Editor's Note: This post was written by Chris Pappalardo, a Senior Director at Alvarez & Marsal, a leading global professional services firm. The standard processes for building with LLM work well for documents that contain mostly text, but do not work as well for documents that contain tabular data (like spreadsheets). We wrote about our latest thinking on Q&A over csvs on the blog a couple weeks ago, and we loved reading Chris's exploration of working with csvs and LangChain using agents, chains, RAG, and metadata. Lots of great learnings in here!
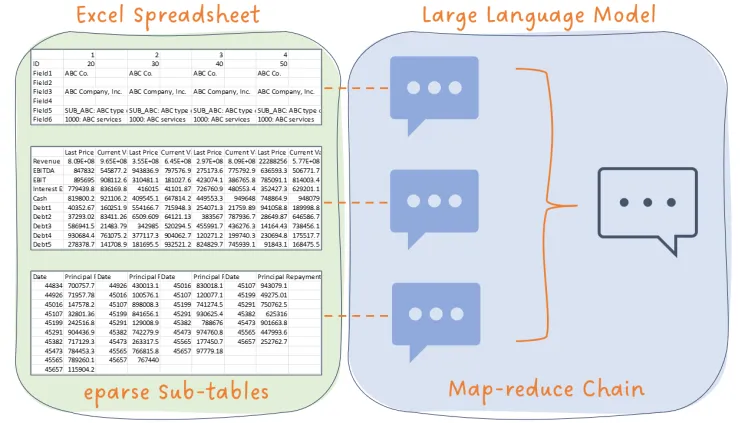
When I first sat down to write eparse, the objective was to create a library that could crawl and parse a large set of Excel files and extract information in context into storage for later consumption. To this end, we were fairly successful – eparse can extract sub-tabular information using a rules-based search algorithm and store labeled cells as rows in a database. Assuming the user has a good idea of what is contained in the source files, SQL queries or the eparse CLI can be used to retrieve specific data.
However, document Extraction, Transformation, and Loading (“ETL”) activities are becoming more generative AI-oriented to facilitate activities like document summarization and Retrieval-Augmented Generation (“RAG”). Given that most documents in question mostly contain text, which Large Language Models (“LLMs”) are well suited for, many of the ETL tools were built for this case. A typical “quickstart” workflow for these purposes is as follows:
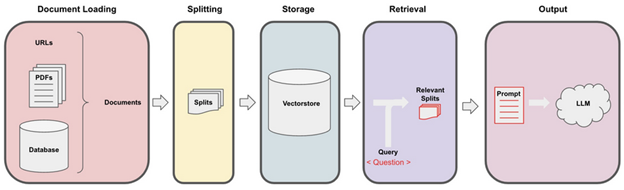
The process begins with using an ETL tool set like unstructured, which identifies the document type, extracts content as text, cleans the text, and returns one or more text elements. A second library, in this case langchain, will then “chunk” the text elements into one or more documents that are then stored, usually in a vectorstore such as Chroma. Finally, an LLM can be used to query the vectorstore to answer questions or summarize the content of the document.
This process works well for documents that contain mostly text. It does not work well for documents that contain mostly tabular data, such as spreadsheets.
To better understand this problem, let’s consider an example. In the eparse code repository there is a unit test data file called eparse_unit_test_data.xlsx which contains the following sub-tables, each with different types of financial data:

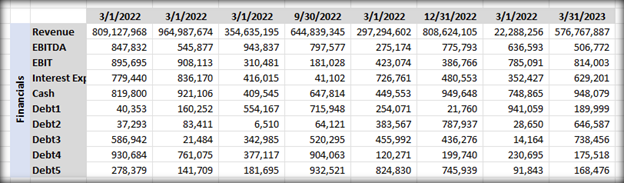
For this demonstration, I wrote a Gradio app to display the extracted and chunked text data so it is easier to figure out what the libraries are doing behind the scenes. If we use unstructured and langchain without any modifications, the ETL workflow would produce text chunks from this file that look as follows:
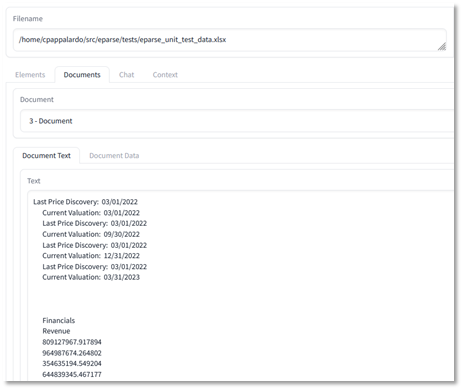
Unstructured produces a single text element which LangChain chunks up into 14 pieces, with the 3rd piece (“3 – Document”) containing the first sub-table I depicted above. Each cell in this table is a separate line, and the 3rd piece contains about 40 lines, which is not the entire table.
