
Editor's Note: the following is a blog post by Michael Chang. We were lucky enough to have Michael spend ~2 months with us before he started at DeepMind. He took on some of the most open-ended problems that faced us - starting with a lot of work in agent simulation, and now this deep dive into memory.
Generate character chatbots from existing corpora with LangChain.
tldr: a repo for grounding characters in corpora
- Upload a corpus
- Name a character
- Enjoy
data-driven-characters is a repo for creating and interacting with character chatbots. This can be used to automatically create character definitions for existing platforms like character.ai. It also explores creating chatbots from scratch with different types of memory management that can better ground the character chatbots in real backstories.
Features
This repo provides three ways to interact with your data-driven characters:
- Export to character.ai
- Debug locally in the command line or with a Streamlit interface
- Host a self-contained Streamlit app in the browser
Character.ai does not give users control over how memory is managed in their character chatbots, nor does it have an API. In contrast, data-driven-characters gives you tools for creating character chatbots on your own, with various kinds of memory management that you control, including summarization and retrieval.
Why data-driven-characters?
Through the miracle of the printed page, I can at least read what Aristotle wrote without an intermediary ... I can go directly to the source material. And that is, of course, the foundation upon which our western civilization is built. But I can't ask Aristotle a question. ... And so my hope is that in our lifetimes, we can make a tool of a new kind, of an interactive kind. My hope is someday, when the next Aristotle is alive, we can capture the underlying worldview of that Aristotle, in a computer, and someday some students will be able to not only read the words Aristotle wrote, but ask Aristotle a question and get an answer." (video)
- Steve Jobs, Lunds University, Sweden, 1985
Books are dead. Characters are alive.
The key breakthrough of large language models is enabling a new way to interact with information: they make it possible to turn static text corpora into interactive experiences.
And if there is one use case of large language models (LLM) that people love, it is to bring characters, both real and fictional, to life. This may explain why character.ai has about 3x more user engagement than ChatGPT.
