LangChain exists to make it as easy as possible to develop LLM-powered applications.
We started with an open-source Python package when the main blocker for building LLM-powered applications was getting a simple prototype working. We remember seeing Nat Friedman tweet in late 2022 that there was “not enough tinkering happening.” The LangChain open-source packages are aimed at addressing this and we see lots of tinkering happening now (Nat agrees)–people are building everything from chatbots over internal company documents to an AI dungeon master for a Dungeons and Dragons game.
The blocker has now changed. While it’s easy to build a prototype of an application in ~5 lines of LangChain code, it’s still deceptively hard to take an application from prototype to production. The main issue that we see today is application performance–something that works ~30% of the time is good enough for a Twitter demo, but not nearly good enough for production.
Today, we’re introducing LangSmith, a platform to help developers close the gap between prototype and production. It’s designed for building and iterating on products that can harness the power–and wrangle the complexity–of LLMs.
LangSmith is now in closed beta. So if you’re looking for a robust, unified, system for debugging, testing, evaluating, and monitoring your LLM applications, sign up here.
How did we get here?
Given the stochastic nature of LLMs, it is not easy–and there’s currently no straightforward way–to answer the simple question of “what’s happening in these models?,” let alone getting them to work reliably. The builders we hear from are running into the same roadblocks (and it’s true for our team, too):
- Understanding what exactly the final prompt to the LLM call is (after all the prompt template formatting, this final prompt can be long and obfuscated)
- Understanding what exactly is returned from the LLM call at each step (before it is post-processed or transformed in any way)
- Understanding the exact sequence of calls to LLM (or other resources), and how they are chained together
- Tracking token usage
- Managing costs
- Tracking (and debugging) latency
- Not having a good dataset to evaluate their application over
- Not having good metrics with which to evaluate their application
- Understanding how users are interacting with the product
All of these problems have parallels in traditional software engineering. And, in response, a set of practices and tools for debugging, testing, logging, monitoring, etc. has emerged to help developers abstract away common infrastructure and focus on what really matters - building their applications. LLM application developers deserve the same.
LangSmith aspires to be that platform. Over the last few months, we’ve been working directly with some early design partners and testing it on our own internal workflows, and we’ve found LangSmith helps teams in 5 core ways:
Debugging
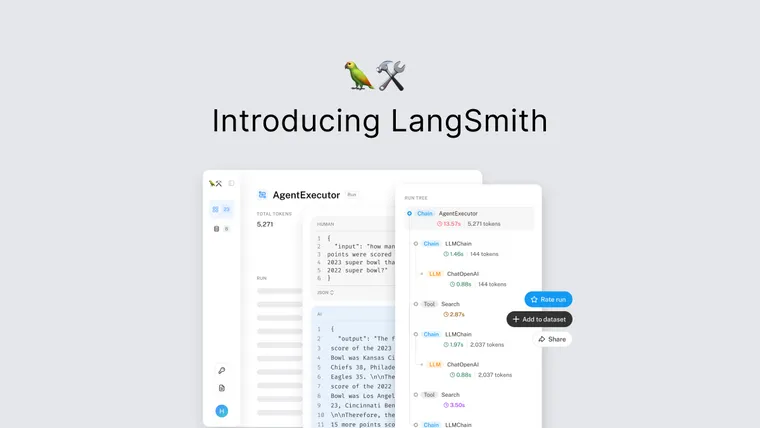
LangSmith gives you full visibility into model inputs and output of every step in the chain of events. This makes it easy for teams to experiment with new chains and prompt templates, and spot the source of unexpected results, errors, or latency issues. We’ll also expose latency and token usage so that you can identify which calls are causing issues.
