Evaluating model outputs is one of the most important challenges in LLM application development. But human preference for many tasks (e.g., chat or writing) is difficult to encode in a set of rules. Instead, pairwise evaluation of multiple candidate LLM answers can be a more effective way to teach LLMs human preference.
Below, we explain what pairwise evaluation is, why you might need it, and present a walk-through example of how to use LangSmith’s latest pairwise evaluators in your LLM-app development workflow.
The origin of pairwise evaluation
Pairwise evaluation has started to play an important role in conversations on testing and benchmarking LLM model performance. For example, reinforcement learning from human feedback (i.e. RLHF) employs the concept of pairwise evaluation in LLM alignment. Human trainers are presented with pairs of LLM responses for the same input and select which one better aligns with certain criteria (e.g., helpfulness, informativeness, or safety).
One of the most popular LLM benchmarks, Chatbot Arena, also employs this idea: it presents two anonymous LLM generations for a given user prompt and allows the user to pick the better one. While the Chatbot Arena relies on human feedback for pairwise evaluation, it’s also possible to use LLM-as-a-judge to predict human preference and automate this pairwise evaluation process.
Despite its popularity in public benchmarking and LLM alignment, many users may not know how to use custom pairwise evaluation to improve their LLM applications. With this limitation in mind, we’ve added pairwise evaluation as a new feature in LangSmith.
Pairwise evaluators in LangSmith
LangSmith’s pairwise evaluation allows the user to (1) define a custom pairwise LLM-as-judge evaluator using any desired criteria and (2) compare two LLM generations using this evaluator. Instead of selecting runs to compare, you'll see a new sub-header called "Pairwise Experiments" when you click on the "Datasets and Testing" tab.
How is this different than the comparison view?
One question you may be asking is "how is this different than comparison view?"
