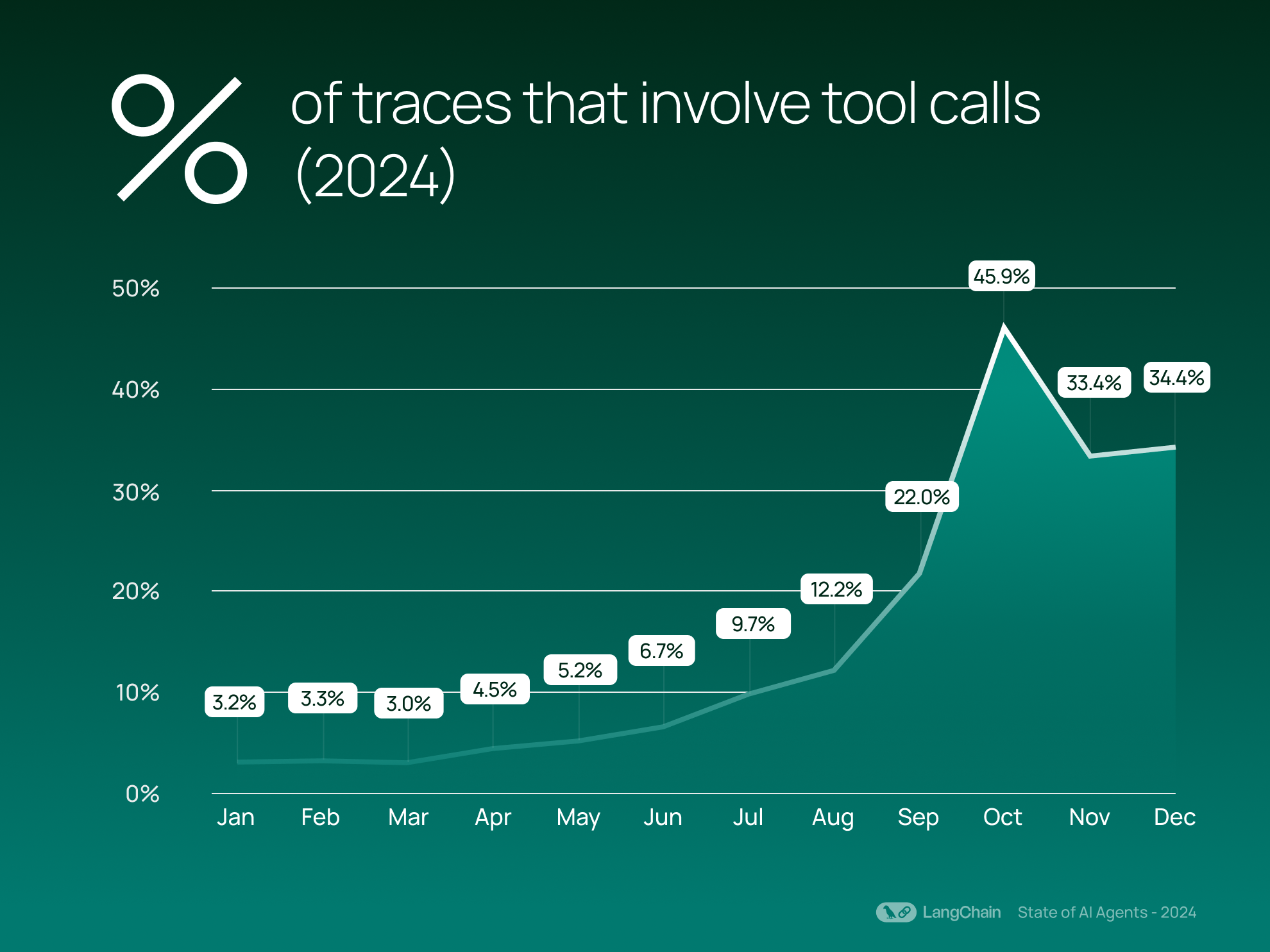
This growth aligns with the rise in agentic behavior: we see that on average 21.9% of traces now involve tool calls, up from an average of 0.5% in 2023. Tool calling allows a model to autonomously invoke functions or external resources, signaling more agentic behavior where the model decides when to take action. Increased use of tool calling can enhance an agent’s ability to interact with external systems and perform tasks like writing to databases.
Performance and optimization
Balancing speed and sophistication is a key challenge when developing applications — especially those leveraging LLM resources. Below, we explore how organizations are interacting with their applications to align the complexity of their needs with efficient performance.