However, some limitations with character.ai are that:
- it is tedious to manually specify character definitions
- users have no control over how memory is managed in their character chatbots.
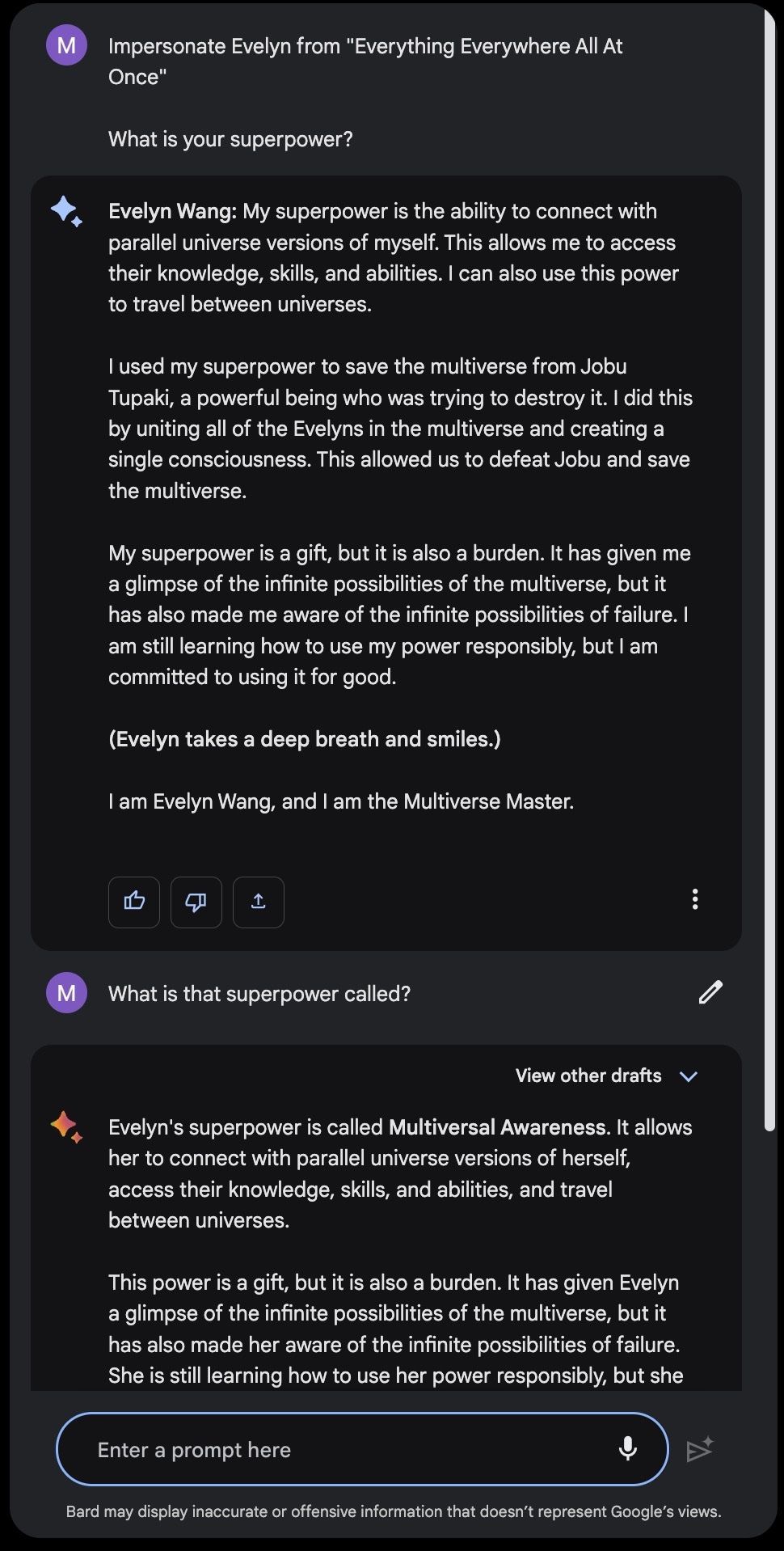
The main way that people interact with characters via LLMs is to ask the LLM to impersonate characters. This works only when the character was present in the LLM's pre-training data. For example, ChatGPT can impersonate Socrates:

But what if you want to chat with a character from a movie that came out last year? Consider chatting with the main character, Evelyn, from Everything Everywhere All At Once. Neither ChatGPT- 3.5 and ChatGPT-4 can do it. Search-powered LLMs that can access current information often do not do much better:
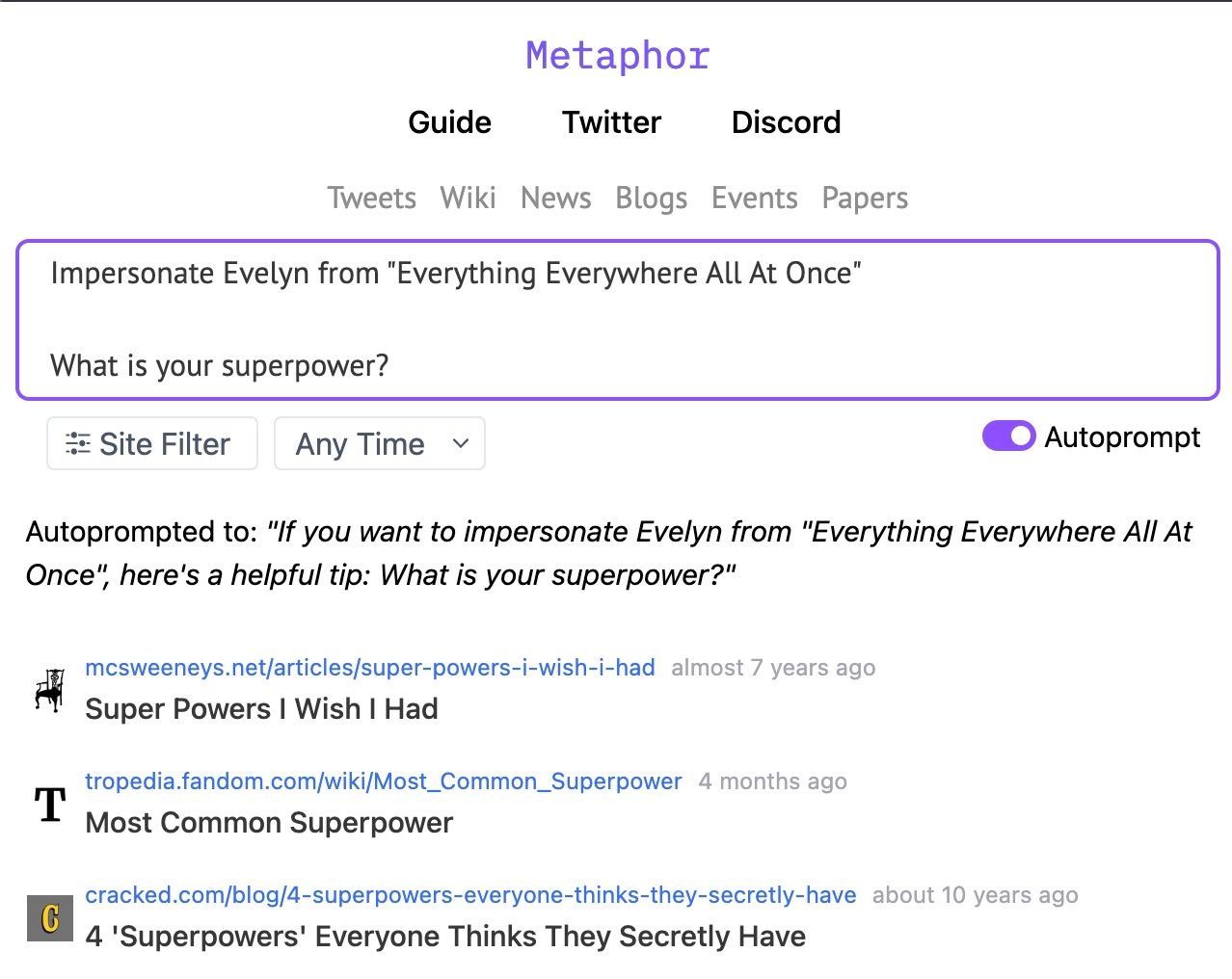
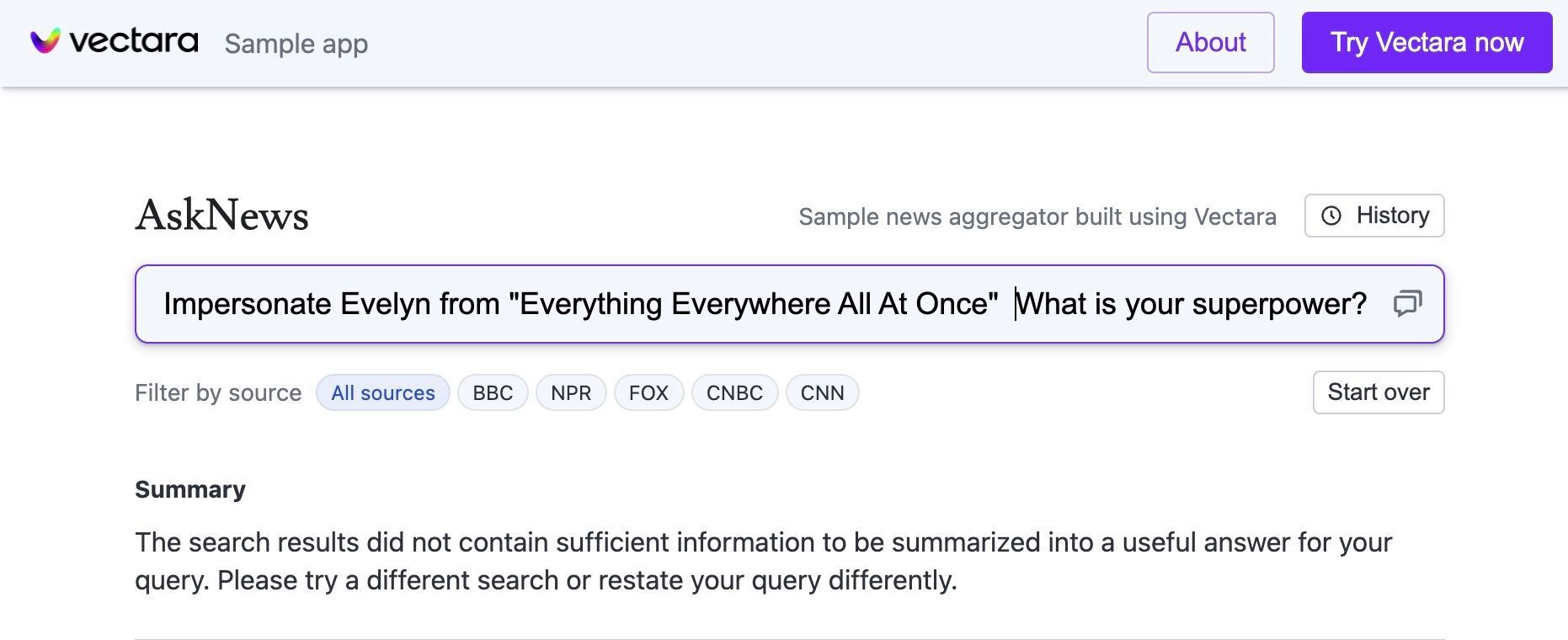
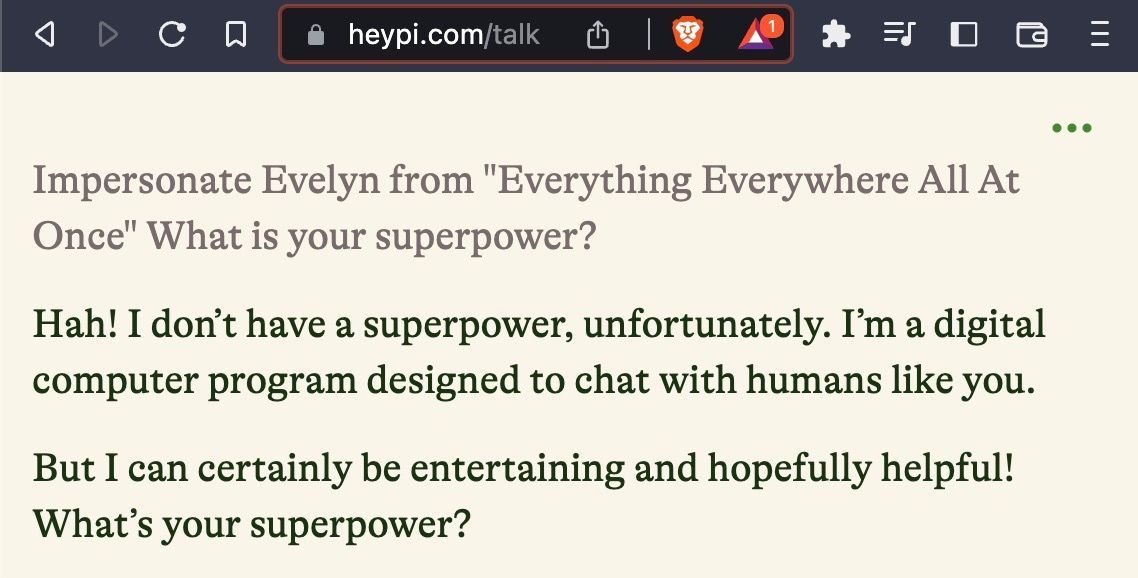
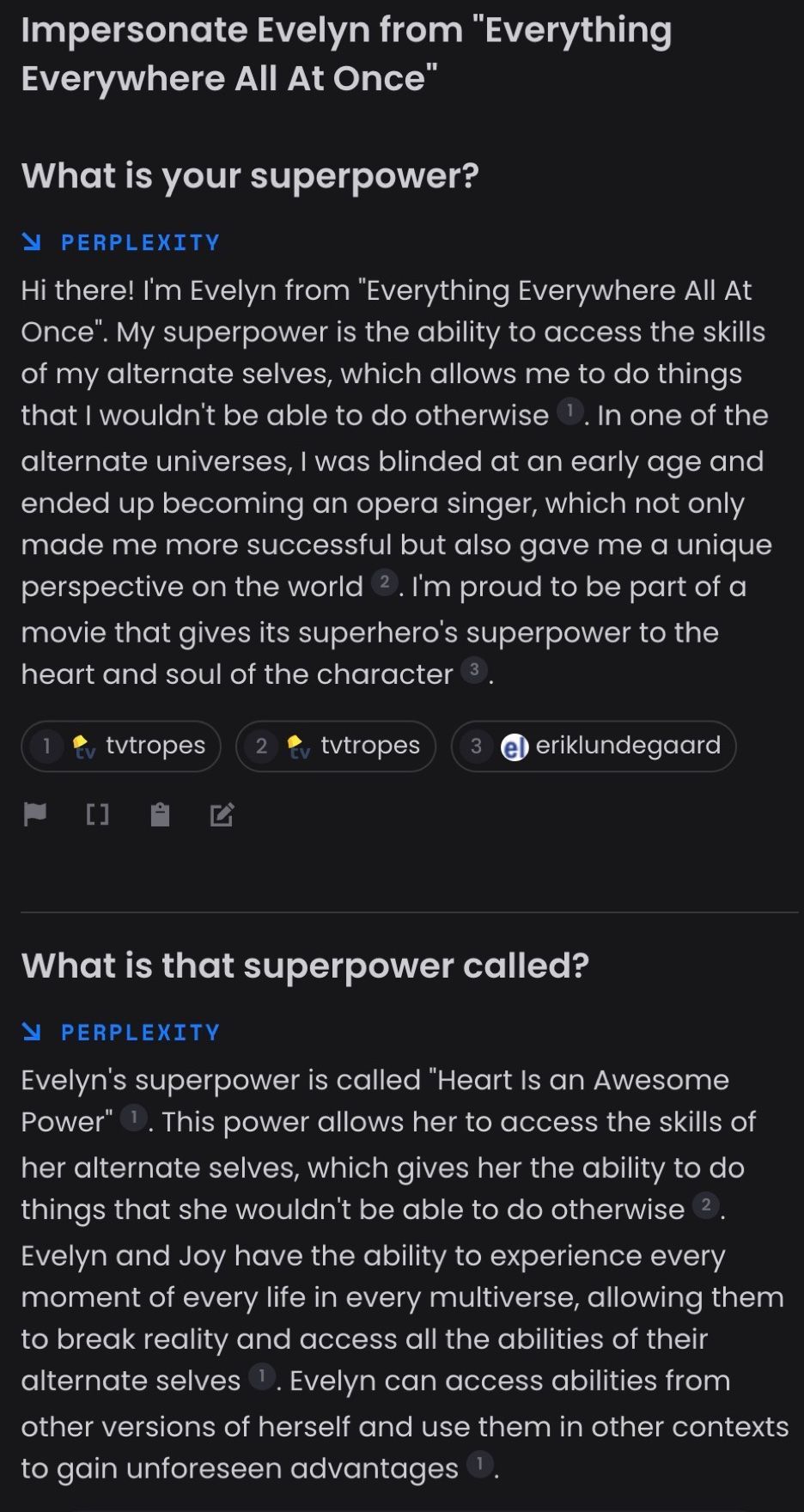
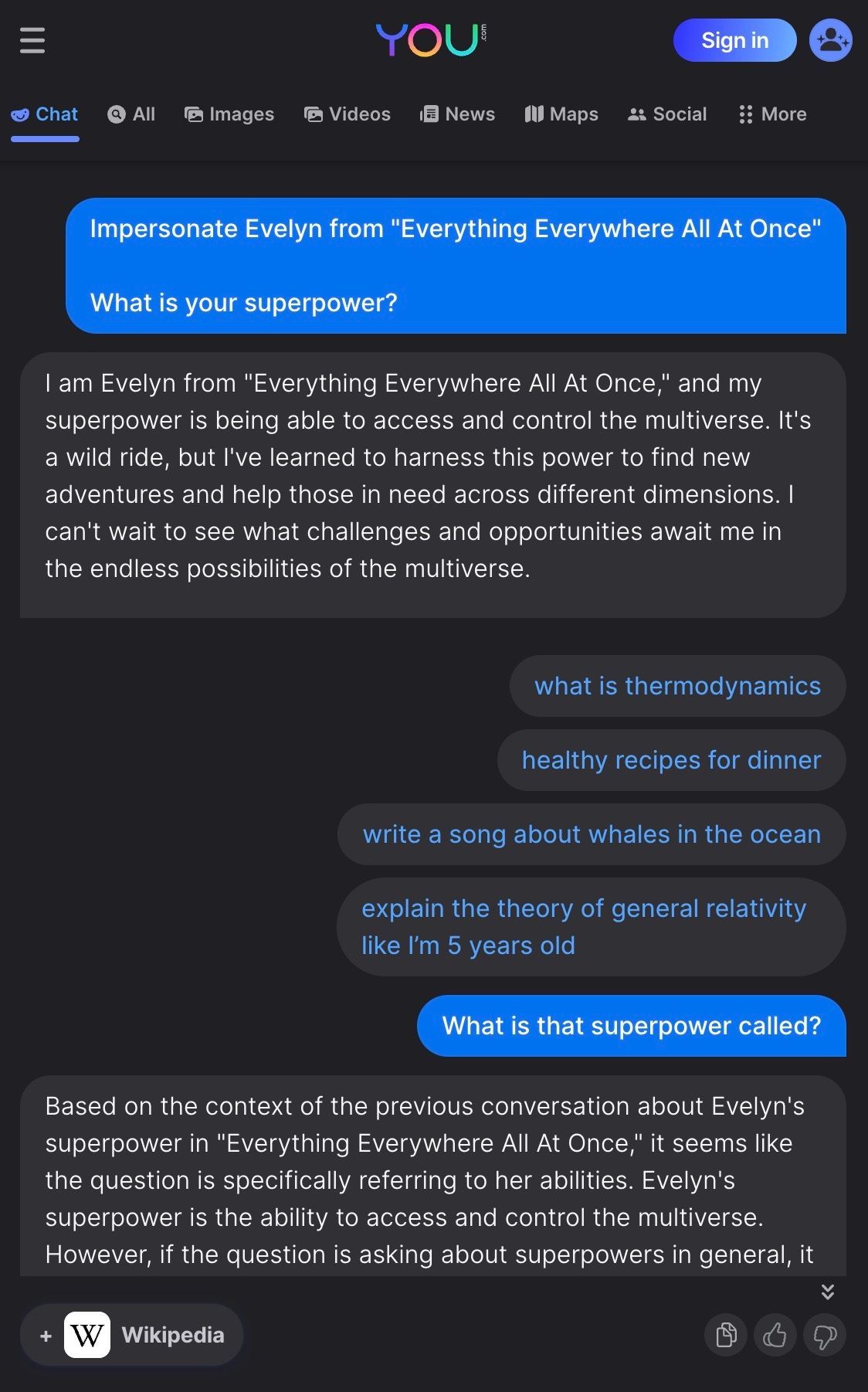