When I first tried to ask an LLM to summarize the document using the vectorstore, I received a context window overrun error due to the number of tokens (loosely words) exceeding the LLM’s context window size (in this case 2k tokens). This is a common problem with working with LLMs, which I will touch on later in the article. So, to handle that problem, I used a larger context window LLM running on a bigger server and extended the API timeout to 10 minutes. This time we get a decent result:
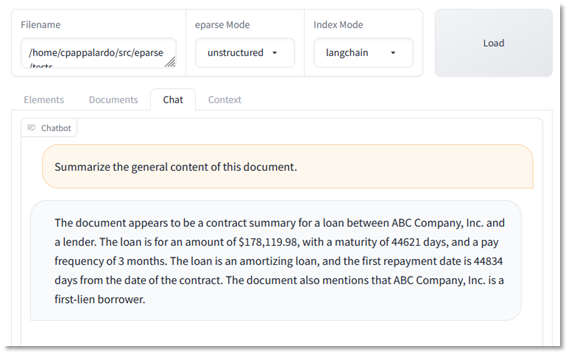
With default implementations, the LLM understood some aspects of the file but did not get a good general sense of the content. Also, the amounts are off, the loan amount appears to be 10x higher than the amount in the file, ignores the other loans, and the LLM is misunderstanding the unformatted Excel date value (a 44,621 day maturity would be 122+ years).
How does eparse perform on the same task?
eparse does things a little differently. Instead of passing entire sheets to LangChain, eparse will find and pass sub-tables, which appears to produce better segmentation in LangChain. Using eparse, LangChain returns 9 document chunks, with the 2nd piece (“2 – Document”) containing the entire first sub-table. Asking the LLM to summarize the spreadsheet using these vectors produces a more comprehensive view of what is contained in the spreadsheet, including the nuances of the sub-tables, and without any erroneous data.
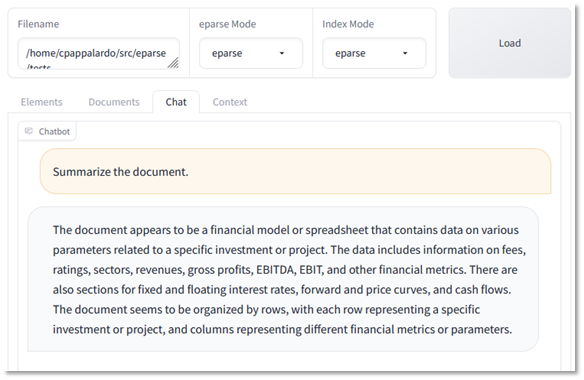
However, the LLM gets sidetracked by pedantic things like row structure on a single table, and still gets basic questions about amounts incorrect:

And the dates are still in the wrong format:

A better way.
To recap, these are the issues with feeding Excel files to an LLM using default implementations of unstructured, eparse, and LangChain and the current state of those tools:
- Excel sheets are passed as a single table and default chunking schemes break up logical collections
- Larger chunks strain constraints such as context window size, GPU memory, and timeout settings
- Broken logical collections and default retrieval schemes produce incomplete summaries
- Discrete value lookup performance by the LLM on vectorized data is poor
- Default data cleaning does not handle certain things like Excel numeric date encoding
The basic problem with summarization is that it is a reduction from many things to one statement. The default configuration for a single document retrieval Q&A application is to find 4 similar parts of the document and “stuff” them into the context window before asking for a summary.
To improve retrieval and summarization performance on spreadsheets, we need to consider other retrieval strategies. Damien Benveniste recently posted the following graphic on LinkedIn that addresses handling summaries of multiple documents that are too large to fit into the context window:
Adding options for chain type, search type, and k-documents settings to my Gradio app, I am now able to test each of these strategies in different configurations against different LLMs:
Setting chain type to “map reduce” (the second strategy in Figure 7) and increasing the number of retrieved documents produces a much better result:

The LLM hits on all major themes in the various extracted sub-tables, acknowledges the instrument type in the document (debt), and even mentions the amortization schedule. All sans nonsensical data elements.
Turning on chain verbosity, we can get an idea of what is happening behind the scenes (apologies for the small text):
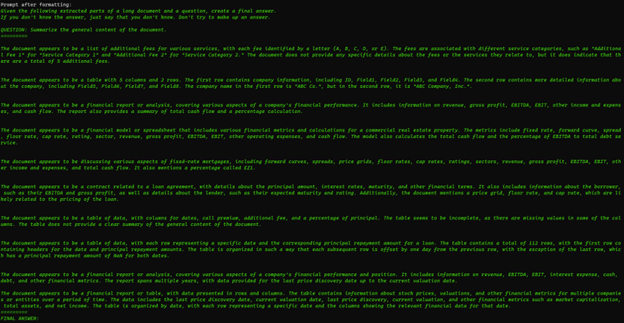
Each extracted sub-table is being summarized by the LLM before it is injected into a final prompt for a collective summary at the end, just like the map-reduce diagram depicts. Expanding the K-document size ensures that smaller nuances of the file are considered.