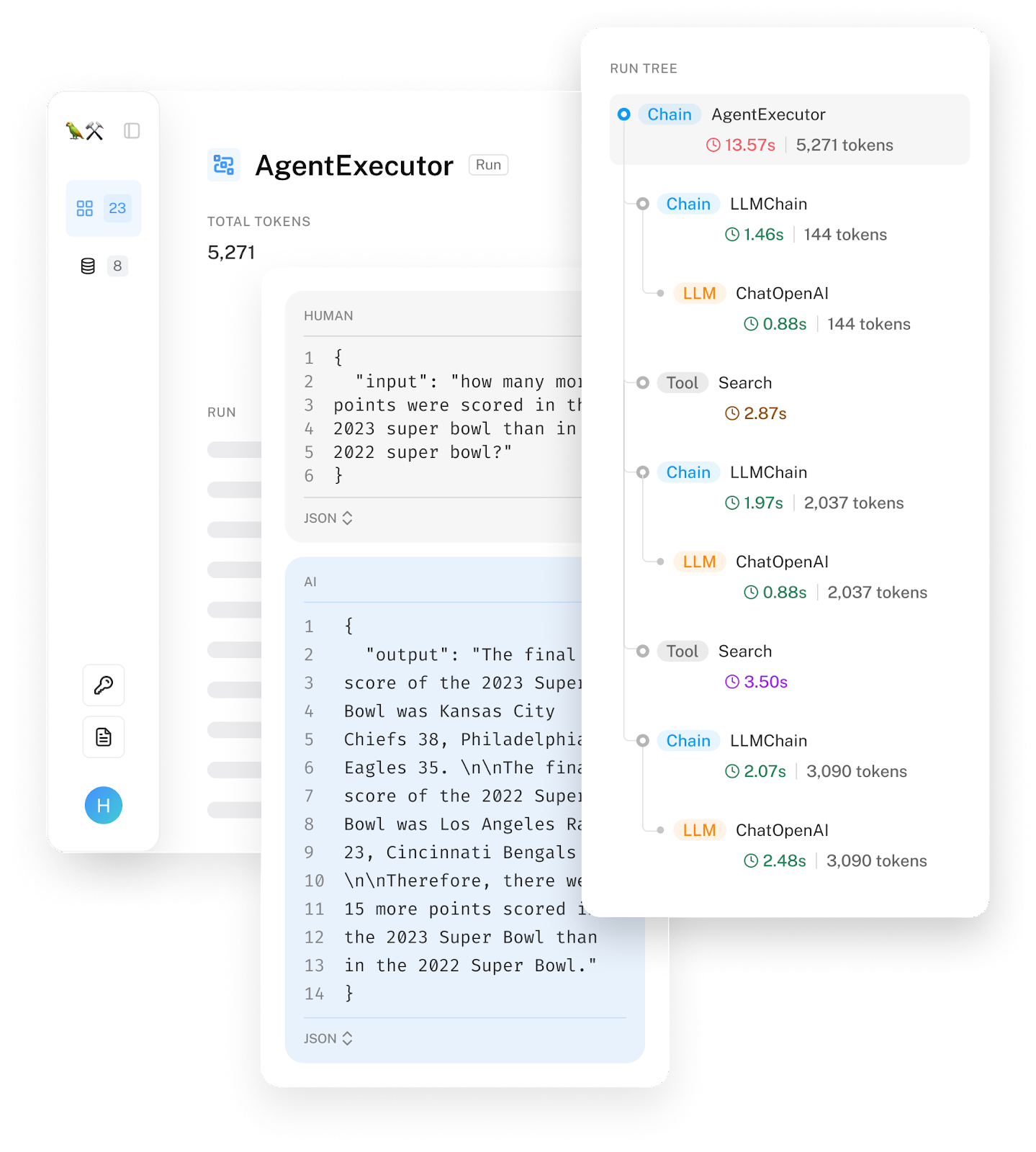
We’ve also made it easy to change and rerun examples from the UI. We added this feature after seeing teams take logs of bad examples and copy-paste into the OpenAI playground to tweak the prompt until they got a good result. We wanted to eliminate that friction, and now with the click of a button, you can go from a log to a playground where you can actively edit. This is currently supported for both OpenAI and Anthropic models, with support for more coming soon. We’re also working on supporting this for chains in general.
This deep visibility into model performance has been particularly helpful for teams developing complex applications. LangSmith helped Streamlit and Snowflake implement agents that could intelligently and reliably answer questions about their data.
"LangChain has been instrumental in helping us prototype intelligent agents at Snowflake,” said Adrien Treuille, Director of Product at Snowflake. “LangSmith was easy to integrate, and the agnostic open source API made it very flexible to adapt to our implementation,” tacked on Richard Meng, Senior Software Engineer at Snowflake.
Boston Consulting Group also built a highly-customized, and highly performant, series of applications on top of LangChain’s framework by relying on this same infrastructure.