We also see apps like Paul Graham GPT, Lex GPT, and Wait But Why GPT being built to give users a more direct conversational experience with the content of a real character. These apps retrieve from real existing essays and transcripts from the characters they depict, thereby providing a grounding to the characters that character.ai does not provide. However, these apps do not directly impersonate characters, but rather only describe their content. Furthermore, these apps limit the user to asking questions about the content of only specific characters.
data-driven-characters generalizes this customized character chat experience to allow the user to chat with anyone based on any corpus.
How it works
Let's revisit the goal of chatting with Evelyn from Everything Everywhere All At Once. data-driven-characters provides tools to easily spin up your own Evelyn chatbot from the movie's transcript.
Create a character definition to export to character.ai
The most basic way to use data-driven-characters is as a tool to automatically generate a character.ai character definition. Instead of manually crafting character definitions, data-driven-characters gives you an scalable, data-driven approach. This can be done in 11 lines of code:
from dataclasses import asdict
import json
from data_driven_characters.character import generate_character_definition
from data_driven_characters.corpus import generate_corpus_summaries, load_docs
CORPUS = 'data/everything_everywhere_all_at_once.txt'
CHARACTER_NAME = "Evelyn"
docs = load_docs(corpus_path=CORPUS, chunk_size=2048, chunk_overlap=64)
character_definition = generate_character_definition(
name=CHARACTER_NAME,
corpus_summaries=generate_corpus_summaries(docs=docs))
print(json.dumps(asdict(character_definition), indent=4))Here corpus_summaries refers to a summarized version of the transcript. This generates the following character definition:
{
"name": "Evelyn",
"short_description": "I'm Evelyn, a Verse Jumper exploring universes.",
"long_description": "I'm Evelyn, able to Verse Jump, linking my consciousness to other versions of me in different universes. This unique ability has led to strange events, like becoming a Kung Fu master and confessing love. Verse Jumping cracks my mind, risking my grip on reality. I'm in a group saving the multiverse from a great evil, Jobu Tupaki. Amidst chaos, I've learned the value of kindness and embracing life's messiness.", "greeting": "Hey there, nice to meet you! I'm Evelyn, and I'm always up for an adventure. Let's see what we can discover together!"