Complexity is growing, but tasks are being handled efficiently
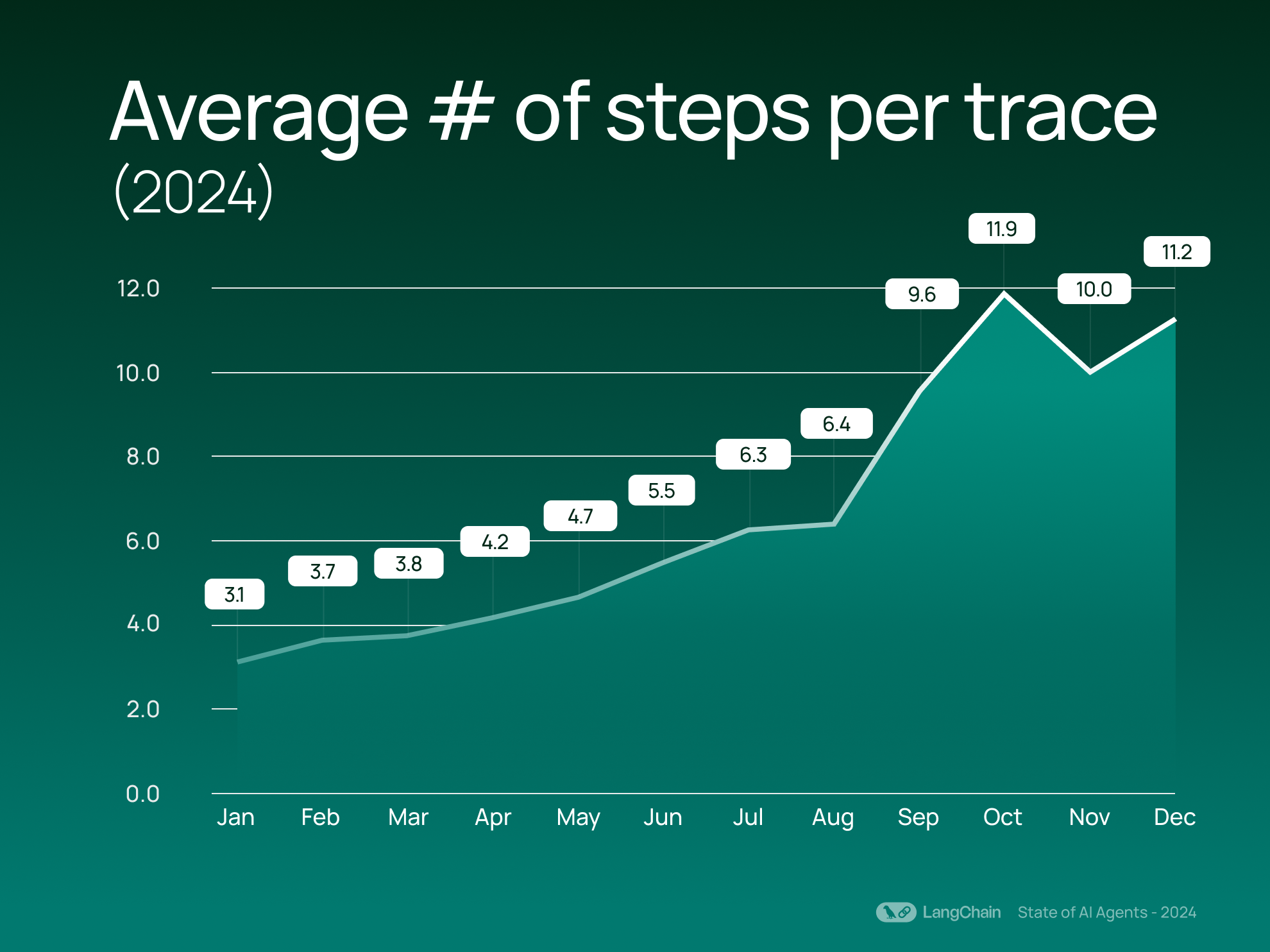
The average number of steps per trace has more than doubled over the past year, rising from on average 2.8 steps (2023) to 7.7 steps (2024). We define a step as a distinct operation within a trace, such as a call to an LLM, retriever, or tool. This growth in steps signals that organizations are leveraging more complex and multi-faceted workflows. Rather than a simple question-answer interaction, users are building systems that chain together multiple tasks, such as retrieving information, processing it, and generating actionable results.
In contrast, the average number of LLM calls per trace has grown more modestly— from on average 1.1 to 1.4 LLM calls. This speaks to how developers are designing systems to achieve more with fewer LLM calls, balancing functionality while keeping expensive LLM requests in check
LLM testing & evaluation
What are organizations doing to test their LLM applications to guard against inaccurate or low-quality LLM-generated responses? While it’s no easy feat to keep the quality of your LLM app high, we see organizations using LangSmith’s evaluation capabilities to automate testing and generate user feedback loops to create more robust, reliable applications.
LLM-as-Judge: Evaluating what matters
LLM-as-Judge evaluators capture grading rules into an LLM prompt and use the LLM to score whether the output adheres to specific criteria. We see developers testing for these characteristics the most: Relevance, Correctness, Exact Match, and Helpfulness
These highlight that most developers are doing coarse checks for response quality to make sure AI generated outputs don’t completely miss the mark.

Iterating with human feedback
Human feedback is a key part of the iteration loop for folks building LLM apps. LangSmith speeds up the process of collecting and incorporating human feedback on traces and runs (i.e. spans) – so that users can create rich datasets for improvement and optimization. Over the past year, annotated runs grew 18x, scaling linearly with growth in LangSmith usage.
Feedback volume per run also increased slightly, rising from 2.28 to 2.59 feedback entries per run. Still, feedback is relatively sparse per run. Users may be prioritizing speed in reviewing runs over providing comprehensive feedback, or commenting on only the most critical or problematic runs that need attention.
Conclusion
In 2024, developers leaned into complexity with multi-step agents, sharpened efficiency by doing more with fewer LLM calls, and added quality checks to their apps using methods of feedback and evaluation. As more LLM apps are created, we’re excited to see how folks dig into smarter workflows, better performance, and stronger reliability.
Learn more here about how LangSmith can bring more visibility into your LLM app development and improve performance over time — from debugging bottlenecks to evaluating response quality to monitoring regressions.