
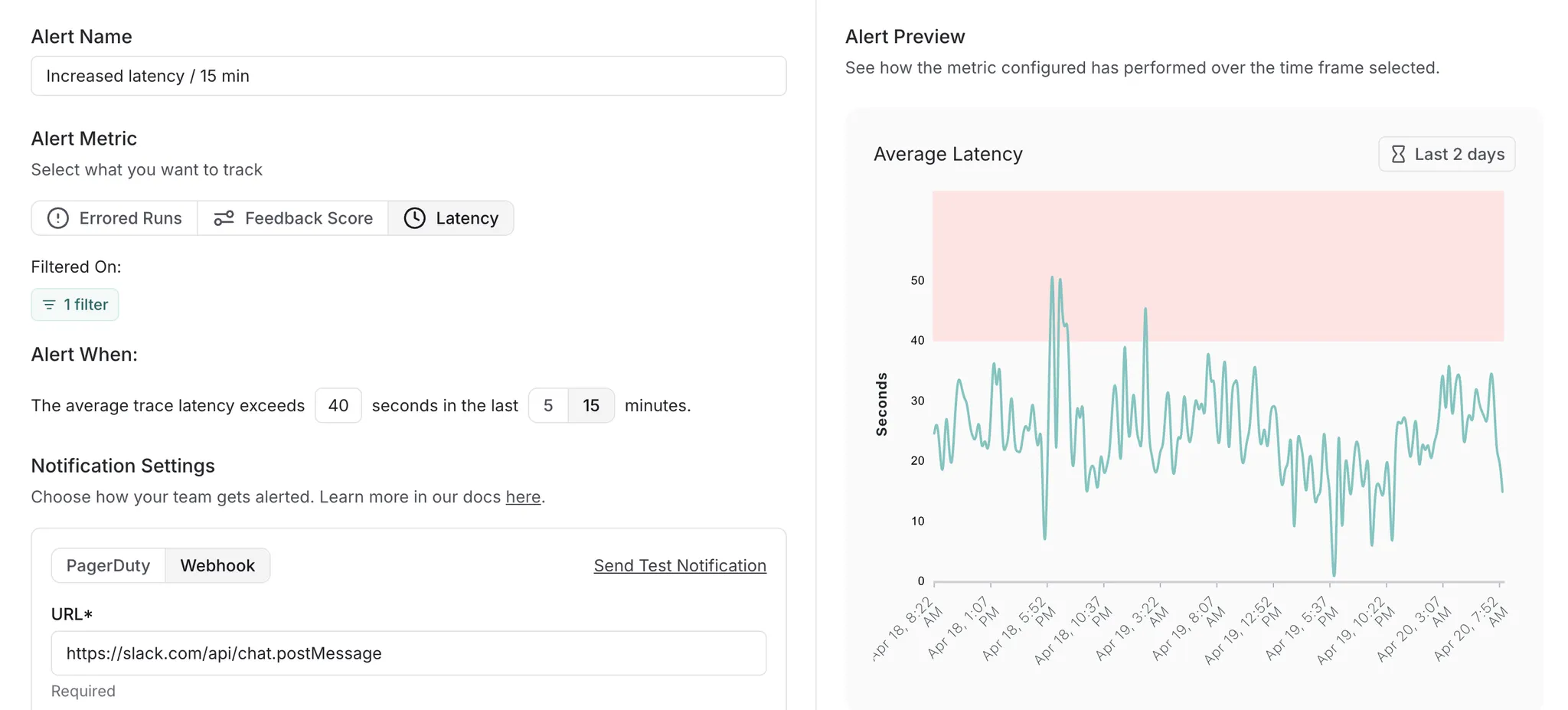
Great user experiences start with reliable applications. That’s why catching failures before they reach your users is key. To help you stay ahead, we’ve launched Alerts in LangSmith— making it easier to monitor your LLM apps and agents in real time.
We now support setting alerts based on key metrics like error rate, run latency, and feedback scores.
If you’re already sending production traces to LangSmith, you can set up your first alert today. New to tracing? Get started with tracing in LangSmith.
Why proactive monitoring matters
Monitoring and alerting are critical for any production app— but LLM-powered applications bring unique challenges, which primarily fall into two categories:
Dependence on External Services:
Agentic apps inherently rely on numerous dependencies — you might use one (or many) model providers and have a number of tools such as APIs, web search services, and databases available to your agent. Outages, rate limits, or increased latency from these dependencies can significantly degrade user experience. Proactive monitoring helps you identify these issues quickly.
Quality & Correctness
User experience isn't just about speed; it's also about the quality of the LLM's output. LLMs don't always behave predictably— small changes in prompts, models, or inputs can unexpectedly impact results.
Prompts that perform well in controlled evaluations can also sometimes regress in real-world scenarios due to differences in user interactions. Alerts based on feedback scores (from user input or online evaluations) provide an early warning system for these quality dips.
LangSmith Alerts Overview
LangSmith supports alerting on the following metrics:
- Error Count and Rate
- Average Latency
- Average Feedback Score
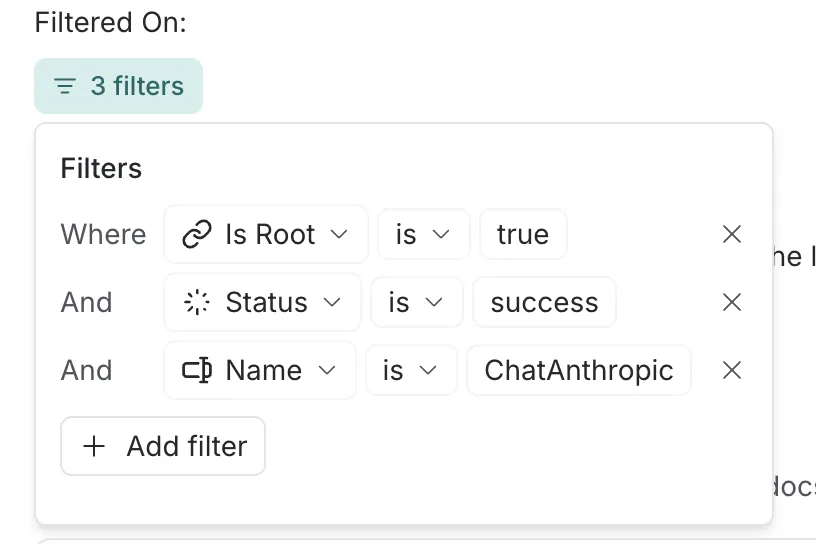
For each alert metric, you can leverage a robust set of filters to focus on specific subsets of runs (e.g., filtering by model, tool call or run type).
You can then set an aggregation windows (5 or 15 minutes) and a threshold to tune the sensitivity of alerts.
The last step is integrating the alert into your existing workflows. We support alerts via PagerDuty or setting up a custom webhook (e.g., to send notifications directly to a Slack channel).
And thats it! Check out our docs to learn more and get started today with alerting in LangSmith.
What's Next?
Alerting is a key piece to any observability product. In the future, we will be adding:
- More types of alerts: run count and LLM token usage
- Change alerts that allow you to set a relative value to alert over (e.g. alert when latency spikes 25%)
- Alerts over custom time windows
If you have feedback or feature requests, let us know what you think by getting in touch with us through the LangChain Slack Community. If you’re not part of the Slack community yet, sign up here.