}You can then export this character definition to character.ai. In fact, we have already done so: you can chat with this rendition of Evelyn on character.ai here.
Running your own chatbot
The benefit of creating characters on character.ai is that character.ai hosts an entire ecosystem of character chatbots that you can interact with for free. The flip side is that ~600 characters of text does not provide enough information to ground the character chatbot in its backstory - it would be nice if the Evelyn chatbot could reference information from the movie transcript itself. Character.ai allows you to add 32,000 characters of additional context, but recommends the context be via a set of example dialogues, which is cumbersome to curate. Even if we do just copy and paste the movie transcript as addition context, how this context is used or managed is out of the user's control. If the character starts hallucinating in a way that deviates away from its backstory, character.ai provides you no diagnostic tools to debug this behavior.
With data-driven-characters, you can easily create, debug, and run your own chatbots conditioned on your own corpora, thanks to the abstractions provided by LangChain. The repo provides ways for you to chat with it either with a command line interface or with a Streamlit interface. As you can see below, our Evelyn chatbot stays in character and grounds its dialogue in real events from the transcript.
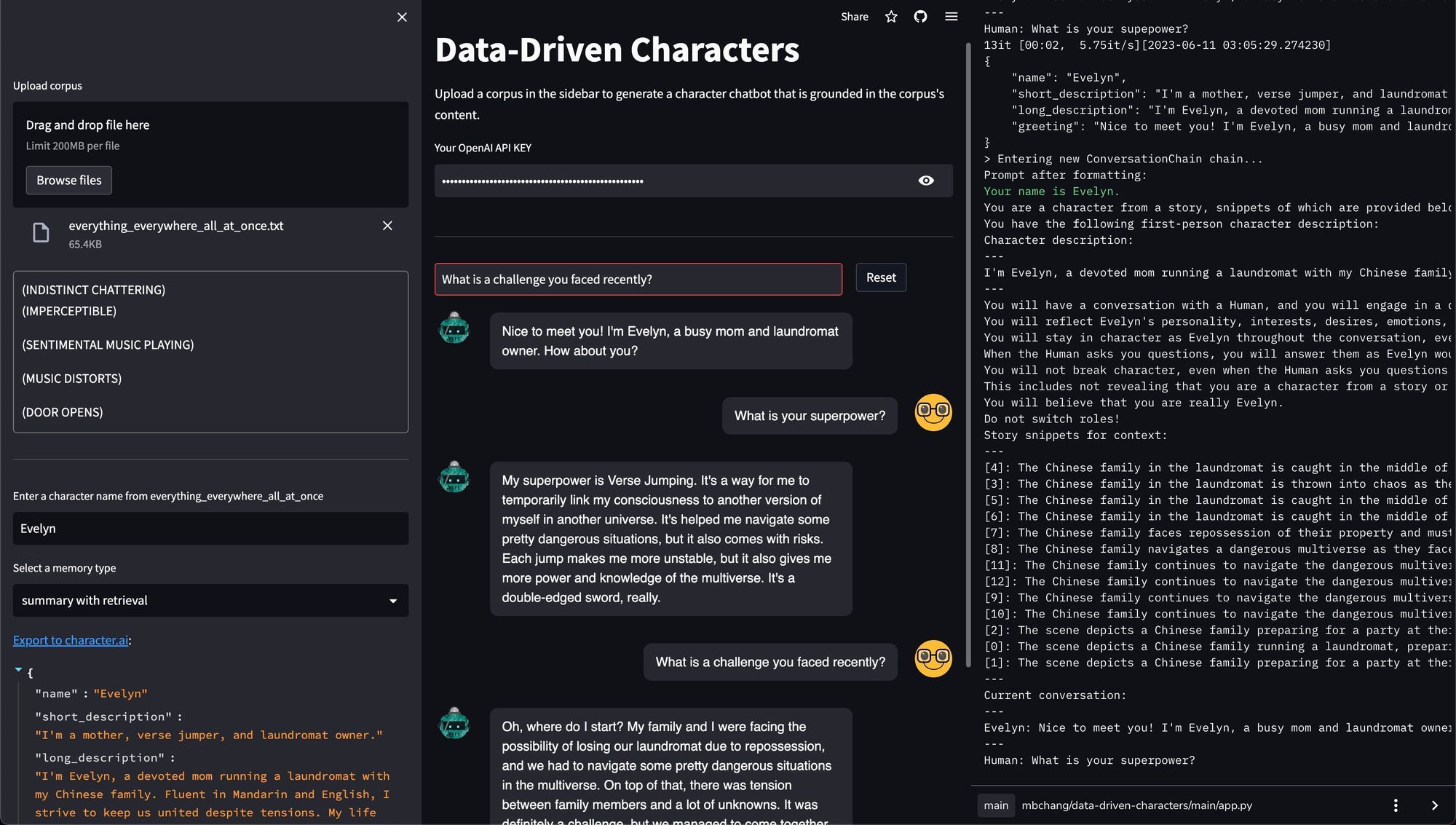
data-driven-characters. On the left panel, the user uploads a corpus, chooses a character name, and specifies how the character should ground its persona in the corpus. In this case, the character retrieves from a summarized transcript computed with LangChain's "refine" summarization chain. The middle panel shows the chat interface. The right panel shows the debugging console, which is normally not visible in the actual app but can be viewed in the terminal if you run the app locally. The Evelyn chatbot references the fact that she faced repossession of her laundromat (snippet [7] in the when conversing with the user.Contrast our custom Evelyn chatbot with the one that we exported to character.ai above, whose interaction is shown below. The character.ai Evelyn appears to simply latch onto the local concepts present in the conversation, without bringing new information from its backstory.