You may be wondering about the “refine” strategy and perhaps wonder what happened to the small context model we started with. I tried various strategies and combinations with the smaller model including refine and, while I was able to eventually deal with the context window limitation, that model with and without the refine strategy just did not deliver quality responses. I believe this result is the combination of a worse foundational model and 8-bit quantization. Bottom line is that it pays to have at least one LLM running on outsized hardware with a solid foundation to test against.
What about specific data retrieval?
The solution to the problem of extracting specific data from spreadsheet tables using an LLM will involve the Agent design pattern, where LLMs are taught to use functions that they can call. The demonstration of agents is beyond the scope of this article. However, we recently added something to eparse that will assist in this effort that I am excited to share.
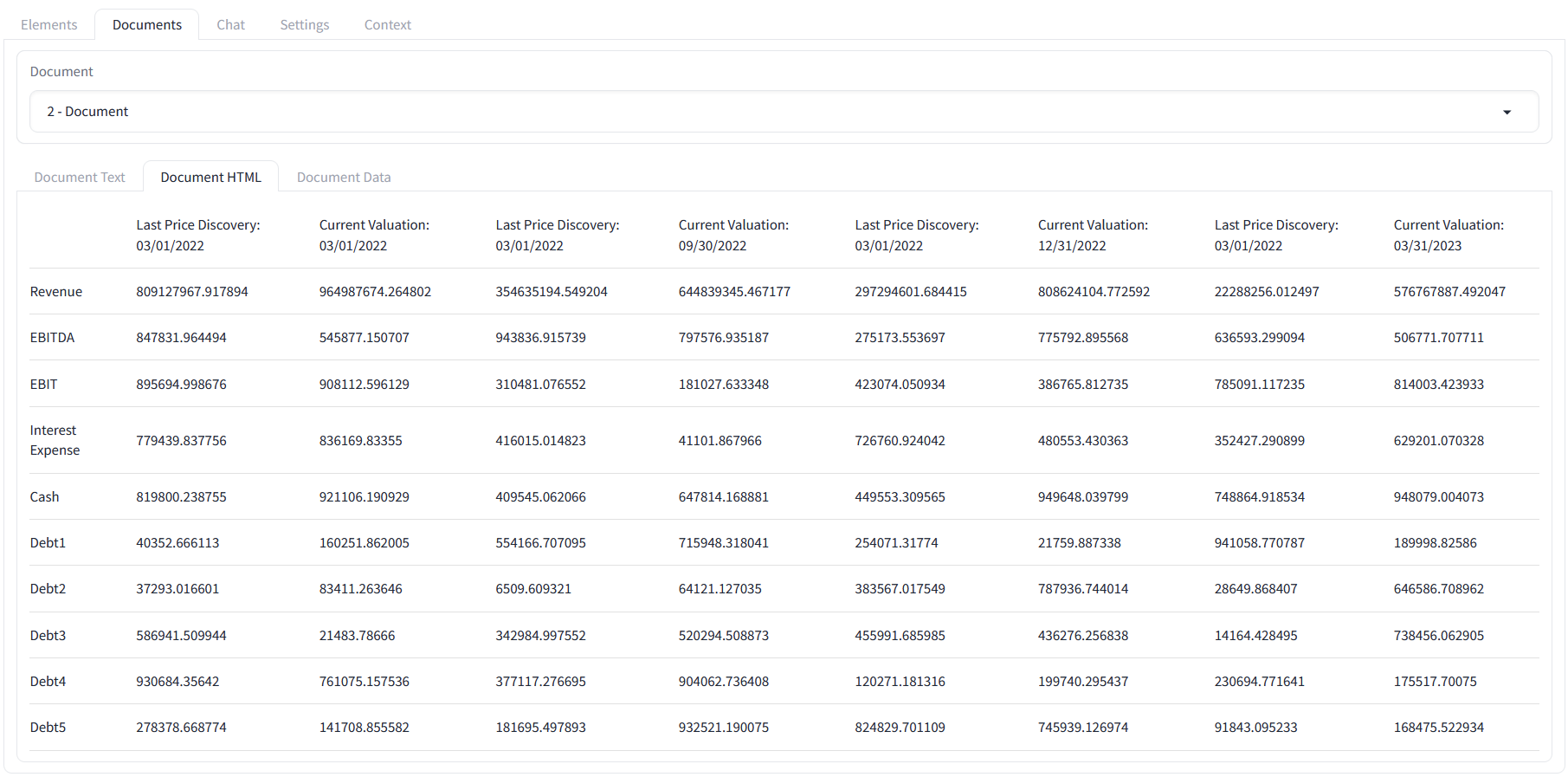
In version 0.7.0 of eparse we introduced utility functions and a new interface to seamlessly transition from HTML tables to an eparse data interface backed by Sqlite. What this means is that users can interface their LLMs to structured table data captured by the ETL process, which is stored as metadata in the objects that are uploaded to vector storage. For example, the following HTML table was generated as a by-product from eparsing the unit test spreadsheet:
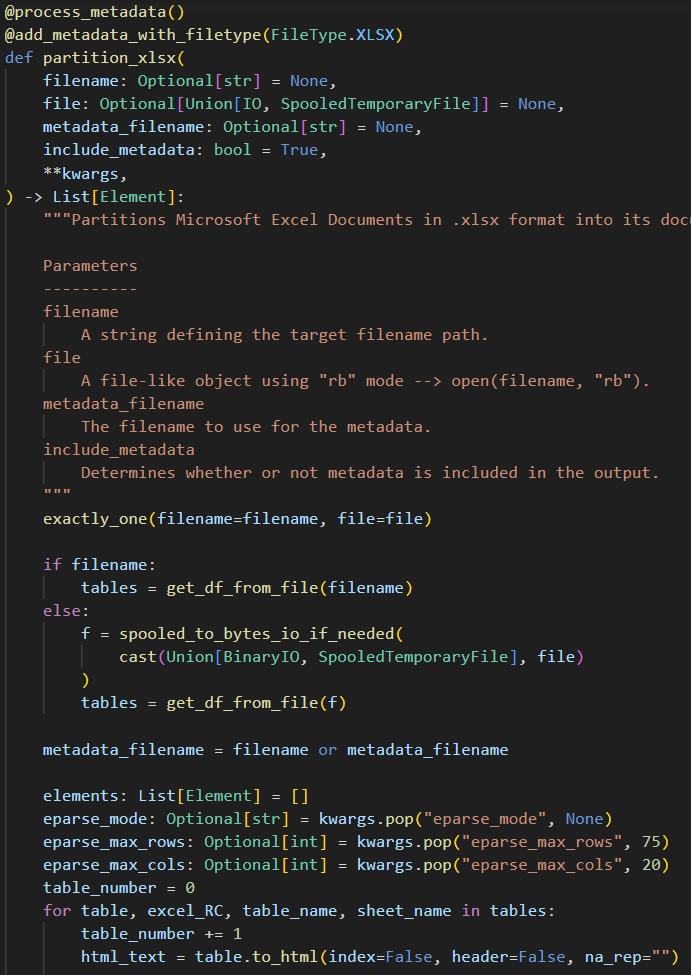
To facilitate an ETL pipeline powered by eparse, a drop-in replacement of the unstructured auto partitioner and the Excel partitioner are provided starting with v0.7.1 (see the README for more details on how to incorporate these functions into your project):
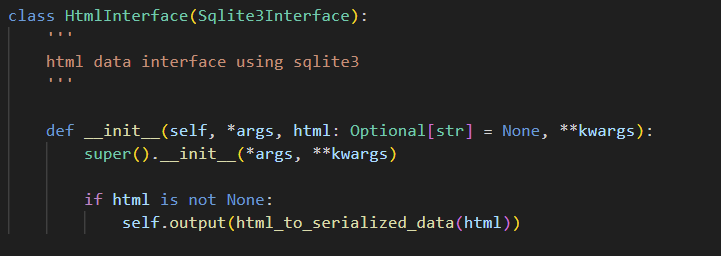
Using HTML tabular data in an LLM chain with agent tools is as easy as instantiating the following new HTML interface and then using it like any other database ORM:
And handling conversion of numeric Excel formatting data?
The solution to the problem of handling things like recasting Excel numeric date information into the proper format would best be handled by a custom cleaning or staging brick using the unstructured library. A discussion of cleaning bricks and how to apply them is here.
Conclusion
In conclusion, extracting information from Excel spreadsheets presents unique problems not contemplated by many ETL systems and the typical LLM tool sets. Key points to consider when designing your own solutions include:
- Spreadsheets present unique problems on both the ingestion / chunking side and in retrieval
- Chain selection is important, default settings may (and often) do not work well
- LLMs are good at text, not great at data, so you will likely need an agent solution to get accurate information from queries
- Not all LLMs are the same when it comes to summarization performance
- Metadata is valuable and you may have underutilized data in your vectorstore