“We are proud of being one of the early LangChain design partners and users of LangSmith,” Said Dan Sack, Managing Director and Partner at BCG. “The use of LangSmith has been key to bringing production-ready LLM applications to our clients. LangSmith's ease of integration and intuitive UI enabled us to have an evaluation pipeline up and running very quickly. Additionally, tracing and evaluating the complex agent prompt chains is much easier, reducing the time required to debug and refine our prompts, and giving us the confidence to move to deployment.”
In another example of debugging in action, we partnered with DeepLearningAI to equip learners in the recently-released LangChain courses with access to LangSmith. This allowed students to easily visualize the exact sequence of calls, and the inputs and outputs at each step in the chain with precision. Students can understand exactly what the chains, prompts, and LLMs were doing, which helps build intuition as they learn to create new and more sophisticated applications.
Testing
One of the main questions we see developers grapple with is: “If I change this chain/prompt, how does that affect my outputs?” The most effective way to answer this question is to curate a dataset of examples that you care about, and then run any changed prompts/chains over this dataset. LangSmith first makes it easy to create these datasets from traces or by uploading datasets you’ve curated manually. You can then easily run chains and prompts over those data sets.
The first helpful step is simply manually looking at the new inputs and outputs. Although this may seem unsatisfyingly basic, it actually has some benefits - many of the companies we’ve spoken to actually like some manual touch points because it allows them to develop better intuition about how to interact with LLMs. This intuition can prove incredibly valuable when trying to think about how to improve the application. The main unlock we hope to provide is a clear interface for letting developers easily see the inputs and outputs for each data point, as without that visibility they cannot build up that intuition.