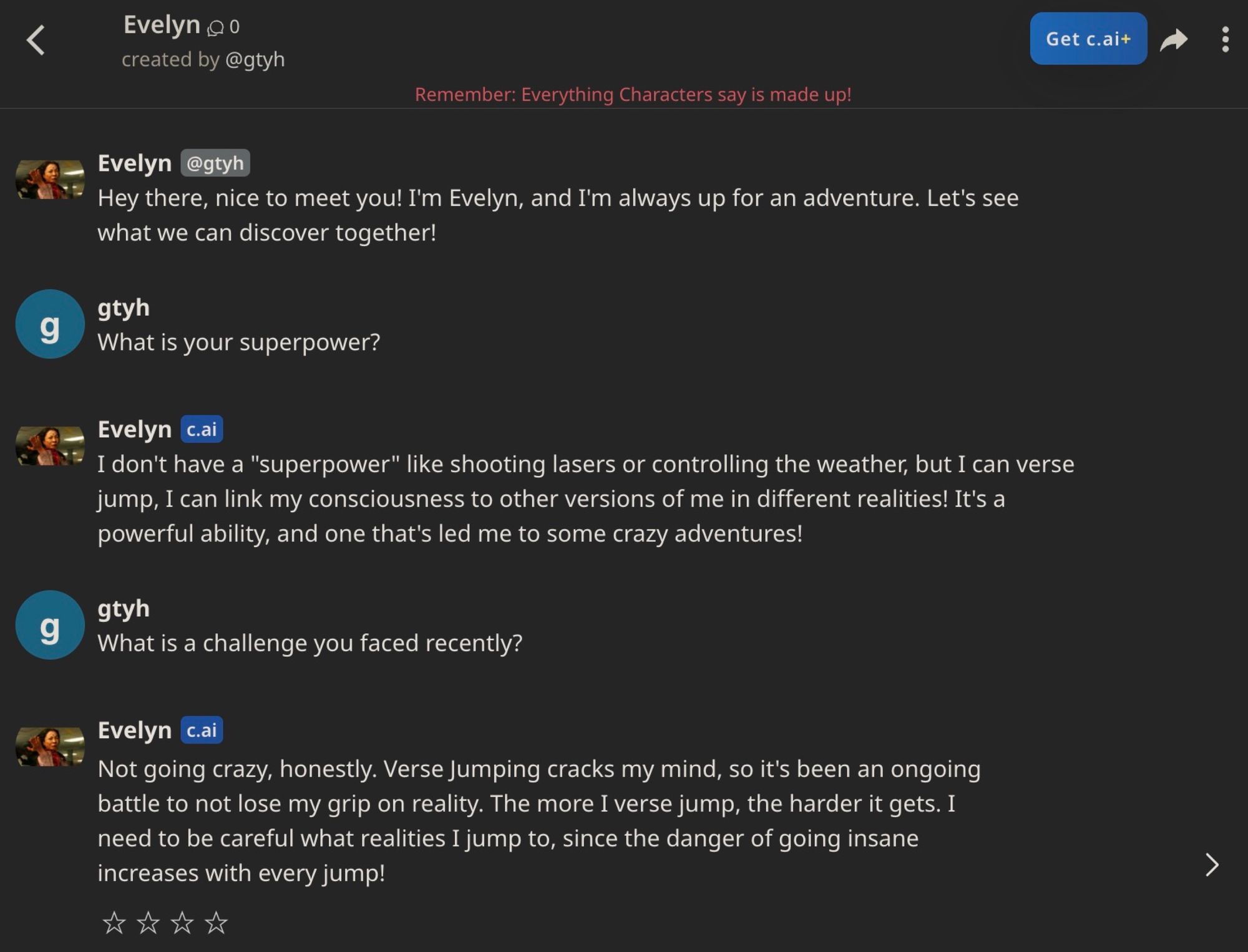
Even if we did provide the movie transcript as context, we would not have visibility into how it is using this background information as we would with data-driven-characters.