In case you missed it, a few weeks ago we released an improved comparison view for regression testing. This allows you to compare two runs and identify regressions. Pairwise evaluation is similar in goal, but markedly different in implemention.
In the previous comparison view, you would evaluate each run individually and then compare the scores. For example, you would give each run a grade on a scale of 1-10 (independently) and then look for cases where one run got a higher grade than another.
Pairwise evaluation looks at the results at the same time. This allows you to define an evaluator that explicitly compares the two results. You then get a score for that pair. It is not scoring each run individually.
When might you use pairwise evaluation?
To motivate this feature, this video shows a common use-case related to content generation. In this example, we want an LLM to produce engaging Tweets summarizing academic papers. We built a dataset with 10 different papers as example (here) and generated summaries from 4 different LLMs.
Because there is no single “ground truth” paper summary that we want an LLM to generate, we used a criteria evaluator with this evaluation prompt to grade the summary Tweet from 1 (worst) to 5 (best) based upon 5 criteria (e.g., use of emojis, engaging title, etc).
We capture this summary_engagement_score in the dataset, as shown below.
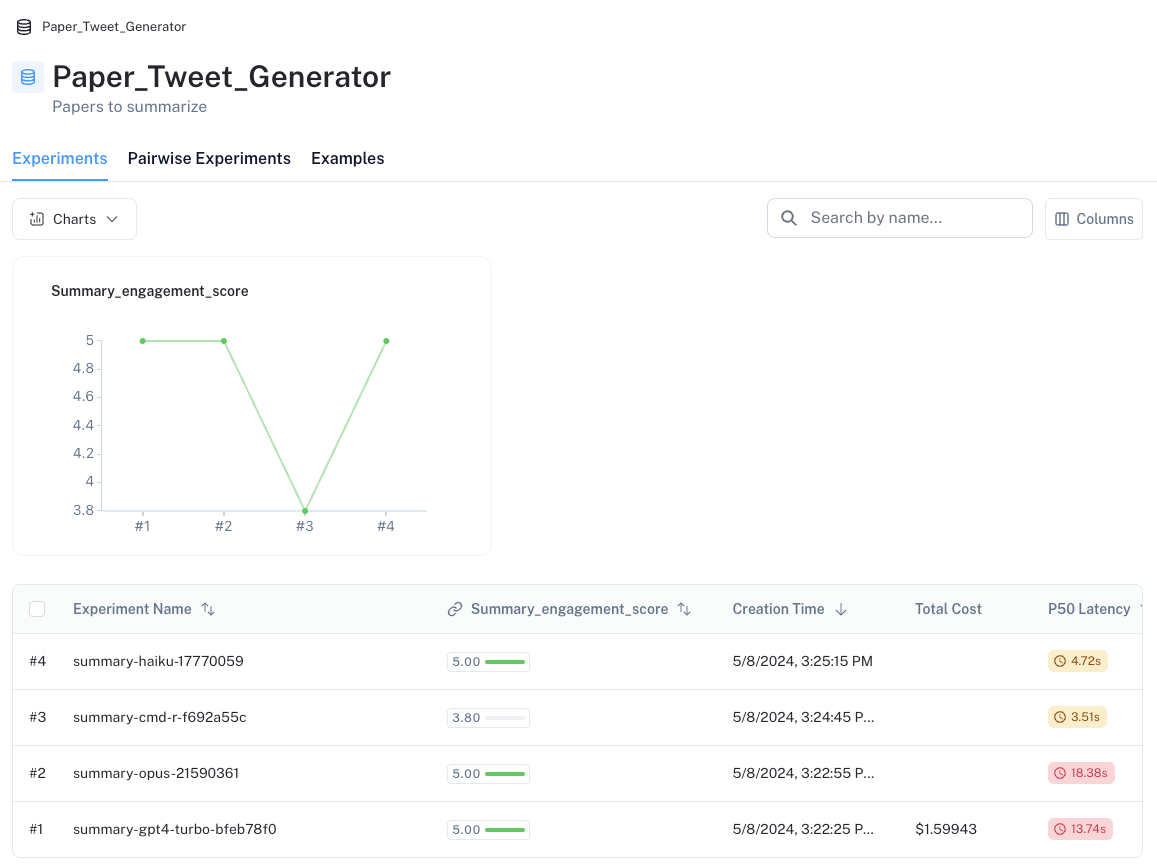
However, this immediately highlights a problem: 3 of the 4 LLMs all have a perfect score on our summary_engagement_score, with no differentiation between them. In isolation, it can be difficult to define a criteria evaluator that distinguishes between the various LLMs. However, pairwise evaluation presents an alternative way to approach this challenge.
Using Custom Pairwise Evaluation