Today, we primarily hear from teams that want to bring their prototype into production, and are narrowing in on specific prompts they’d like to improve. Klarna is building industry-leading AI integrations that go beyond a simple call to a language model, and instead rely on a series of calls. As they focus on a specific section, LangSmith has provided the tools and data they need to ensure no regressions occur.
In parallel, we’re starting to hear from more and more ambitious teams that are striving for a more effective approach.
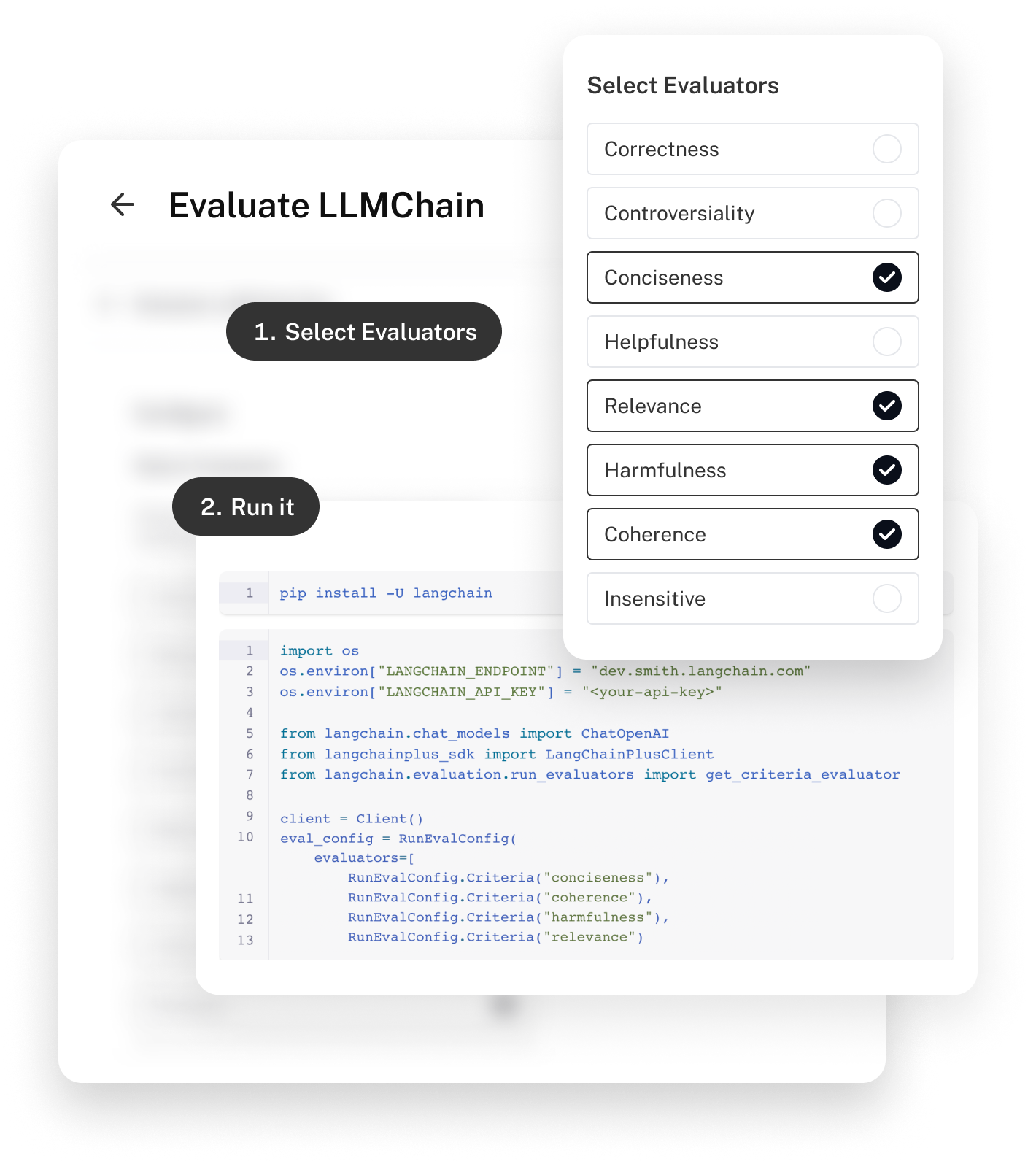
Evaluating
LangSmith integrates seamlessly with our open source collection of evaluation modules. These modules have two main types of evaluation: heuristics and LLMs. Heuristic Evaluations will use logic like regexes to evaluate the correctness of an answer. LLM evaluations will use LLMs to evaluate themselves.
We are extremely bullish on LLM assisted evaluation over the long term. Critics of this approach will say that it’s conceptually shaky and practically costly (time and money). But, we’ve been seeing some very compelling evidence come out of top labs that this is a viable strategy. And, as we collectively make improvements to these models–both private and open source–and usage becomes more ubiquitous, we expect costs to come down considerably.
Monitoring
While debugging, testing, and evaluating can help you get from prototype to production, the work doesn’t stop once you ship. Developers need to actively track performance, and ideally, optimize that performance based on feedback. We consistently see developers relying on LangSmith to track the system-level performance of their application (like latency and cost), track the model/chain performance (through associating feedback with runs), debug issues (diving into a particular run that went wrong), and establish a broad understanding of how users are interacting with their application and what their experience is like.
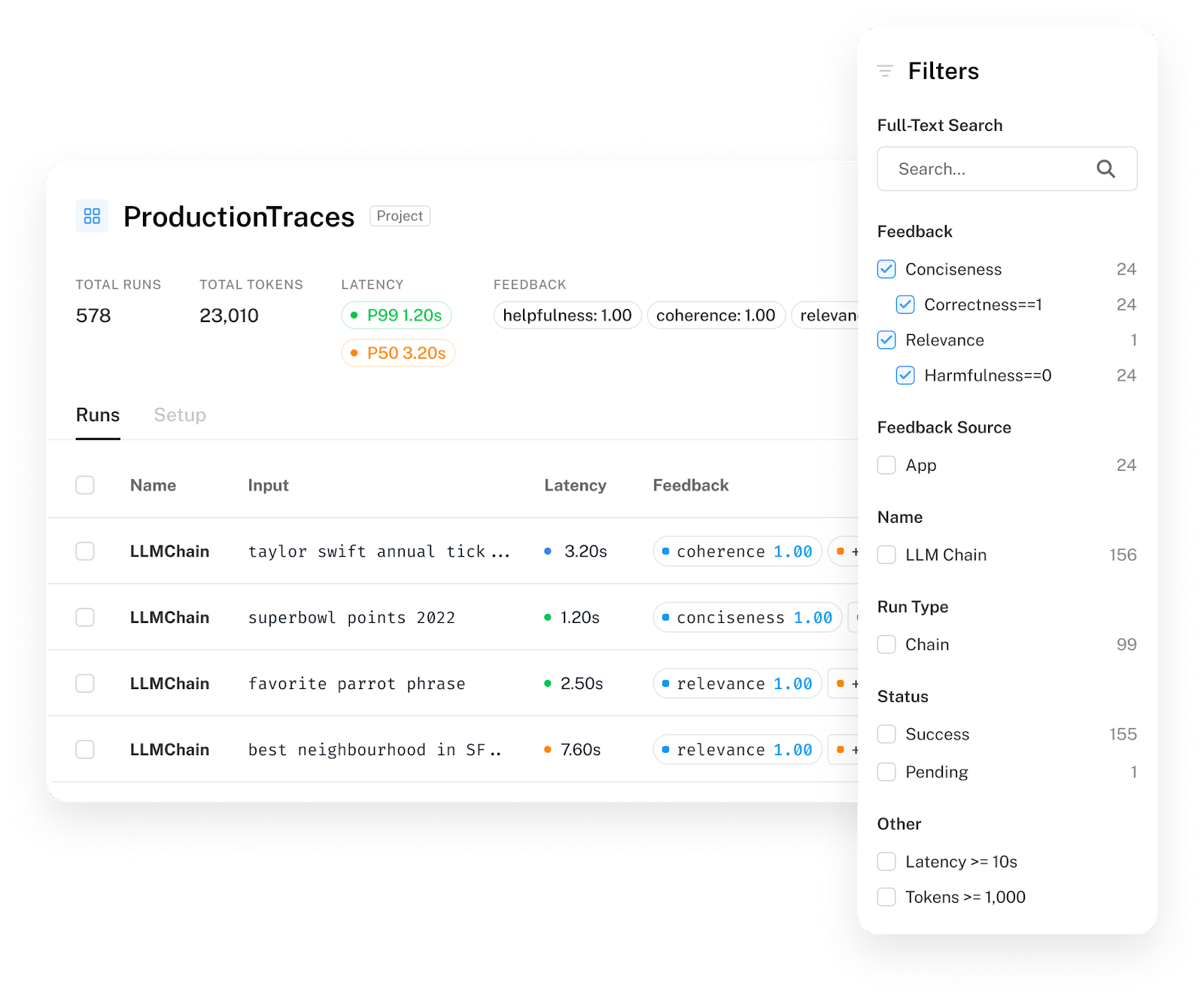
Ambitious startups like Mendable, Multi-On and Quivr, who are already serving thousands of users are actively using LangSmith to not only monitor overall usage, but also use those insights to take action on critical issues.
“Thanks to Langchain smith we were able to analyze our LLM calls, understand the performance of the different chain methods ( stuff vs reduce) for QA and improve upon it. It even helped us debug and understand errors we made. We are consistently using it to improve our prompt engineering and look forward to the new features,” said Stan Girard, Head of GenAI at Theodo and creator of Quivr.