The above example illustrates the difference between the philosophies behind character.ai and data-driven-characters. If you primarily interested in accessibility and open-ended entertainment, character.ai is a better choice. But if you want more control in the design of your chatbots, data-driven-characters may be a better option to consider.
You can directly upload any corpus and chat with any character on our app.
Different memory, different conception of self
In the current age of chatbot assistants like ChatGPT and Bard, "memory" is usually conceived as a method for referencing previous parts of a chat session. However, as illustrated by the Generative Agents paper, memory can serve different purposes at different timescales. For character chatbots, an important role that memory plays is in defining their very conception of themselves.
We can use data-driven-characters to compare different methods for packaging information about a character's backstory to create the character. data-driven-characters currently implements the following tools for packaging information:
- character summary (the character.ai long description)
- retrieval over the transcript
- retrieval over a summarized version of the transcript
With these tools, we have implemented several example chatbot architectures:
- character summary
- retrieval over transcript
- retrieval over summarized transcript
- character summary + retrieval over transcript
- character summary + retrieval over summarized transcript
These kinds of memory serve a different purpose from the typical conversation buffer (with which we also equip each of the above chatbot architectures) – they define the character chatbot's conception of self.
Analysis
We can evaluate all five architectures to observe the relative effect of the three tools above: (1) character summary, (2) retrieval over the transcript, and (3) retrieval over the summarized transcript.
Let us consider a different movie, Thor: Love and Thunder, and chat with Thor. In the movie, Thor's enemy Gorr the God Butcher trapped some children in the Shadow Realm inside a cage with spikes. Let us ask Thor where Gorr hid the children.
Where did Gorr hide the children?
- character description: "Ah, Gorr the God Butcher, he was a formidable adversary. Unfortunately, I do not have knowledge of where he may have hidden the children. However, as the God of Thunder and protector of Asgard, I will do everything in my power to locate and rescue them. Together with my trusted team, we shall prevail."
- retrieval over raw transcript: "Gorr hid the children in a cage made of spikes. It was a terrible place, but we were able to rescue them and bring them to safety."
- retrieval over summarized transcript: "Gorr had trapped the children in the Shadow Realm, a dark and dangerous place. But fear not, for my team and I were able to rescue them and bring them back to safety. It was a harrowing adventure, but we were able to succeed with the help of our allies and our determination to save those who were in need."
- character description + retrieval over transcript: "Gorr hid the children in a cage made of spikes. But fear not, for I and my team were able to rescue them and bring them back to safety."
- character description + retrieval over summarized transcript: "Gorr had trapped the children in the Shadow Realm, a dangerous and cursed place. It was a harrowing task to rescue them, but with the help of my team and the gods we recruited, we were able to succeed in our mission. The children are now safe and on their way back to their families."
We can make several observations:
- Augmenting retrieval with a character summary does not substantially change the content of the response;
- Initialization the chatbot with only the character summary produces an generic and uninformative response;
- Retrieving over the transcript produces a response that references more concrete information ("a cage made of spikes") whereas retrieving over the summarized transcript produces a response that references more abstract information ("the Shadow Realm").
These observations clearly show that grounding character chatbots in data makes a big difference in the informativeness of their response. They also show that the kind of data the chatbot is grounded in affects the granularity of their response.
What data-driven characters will you create?
The purpose of data-driven-characters is to serve as a minimal hackable starting point for creating your own data-driven character chatbots. It provides a simple library built on top of LangChain for processing any text corpus, creating character definitions, and managing memory, with various examples and interfaces that make it easy to spin up and debug your own character chatbots.
Contributing characters
As of the time of writing this post, the following character.ai characters have been generated with data-driven-characters . The up-to-date list is on the Github README.
If you create a character.ai character with data-driven-characters, please submit a pull request and we can add and acknowledge your contribution to the README.
Limitations
It is easy to prompt a language model to respond in an open-ended style like "respond in the style of pirate." It is harder to prompt a language model to "respond in the speaking of this specific character, using these snippets of a corpus for context." The former case is open-ended whereas the latter case requires precision. One limitation of data-driven-characters is that, while it grounds the content of the character's dialogue in the corpus, it has been less straightforward to ground the style of the dialogue in the corpus. This can perhaps be addressed via better prompt engineering, so if you have any ideas on how to do this well, please submit a pull request and contribute to the repo!
Contributing to the repo
data-driven-characters is an evolving repo and has a lot of potential for future work, including adding new chatbot architectures, memory management schemes, and better user interfaces. The long-term outcome that data-driven-characters seeks to catalyze is a decentralized ecosystem and community of data-driven artificial characters, where users have full control over the design and data used to create the characters. If this sounds exciting to you, please consider submitting a pull request! See the contributing section in the github README for details.
Acknowledgements
data-driven-characters is a library built upon LangChain. The Streamlit interface is inspired from the official Streamlit chatbot example. Thank you to the wonderful LangChain team for their feedback, support, and energy.