As shown in the video (docs here), we use custom pairwise evaluators in the LangSmith SDK and visualize the results of pairwise evaluations in the LangSmith UI. To apply these to the problem mentioned above, we first define a pairwise evaluation prompt that encodes the criteria we care about (e.g., which of the two Tweet summaries is more engaging based on the title, bullet points, etc). We then simply run our custom evaluator, evaluate_pairwise, on any two experiments that have been already run on our dataset (see full code used here).
from langsmith.evaluation import evaluate_comparative
evaluate_comparative(
["summary-cmd-r-f692a55c", "summary-opus-21590361"],
evaluators=[evaluate_pairwise],
)
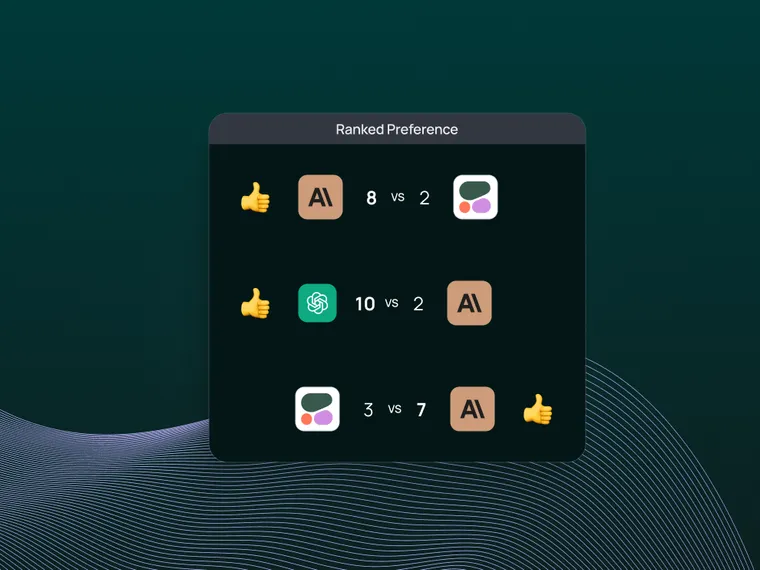
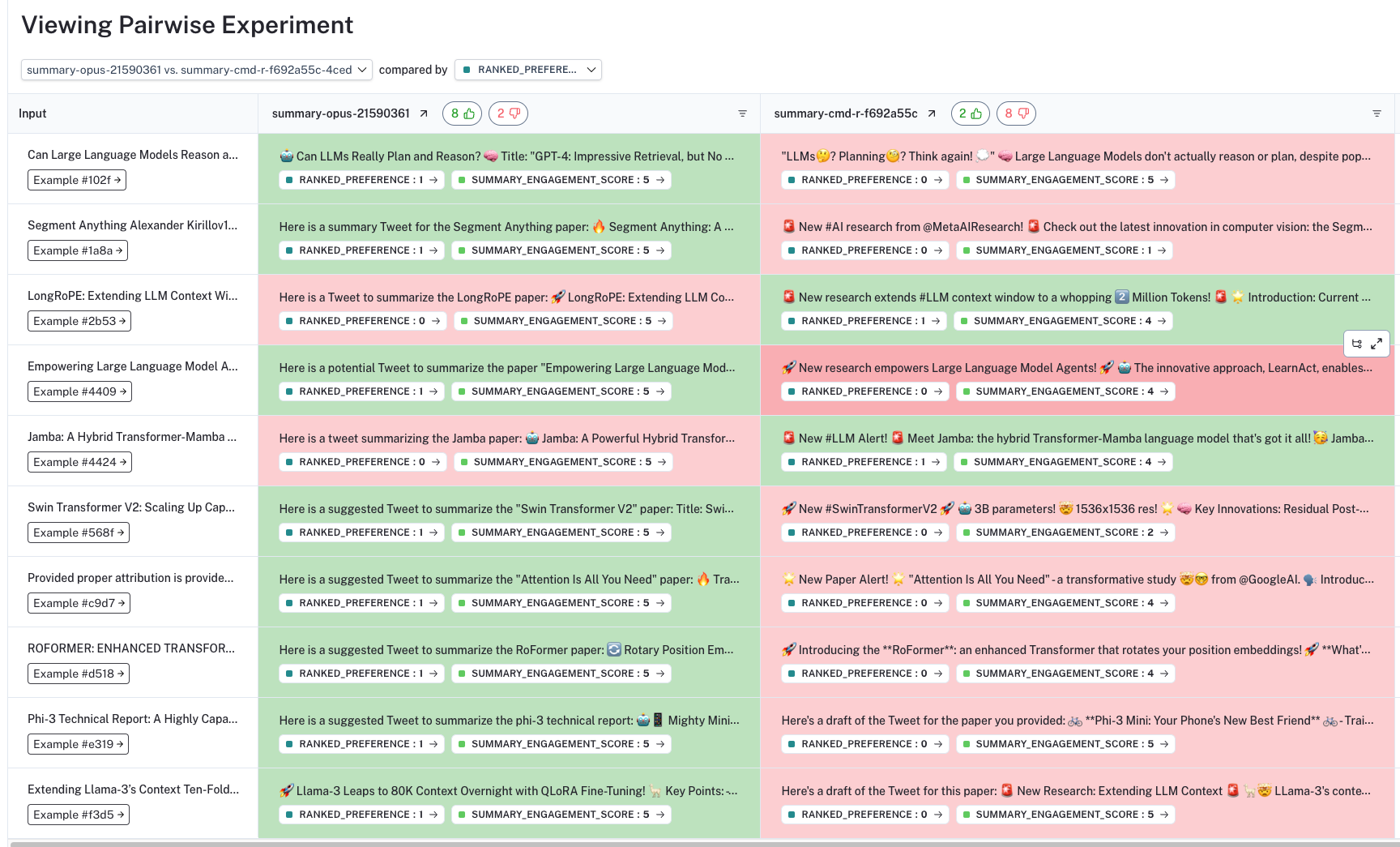
In the UI, we will then see the results of all pairwise evaluation in the Pairwise Experiments tab of our Dataset. Importantly, we see that pairwise evaluation shows clear preference for certain LLMs over others – unlike the stand-alone criteria evaluation, which shows little discrimination.
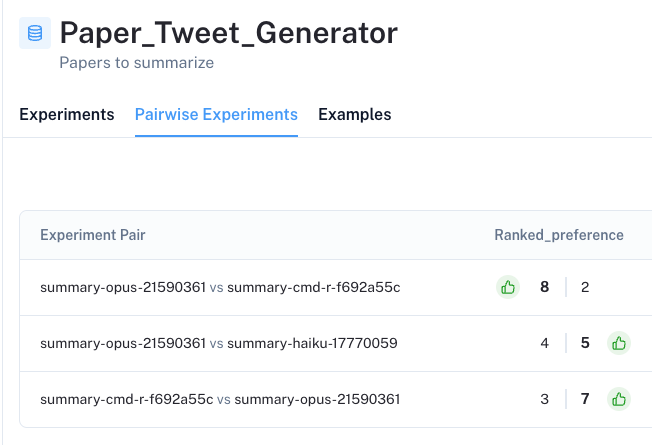
The UI allows us to dive into each pairwise experiment, showing which LLM generation is preferred based upon our criteria (with color and thumbs at the top of the column). By clicking on the ranked_preference score under each answer, we can drill further into each evaluation trace (see example here), which provides an explanation for the ranking (as defined in our prompt).
Conclusion
Many LLM use-cases, such as text generation or chat, don’t have a single or specific “correct” answer for use in evaluation. In these cases, pairwise evaluation with a human or LLM picking the preferred response is a powerful approach.
In this blog post, we showed how we were able to test on an ambiguous task of evaluating Tweet summary generation and revealed the shortcomings of a stand-alone evaluation criteria. Our custom pairwise evaluator allowed us to directly compare our generations against each other, highlighting a clear preference between models.
To dive deeper, check out our video and documentation on pairwise evaluation. And you can try out LangSmith today for robust experimentation and evaluation, with support for prompt versioning, debugging, and human annotations — so you can gain production observability as you build your LLM-apps.