A unified platform
While each of these product areas provide unique value, often at a specific point in time in the development process, we believe a great deal of the long term impact of LangSmith will come from having a single, fully-integrated hub to do this work from. We see teams with all kinds of Rube Goldberg-machine-like processes for managing their LLM applications, and we want to make that a thing of the past.
As a very simple example, we considered it to be table stakes for LangSmith to help users easily create datasets from existing logs and use them immediately for testing and evaluation, seamlessly connecting the logging/debugging workflows to the testing/evaluation ones.
Fintual, a Latin American startup with big dreams to help their citizens build wealth through a personalized financial advisor, found LangSmith early in their LLM development journey. “As soon as we heard about LangSmith, we moved our entire development stack onto it. We could build the evaluation, testing, and monitoring tools we needed in-house. But it would be 1000x worse, take us 10x longer, and require a team 2x the size,” said Fintual leader Jose Pena.
“Because we are building financial products, the bar for accuracy, personalization, and security is particularly high. LangSmith helps us build products we are confident putting in front of users.”
We can’t wait to bring these benefits to more teams. And we’ve got a long list of features on the roadmap like analytics, playgrounds, collaboration, in-context learning, prompt creation, and more.
Finally, we recognize that we cannot build ALL the functionality you will need to make it easy to make your applications production ready today. We’ve made it possible to export datasets in the format OpenAI evals expects so you can contribute them there. This data can be also used directly to fine tune your models on the Fireworks platform (and we aim to make it easy to plug into other fine-tuning systems as well). Finally, we’ve made logs exportable in a generic format and worked with teams like Context to ensure that you can load them into their analytics engine and run analytics over them in there.
We can’t wait to see what you build.