
TL;DR: We are adjusting our abstractions to make it easy for other retrieval methods besides the LangChain VectorDB object to be used in LangChain. This is done with the goals of (1) allowing retrievers constructed elsewhere to be used more easily in LangChain, (2) encouraging more experimentation with alternative retrieval methods (like hybrid search). This is backwards compatible, so all existing chains should continue to work as before. However, we recommend updating from VectorDB chains to the new Retrieval chains as soon as possible, as those will be the ones most fully supported going forward.
Introduction
Ever since ChatGPT came out, people have been building a personalized ChatGPT for their data. We even wrote a tutorial on this, and then ran a competition about this a few months ago. The desire and demand for this highlights an important limitation of ChatGPT - it doesn't know about YOUR data, and most people would find it more useful if it did. So how do you go about building a chatbot that knows about your data?
The main way of doing this is through a process commonly referred to as "Retrieval Augmented Generation". In this process, rather than just passing a user question directly to a language model, the system "retrieves" any documents that could be relevant in answering the question, and then passes those documents (along with the original question) to the language model for a "generation" step.
The main way most people - including us at LangChain - have been doing retrieval is by using semantic search. In this process, a numerical vector (an embedding) is calculated for all documents, and those vectors are then stored in a vector database (a database optimized for storing and querying vectors). Incoming queries are then vectorized as well, and the documents retrieved are those who are closest to the query in embedding space. We're not going to go into too much detail on that here - but here is a more in depth tutorial on the topic, and below is a diagram which nicely summarizes this.
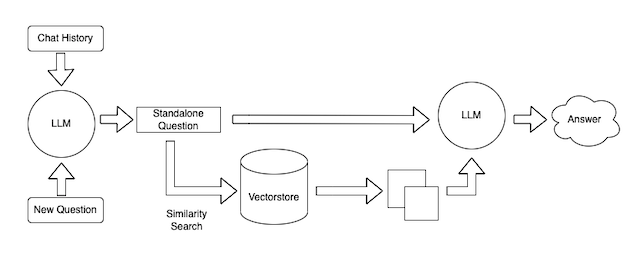
Problems
This process works pretty well, and a lot of the components and abstractions we've built (embeddings, vectorstores) are aimed at facilitating this process.
But we've noticed two problems.
First: there a lot of different variations in how you do this retrieval step. People want to do things beyond semantic search. To be concrete:
- We support two different query methods: one that just optimizes similarity, another with optimizes for maximal marginal relevance.
- Users often want to specify metadata filters to filter results before doing semantic search
- Other types of indexes, like graphs, have piqued user's interests
Second: we also realized that people may construct a retriever outside of LangChain - for example OpenAI released their ChatGPT Retrieval Plugin. We want to make it as easy as possible for people to use whatever retriever they created within LangChain.
We realized we made a mistake - by making our abstractions centered around VectorDBQA we were limiting to use of our chains, making them hard to use (1) for users who wanted to experiment with other retrieval methods, (2) for users who created a retriever outside the LangChain ecosystem.
Solution
So how did we fix this?
In our most recent Python and TypeScript releases, we've:
- Introduced the concept of a
Retriever. Retrievers are expected to expose aget_relevant_documentsmethod with the following signature:def get_relevant_documents(self, query: str) -> List[Document]. That's the only assumption we make about Retrievers. See more about this interface below. - Changed all our chains that used VectorDBs to now use Retrievers.
VectorDBQAis nowRetrievalQA,ChatVectorDBChainis nowConversationalRetrievalChain, etc. Note that, moving forward, we are intentionally using theConversationalprefix to indicate that the chain is using memory and theChatprefix to indicate the chain is using a chat model. - Added the first instance of a non-LangChain Retriever - the
ChatGPT Retrieval Plugin. This was a module open-sourced yesterday by OpenAI to help companies expose retrieval endpoints to hook into ChatGPT. NB: for all intents and purposes, the inner workings of theChatGPT Retrieval Pluginare extremely similar to our VectorStores, but we are still extremely excited to integrate this as a way highlighting the new flexibility that exists.
Expanding on the Retriever interface:
- We purposefully only require one method (
get_relevant_documents) in order to be as permissive as possible. We do not (yet) require any uniform methods around construction of these retrievers. - We purposefully enforce
query: stras the only argument. For all other parameters - including metadata filtering - this should be stored as parameters on the retriever itself. This is because we anticipate the retrievers often being used nested inside chains, and we do not want to have plumb around other parameters.
This is all done with the end goal of making it easier for alternative retrievers (besides the LangChain VectorStore) to be used in chains and agents, and encouraging innovation in alternative retrieval methods.
Q&A
Q: What's the difference between an index and a retriever?
A: An index is a data structure that supports efficient searching, and a retriever is the component that uses the index to find and return relevant documents in response to a user's query. The index is a key component that the retriever relies on to perform its function.
Q: If I was using a VectorStore before in VectorDBQA chain (or other VectorDB-type chains), what do I now use in RetrievalQA chain?
A: You can use a VectorStoreRetriever, which you can create from an existing vectorstore by doing vectorstore.as_retriever()
Q: Does VectorDBQA chain (or other VectorDB-type chains) still exist?
A: Yes, although we will be no be focusing on it any more. Expect any future development to be done on RetrievalQA chain.
Q: Can I contribute a new retrieval method to the library?
A: Yes! We started a new langchain/retrievers module exactly for this purpose
Q: What are real world examples this enables?
A: The main one is better question-answering over your documents. However, if start to ingest and then retrieve previous messages, this can then be thought of as better long term memory for AI.